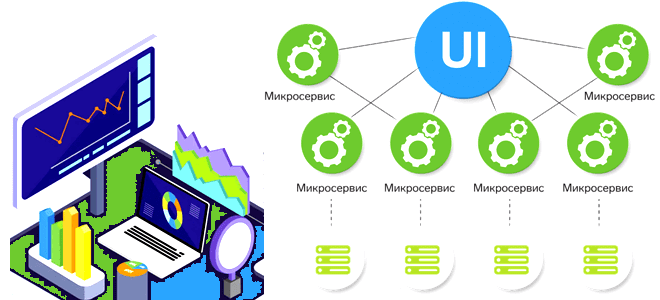
Сегодня разберем проблемы микросервисной архитектуры для платформ данных и способы их решения, а также вспомним 5 популярных шаблонов развертывания, которые могут смягчить риски от внедрения новых версий многокомпонентной системы.
Проблемы микросервисной архитектуры для платформы данных и способы их решения
При всех плюсах микросервисной архитектуры (автономность, гибкость, масштабируемость, простота развертывания, технологическая свобода, возможность повторного использования и отказоустойчивость), они имеют ряд сложностей при работе с данными. Прежде всего, это разрывы в функциональной совместимости. Каждый технический компонент/инструмент, добавленный в архитектуру, должен успешно взаимодействовать с остальной частью стека, что не всегда возможно из-за огромного разнообразия технологий.
Еще одной сложностью становится размывание ответственности за данные, которые создаются и меняются несколькими сервисами, что приводит к падению качества данных и необходимости внедрения дополнительных инструментов его контроля. В этом же контексте следует упомянуть рост накладных расходов на операционное сопровождение процессов разработки и эксплуатации платформ данных. Получение актуальной информации о производительности и надежности всех компонентов стека является трудной инженерной задачей и наиболее частым техническим долгом для дата-платформ. Недостаток прозрачности приводит к быстрому росту затрат и падению производительности.
Степень хаоса увеличивается из-за отсутствия ясности в отношении прав собственности и происхождения данных вместе со стремлением демократизировать их, предоставляя пользователям возможности самообслуживания с помощью нескольких инструментов. Владельцы платформы данных имеют ограниченный контроль над ее компонентами и поддерживают только то, что было непосредственно разработано управляемой командой. В результате этого некоторые данные и элементы конвейера их обработки становятся неконтролируемыми, что приводит к ухудшению всей аналитической платформы.
Решить эти проблемы поможет целый комплекс мероприятий и набор технических компонентов:
- служба реестра задач. Задача — это отдельная независимая единица работы, например, модуль извлечения данных из внешнего источника, их преобразование или загрузка в постоянное хранилище. Цель службы регистрации задач в том, чтобы предоставить интерфейс самообслуживания для всех типов задач, которые необходимо зарегистрировать. Все зарегистрированные задачи будут в компетенции платформы, но связанные данные и их определение принадлежат запрашивающей стороне. Любые недекларированные выходные данные не существуют для платформы и не будут доступны для обнаружения и использования через платформу.
- служба метаданных задачи. Владелец задачи предоставить сведения о схеме задействованных наборов данных вручную или запросить автоматическое определение схемы. Таким образом, эта служба метаданных является реестром схем как для текущих потоков, так и для постоянных наборов данных, дополнительно фиксирует метаданные и предоставляет их другим сервисам.
- служба происхождения. Каждая задача должна публиковать информацию о своих источниках и целях (входах и выходах), а также дополнительно предоставлять информацию о выполненных преобразованиях. Сервис происхождения (lineage) обеспечивает отслеживаемость через службу обнаружения задач и интегрируется со службами сертификации данных, чтобы расширить возможности определения происхождения неудачных проверок.
