 465
465 
Содержание
Вчера мы разбирали работу приложения-продюсера и строили UML-диаграмму последовательности. Сегодня рассмотрим, какие системные вызовы происходят при потреблении сообщений из Apache Kafka, при чем здесь группы потребителей и фиксация смещений.
Как работает потребитель Kafka
Аналогично разработке приложения-продюсера, при написании кода потребителя, который считывает данные из топика Apache Kafka, используются методы специальных библиотек, таких как kafka-python и пр. Например, в следующем участке кода, который можно запустить в нескольких ячейках Google Colab, устанавливаются необходимые библиотеки и импортируются модули:
####################ячейка в Google Colab №1 - установка и импорт библиотек############################ #установка библиотек !pip install kafka-python #импорт модулей import json from kafka import KafkaConsumer
Далее создадим экземпляр класса потребителя, задав параметры подключения к инстансу Kafka, развернутого в облачной платформе Upstash. О том, как создать свой инстанс Kafka в Upstash, а также написать свой Python-продюсер и потребитель, я подробно рассказывала в статье блога нашей Школы прикладного бизнес-анализа.
####################################ячейка в Google Colab №2 - потребление из Kafka########################################## #объявление потребителя Kafka consumer = KafkaConsumer( bootstrap_servers=['........здесь взять название своего сервера.upstash.io:9092'], sasl_mechanism='SCRAM-SHA-256', security_protocol='SASL_SSL', sasl_plain_username='.........здесь имя пользователя, взятое из upstash', sasl_plain_password='..........здесь пароль для этого пользователя', group_id='1', auto_offset_reset='earliest', enable_auto_commit=True )
Наиболее важными свойствами в конфигурации созданного экземпляра потребителя являются следующие:
- servers — первые серверы Kafka, с которыми потребитель должен связаться для получения конфигурации кластера. В конфигурации bootstrap_servers задается набор сокетов узлов кластера, т.е. их IP-адреса с номерами портов, обычно равных 9092. При развертывании облачного инстанса в Upstash список серверов Kafka задается в виде виртуального адреса хоста, например, merry-perry-kafka.upstash.io:9092.
- id — идентификатор группы потребителей. Если в одной группе будет несколько потребителей с одинаковым group.id, каждый раздел будет потребляется только одним приложением-потребителем. Поэтому наибольшая степень параллелизма группы потребителей достигается, когда в топике нет разделов. Чтобы приложения-потребители не зависели друг от друга, каждый из них должен иметь уникальное значение group.id. Подробнее об этом мы писали здесь и здесь. Если имя группы потребителей, к которой нужно присоединиться для динамического назначения разделов и использовать для выборки и фиксации смещений, не задано то разделы будут назначаться автоматически через координатора группы, а фиксации смещения будут отключены.
- auto_offset_reset – политика сброса смещений при ошибках OffsetOutOfRange: самое раннее смещение (earliest, как в случае рассматриваемого примера) переместится к самому старому доступному сообщению, а последнее (latest) переместится к самому последнему. Любое другое значение вызовет исключение. По умолчанию значение этого параметра равно latest.
- enable_auto_commit – автоматическая фиксация смещения потребителя в фоновом режиме.
Потребитель поддерживает TCP-соединения с необходимыми брокерами для получения данных. Если не закрыть потребитель после использования, эти соединения будут протекать. Потребитель не является потокобезопасным. Подробнее о том, как клиенты Kafka общаются с серверами, мы писали здесь.
Брокеры Kafka используют сетевые потоки (Network Thread) для обработки клиентских запросов. Входящие запросы помещаются в очередь запросов, откуда потоки ввода-вывода принимают их и обрабатывают. После обработки запроса ответ помещается во внутреннюю очередь ответов, откуда сетевой поток забирает его и отправляет ответ обратно клиенту. Общий для всего кластера параметр num.network.threads определяет количество потоков, используемых для обработки сетевых запросов, т.е. для получения запросов и отправки ответов. Задается на основе количества производителей, потребителей и сборщиков реплик. Параметр queued.max.requests определяет, сколько запросов разрешено в очереди запросов, прежде чем блокировать сетевые потоки, а num.io.threads указывает количество потоков, которые брокер использует для обработки запросов из очереди запросов, включая дисковый ввод-вывод.
Kafka поддерживает числовое смещение (offset) для каждой записи в разделе, которое действует как уникальный идентификатор записи в этом разделе, а также обозначает положение потребителя в разделе. Например, потребитель, находящийся в позиции 5, использовал записи со смещением от 0 до 4 и затем получит запись со смещением 5. На самом деле есть два понятия позиции потребителя:
- позиция потребителя дает смещение следующей записи, которая будет выдана. Оно будет на единицу больше, чем наибольшее смещение, которое потребитель видел в этом разделе. Эта позиция автоматически инкрементируется на 1 каждый раз, когда потребитель получает сообщения в вызове опроса poll().
- зафиксированная позиция — последнее надежно сохраненное смещение, к которому вернется потребитель в случае сбоя и перезапуска процесса потребления. Потребитель может периодически автоматически фиксировать смещения, если значение конфигурации enable_auto_commit установлено в значение True, как в нашем примере. Также можно управлять этой зафиксированной позицией вручную, вызывая методы API фиксации: commitSync() и commitAsync().
Это различие дает потребителю контроль над тем, когда запись считается использованной.
Как уже было отмечено выше, Kafka использует концепцию групп потребителей, чтобы позволить пулу процессов разделить работу по потреблению и обработке записей. Эти процессы могут выполняться на одном компьютере или быть распределены по нескольким вычислительным узлам, чтобы обеспечить масштабируемость и отказоустойчивость обработки. Все экземпляры потребителей с одинаковым значением group.id, являются частью одной и той же группы потребителей.
