 1006
1006 
Что общего у Kafka Streams и Consumer API, чем они отличаются и что выбирать для практического использования: краткое руководство для разработчика приложений потоковой обработки событий.
Возможности и ограничения Kafka Streams и Consumer API
Поскольку Apache Kafka как огромная экосистема со множеством компонентов для потоковой передачи событий, обилие и разнообразие этих инструментов может слегка запутать начинающего разработчика. В частности, API потребителя предоставляет основные функции для обработки сообщений на стороне приложения-потребителя. С другой стороны, клиентская библиотека Kafka Streams также обеспечивает потоковую обработку событий в реальном времени, действуя поверх клиента-потребителя. Как и Consumer API, Kafka Streams позволяет приложениям-потребителям обрабатывать сообщения из топиков. Consumer API поддерживает следующие возможности:
- разделение ответственности между потребителями и продюсерами;
- одиночная обработка;
- поддержка пакетной обработки;
- работа с несколькими кластерами.
Из ограничений Consumer API, которые можно рассматривать как недостатки, наиболее важными с точки зрения разработчика можно отметить следующие:
- только stateless-обработка — клиент не сохраняет предыдущее состояние и оценивает каждую запись в потоке отдельно;
- для создания приложения требуется написать много исходного кода;
- отсутствие многопоточной обработки или параллелизма.
Kafka Streams значительно упрощает обработку потоков из топиков. Будучи построенной на основе клиентских библиотек платформы потоковой передачи событий, она обеспечивает параллелизм данных, распределенную координацию, отказоустойчивость и масштабируемость. В этом случае приложением потоковой обработки становится любая программа, использующая библиотеку и определяющая свою вычислительную логику через одну или несколько топологий процессора. Это приложение потоковой обработки не работает внутри брокера, а запускается в отдельном экземпляре JVM или полностью в отдельном кластере.
Топология процессора определяет вычислительную логику обработки данных, которую должно выполнять приложение потоковой обработки, в виде графа потоковых процессоров (узлов), соединенных потоками (ребрами). Разработчик может определять топологию с помощью низкоуровневого императивного API-интерфейса процессора или с помощью декларативного DSL-языка.
Потоковый процессор представляет собой шаг обработки в топологии для преобразования данных. Стандартные операции, такие как сопоставление или фильтрация, объединение и агрегирование, являются примерами потоковых процессоров, которые доступны в Kafka Streams по умолчанию. Потоковый процессор получает по одной входной записи от своих вышестоящих процессоров в топологии, применяет к ней свою операцию и впоследствии может создать одну или несколько выходных записей для своих нижестоящих процессоров.
API-интерфейс процессора Kafka Streams обеспечивает большую гибкость по сравнению с DSL, но требует больше ручного кодирования. Здесь можно определить и подключить пользовательские процессоры, а также напрямую взаимодействовать с хранилищами состояний.
Библиотека работает с сообщениями как с неограниченным, непрерывным потоком записей в реальном времени, используя потоковые разделы и задачи как логические единицы для хранения и транспортировки сообщений. Библиотека предоставляет следующие возможности:
- единый поток для потребления и производства сообщений;
- сложная обработка событий;
- поддержка как stateless, так и stateful-операций за счет хранилища состояний, используемых для хранения и запроса данных, поступающих из топиков;
- для разработки приложения требуется написать намного меньше исходного кода по сравнению с Consumer API ;
- поддержка многопоточности для распараллеливания обработки внутри экземпляра приложения.
Однако, Kafka Streams не поддерживает пакетную обработку и взаимодействуйте только с одним кластером. API библиотеки взаимодействует с кластером, но не работает непосредственно поверх него.
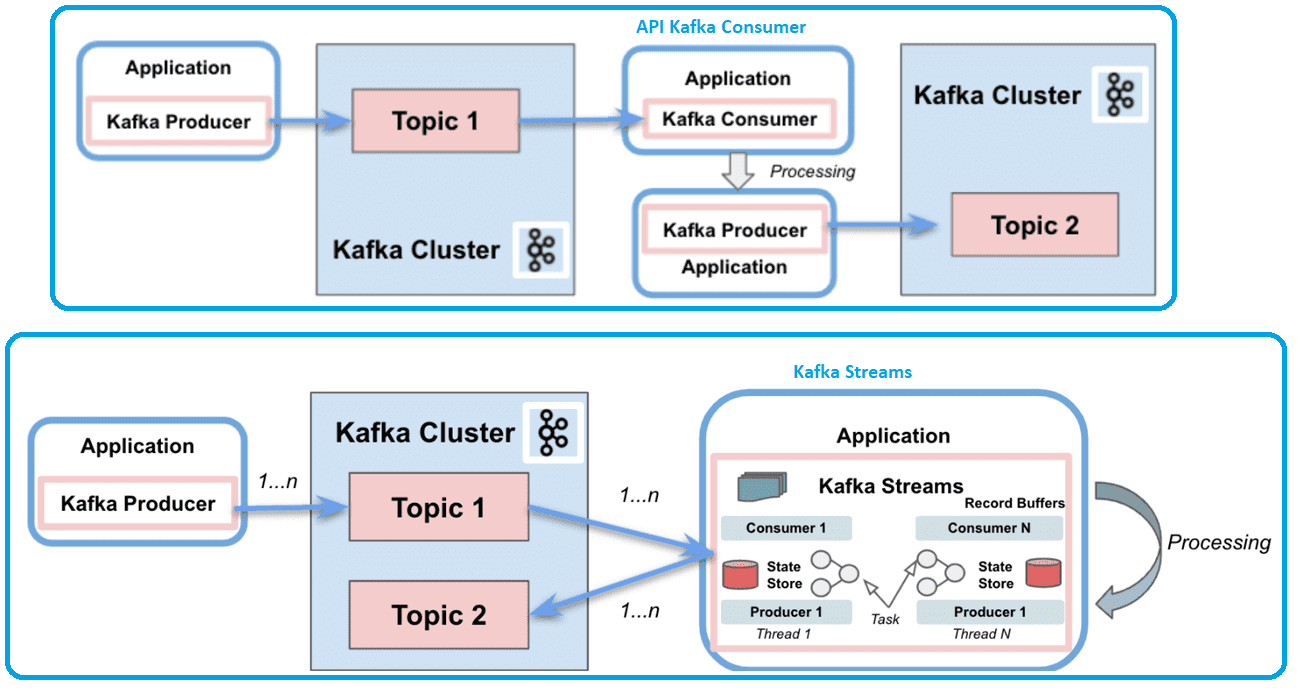