- Служба оркестровки. Каждая задача может публиковать восходящие зависимости, которые динамически строя граф конвейера данных и помогают определить порядок выполнения задач на основе событий. Эти зависимости должны автоматически и разумно извлекаться и управляться на основе метаданных и происхождения, чтобы уменьшить запутанность при определении зависимостей в сложном конвейере. Служба оркестровки инициирует и отслеживает выполнение задачи, а также запрашивает у службы управления инфраструктурой выделение ресурсов для задачи.
- Служба управления инфраструктурой предоставляет и выделяет нужное количество ресурсов для выполнения задачи, постоянно отслеживает потребление ресурсов и показатели использования, а также позволяет проводить эксперименты для оценки и оптимизации производительности. Еще этот сервис публикует подробные логи на уровне приложений и инфраструктуры для мониторинга системных метрик.
- Служба управления доступом — внешнее приложение, обеспечивающее управление профилями доступа пользователей и внешних сервисов к данным. Она интегрируется со службами метаданных, чтобы точно определить элементы управления доступом ко всем данным и ресурсам дата-платформы, а также реализует политики безопасности.
- Служба безопасности, которая хранит ключи данных шифрования, токены/секреты и управляет ими, а также отвечает на выдачу временных учетных данных на основе модели разрешений, определенной в службе управления доступом.
- Служба мониторинга, которая предоставляет API-интерфейсы для приложений и систем и других служб для интеграции и непрерывной публикации метрик и журналов. Также этот сервис отвечает за аудит задач, доступ к данным через запросы и API, обнаруживает и сообщает об уязвимостях, узких местах производительности, сбоях/отключениях и нарушениях SLA, публикуя эту информацию в службе обнаружения данных.
- служба сертификации данных сертифицирует наборы данных на предмет точности метаданных и классификации, качества и актуальности данных. Сертификация интегрируется с метаданными, службами происхождения и детерминировано применяет проверки качества данных и соответствия нормативным требованиям. Результаты публикуются для наблюдения, чтобы генерировать действия и обнаруживать данные для улучшения видимости. Кроме того, оркестрация может запросить информацию о сертификации, чтобы решить, следует ли вызывать или приостанавливать выполнение нижестоящей задачи.
- Служба обнаружения данных представляет собой пользовательское внешнее приложение с функциями изучения доступных наборов или продуктов данных. Эта служба будет взаимодействовать со службами управления происхождением, метаданными, доступом для предоставления подробной документации по бизнес-определениям, происхождению данных, статусу сертификации и пользовательским запросам. Также она может предоставлять пользователям возможности просматривать наборы данных и запрашивать доступ к ним, когда они используются в качестве источника или входных данных для задач.
- Служба запросов — абстракция или уровень обслуживания поверх базового механизма выполнения SQL-запросов, которая направляет запросы в зависимости от профиля инициатора запроса, его сложности, приоритета и других характеристик для обеспечения эффективного распределения ресурсов и управления ими. Этот сервис интегрируется со службами управления пользователями и API метаданных для применения элементов управления безопасностью на основе определенных спецификаций.
- Служба подписки на данные обеспечивает интеграцию со службами, внешними по отношению к платформе данных, а также обеспечивает предоставление продуктов данных через API, Pub/Sub или в автономном режиме доставки. Еще этот сервис управляет подписками пользователей и
Таким образом, реализация микросервисной архитектуры для платформы данных предполагает еще целый ряд микросервисов для управления этой экосистемой. На практике разработка и развертывание целого набора приложений обычно не выполняются в один момент, что также соответствует принципу микросервисной архитектуры о независимости развертывания. Поэтому далее рассмотрим 5 шаблонов развертывания микросервисов, которые могут быть применены для платформы данных и элементов, поддерживающих ее целостность и управляемость.
5 шаблонов развертывания микросервисов для конвейеров и платформ данных
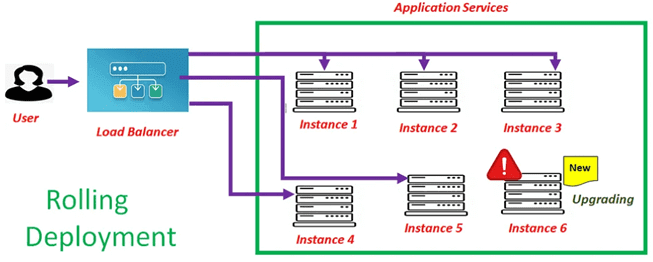
Начнем с наиболее простого последовательного развертывания, которое предполагает отключение одного экземпляра сервера за балансировщиком нагрузки для запуска нового кода. В это время балансировщик нагрузки не будет отправлять запросы на этот конкретный экземпляр сервера. После завершения развертывания и запуска нового кода балансировщик нагрузки снова начнет отправлять запросы на этот сервер. Если обработка запроса прошла успешно, процедура повторяется для других серверов, иначе выполняется откат изменения на конкретном сервере.
Главной проблемой этого шаблона развертывания является риск сбоя всей системы, если при размещении нового кода на нескольких серверах, он дает сбой, и балансировщик нагрузки перенаправляет все запросы на оставшиеся серверы.
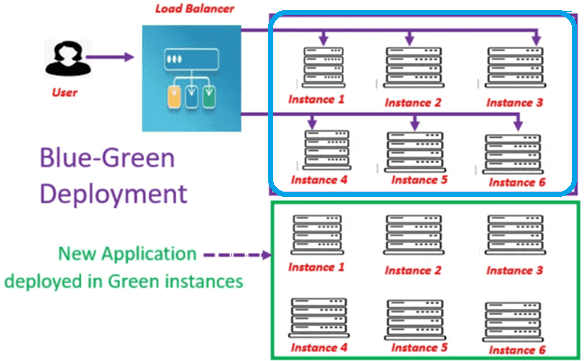
В сине-зеленом развертывании отсутствуют недостатки последовательного, а потому оно подходит для высоконагруженных ETL-процессов, о чем мы писали здесь. В этом случае новое приложение развертывается в новом наборе серверов, сохраняя старый набор серверов как есть. Трафик приложений будет по-прежнему обслуживаться с серверов прежнего (синего) региона. Если тестирование с новыми (зелеными) серверами прошло успешно, то отключаются только старые серверы и балансировщик нагрузки перенаправляет трафик на новый набор серверов. Побочным эффектом этого шаблона развертывания становится рост затрат, связанных с добавлением дополнительных серверов в облаке.
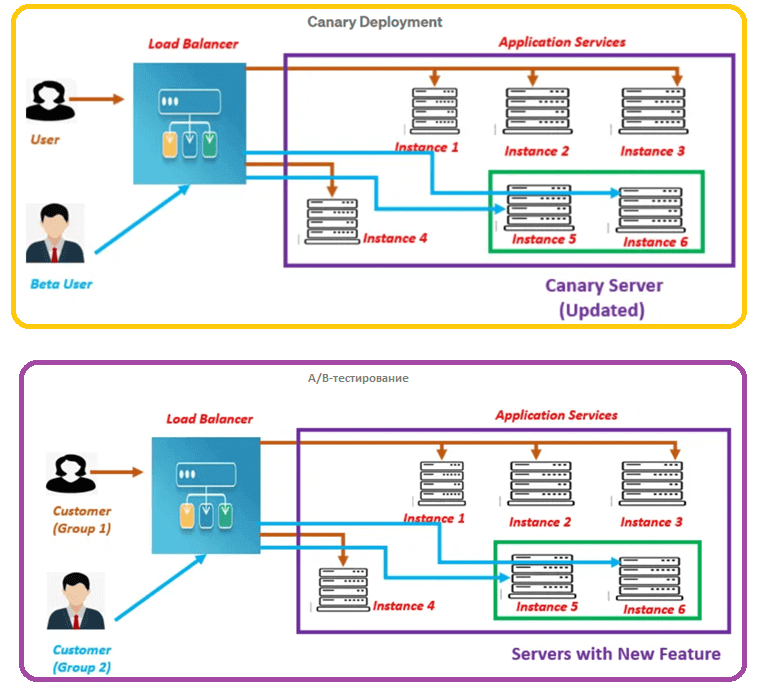
Канареечное развертывание немного похоже на сине-зеленое: здесь также на синем (прежнем) наборе серверов размещается стабильная версия системы, доступная пользователям, а новый код разворачивается на других (зеленых) серверах. Когда тестирование окончено, эти бэкенды меняются местами. После этого основным становится зеленый набор серверов, а на синем можно тестировать следующую версию системы. Пока на синих серверах остается предыдущая версия, возможен откат на прежнюю версию.