Kafka Streams поддерживает потоки (KStreams) и таблицы (KTables), которые можно преобразовывать между собой. Таблицы представляют собой набор изменяющихся фактов: каждое новое событие перезаписывает старое, а потоки представляют собой набор неизменных фактов. KStream обрабатывает поток записей, полный поток данных из топика. KTable управляет потоком журнала изменений с последним состоянием ключа, сохраняя состояние за счет сбора данных из потоков. Каждая запись данных представляет собой обновление.
Начиная с версии 0.11.0, Kafka Streams, как и Consumer API, поддерживает семантику строго однократной доставки сообщений (exactly once). Чтобы настроить EOS в Kafka Streams, надо включить следующее свойство:
streamsConfiguration.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG, StreamsConfig.EXACTLY_ONCE);
Также библиотека Streams поддерживает интерактивные запросы, которые позволяют просматривать состояние приложения в распределенных средах. Это означает возможность извлечения информации из локальных хранилищ, а также из удаленных хранилищ в нескольких экземплярах. По сути, чтобы получить полное состояние приложения, выполняется сборка и группировка всех хранилищ. Таким образом, Kafka Streams упрощает как stateless, так и stateful-операции обработки данных при получении сообщений из топиков Kafka.
Сравнение API
Подводя итог рассматриваемым API, прежде всего, отметим, что можно создать приложение-потребитель средствами Consumer API без использования Kafka Streams. Но это потребует больше усилий. Оба API позволяют приложениям-потребителям получать сообщения из топиков Kafka и обрабатывать их. Однако, Consumer API разделяет ответственность между приложениями потребителями и продюсерами, тогда как клиентская библиотека Kafka Streams имеет единый поток для потребления и производства событий. Она может выполнять сложную обработку, но не поддерживает пакетную обработку, тогда как в API Kafka Consumer все наоборот.
Наконец, Kafka Streams поддерживает как statless-, так и stateful-операции, а Consumer API поддерживает только вычисления без сохранения состояния. Однако, Consumer API может работать с несколькими кластерами распределенной платформы потоковой передачи событий, тогда как Kafka Streams позволяет взаимодействовать только с одним.
Резюмируем отличия API в виде таблицы.
|
Критерий |
Kafka Consumer |
Kafka Streams |
|
Назначение |
API для создания потоковых приложений, обрабатывающих данные из топиков Kafka |
API для создания потоковых приложений, обрабатывающих данные из топиков Kafka |
|
Разделение производства и потребления сообщений |
Да, Consumer API используется только для исходного кода разработки приложений-потребителей |
Позволяет не разделять приложения на потребителей и продюсеров, поддерживая единый поток для потребления и производства сообщений |
|
поддержка сложных вычислений (операций с событиями) |
да |
да |
|
stateless-операции |
да |
да |
|
stateful-операции |
нет |
да |
|
пакетная обработка |
да |
нет |
|
Объем и сложность разработки исходного кода |
Большой объем, большая сложность |
Объем кода намного меньше и он проще |
|
поддержка многопоточности и параллелизма |
нет |
да, распараллеливание обработки внутри экземпляра приложения |
|
количество кластеров Kafka, с которыми можно взаимодействовать |
много |
1 |
Таким образом, при выборе между Kafka Streams и Consumer API следует принимать во внимание количество кластеров, с которыми можно взаимодействовать, а также необходимость пакетной обработки, многопоточности и параллелизма. Именно эти критерии являются решающими факторами выбора, т.к. по остальным сравниваемые API очень похожи и отличаются только субъективным восприятием разработчика, использующего их.
Если нужно распараллеливание потоковой stateful-обработки внутри экземпляра приложения в пределах одного кластера без разделения на производство и потребление событий, клиентская библиотека Kafka Streams будет отличным выбором. Если же требуется потреблять сообщения из нескольких кластеров без необходимости их распараллеливания и обработки с сохранением состояния, следует использовать Consumer API.
Читайте в нашей новой статье про сходства и отличия Kafka Streams и ksqlDB. А здесь вы узнаете, почему нельзя соединить потоки KStreams с разным числом разделов, и как это сделать без изменения конфигурации топика.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Администрирование кластера Kafka
- Apache Kafka для инженеров данных
- Администрирование Arenadata Streaming Kafka
Источники