В этом шаблоне развертывания новый код развертывается в некоторых серверах, куда балансировщик нагрузки перенаправляет часть пользователей. Если производительность и другие характеристики нового кода не хуже старого, синие экземпляры заменяются зелеными. Иначе выполняется откат к прежней версии. Таким образом, при сине-зеленом развертывании весь пользовательский трафик одномоментно перераспределяется с прежней версии на новую, а при канареечном переключение происходит постепенно. Можно рассматривать канареечное развертывание в качестве безопасного способа тестирования нового кода без простоев в условиях производственной среды, но на небольшом количестве пользователей. Отсюда и название: канареечное, именно так шахтеры узнавали об опасных веществах в воздухе. Отправляясь в шахту, шахтеры брали с собой этих птиц, которые пели в воздухе, пригодном для нормального дыхания, но замолкали из-за потери сознания и смерти в случае роста концентрации токсичных газов. Заметив это, люди скорее покидали шахту. Возвращаясь к рассматриваемым DevOps-практикам, здесь в роли канареек выступают пользователи. Канареечные релизы сокращают TTM (Time To Market, время выхода на рынок, доставки ценности потребителям) и минимизируют ущерб, если в новой версии что-то пошло не так.
Главным преимуществом канареечного развертывания является возможность отслеживать изменения в течение нужного времени (несколько часов, дней или недель), чтобы принять объективное решение о переходе на новую версию системы или откате к прежнему коду.
A/B-тестирование похоже на канареечное развертывание, но оно используется для валидации новых функций системы в производственной среде с очень ограниченным количеством пользователей. После завершения тестирования экземпляры возвращаются к исходной версии ПО.
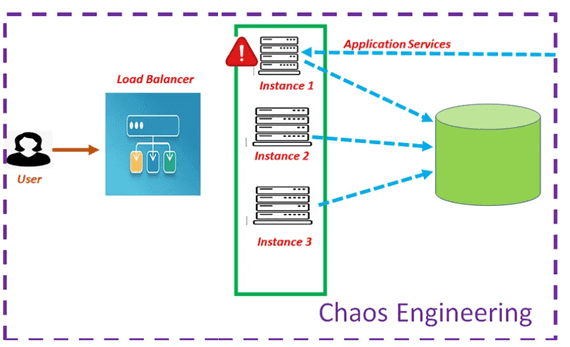
Наконец, для тестирования и обеспечения отказоустойчивости Netflix еще в 2010 году разработал инструмент под названием Chaos Monkey, который позволяет имитировать различные варианты сбоев, чтобы подготовить и внедрить меры их предупреждения. В частности, инструмент Latency Monkey вводит искусственные задержки в RESTful-соединении клиент-сервер, что позволяет имитировать недоступность сервиса без его фактического отключения, чтобы организовать меры борьбы с таким отказом. Chaos Monkey может вызвать один конкретный тип отказа и случайным образом отключает экземпляры, чтобы имитировать сбой.
Узнайте больше подробностей по проектированию и поддержке современных дата-архитектур в проектах аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