Каждый раздел топика Kafka назначается лишь одному процессу потребления в группе потребителей, чтобы сбалансировать нагрузку. Например, если есть топик с четырьмя разделами и группа потребителей с двумя процессами, каждый процесс будет потреблять данные из двух разделов. Членство в группе потребителей поддерживается динамически: в случае сбоя процесса назначенные ему разделы будут переназначены другим потребителям в той же группе. Аналогично, если новый потребитель присоединяется к группе, разделы будут перемещены от существующих потребителей к новому. Это называется перебалансировкой группы потребителей, что мы подробно рассматривали здесь.
Концептуально можно рассматривать группу потребителей как один логический подписчик из нескольких процессов. Kafka поддерживает любое количество групп потребителей для любого топика без дублирования данных. Если перебалансировка группы происходит автоматически, потребители могут быть уведомлены через ConsumerRebalanceListener, чтобы завершить необходимую логику на уровне приложения, такую как очистка состояния, ручная фиксация смещения и пр.
Определив конфигурации потребителя, его следует подписать на нужный топик (в нашем случае это топик с названием CorpAppsTopic) и начать считывание сообщений, которые в данном случае имеют формат JSON:
#подписка потребителя на топик Kafka
consumer.subscribe(['CorpAppsTopic'])
#считывание из топика Kafka
for message in consumer:
payload=message.value.decode("utf-8")
data=json.loads(payload)
После подписки на один или несколько топиков потребитель автоматически присоединится к группе при вызове poll(), API которого предназначен для обеспечения активности потребителей. Пока опрос продолжается, т.е. метод poll(0 продолжает вызваться, потребитель остается в группе и получает сообщения из назначенных ему разделов, отправляя на сервер периодические пульсации (heartbeat-сигнал). Если потребитель выходит из строя или не может отправлять тактовые импульсы в течение периода, заданного в конфигурации timeout.ms, потребитель считывается отказавшим, а его разделы будут переназначены другим потребителям в той же группе.
Для управления поведением цикла опроса в конфигурации потребителя есть 2 параметра:
- poll.interval.ms – интервал между ожидаемыми опросами. Увеличение этого значения дает потребителю больше времени для обработки пакета записей, возвращенных вызовом poll(). Но это может задержать групповую перебалансировку, поскольку потребитель присоединится к перебалансировке только внутри вызова опроса.
- poll.records – общее количество записей, возвращаемых из одного вызова опроса. Настроив это значение, можно уменьшить интервал опроса, чтобы снизить влияние перебалансировки группы на потребление сообщений.
Таким образом, после определения потребителя Kafka и его подписки на нужные топики, запускается цикл выборки записей и работает до тех пор, пока не истечет время ожидания опроса или пока потребитель не получит записи. Последовательность действий, которые выполняются при этом без участия разработчика, выглядит следующим образом:
- сначала устанавливается самое первое подключение к кластеру Kafka, к одному из серверов из списка bootstrap.servers, чтобы получить всю топологию кластера;
- далее у случайного узла кластера запрашивается координатор группы потребителей, чтобы установить с ним соединение;
- присоединившись к группе потребителей, если она задана, потребитель отправляет heartbeat-сигнал. Если отправка этого сигнала прошла успешно, потребитель полностью инициализирован и готов к потреблению записей.
- Далее потребитель начинает считывать сообщения в цикле опроса poll() с учетом смещения, продолжая периодически отправлять heartbeat-сигналы координатору группы.
Визуализируем эту последовательность в виде UML-диаграммы.
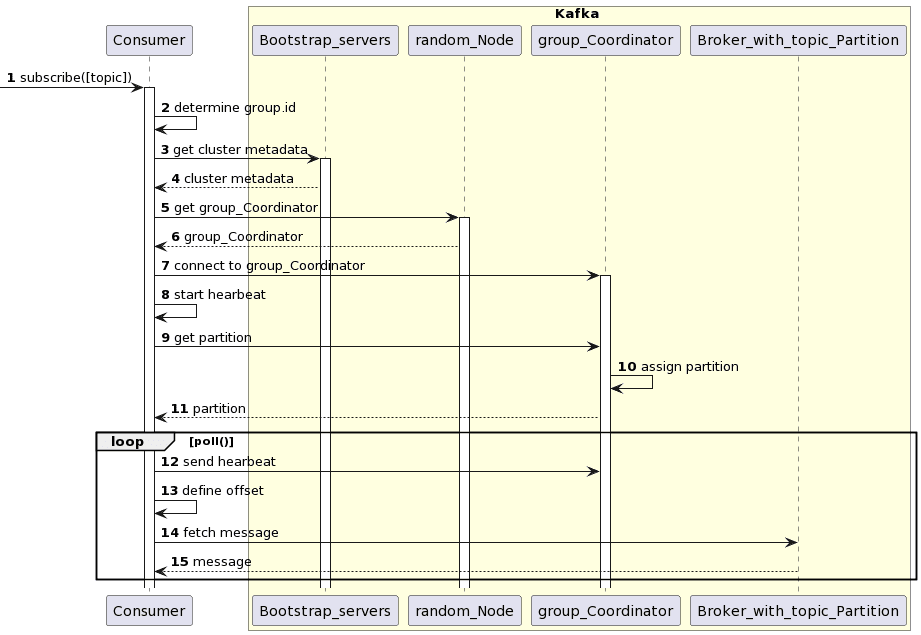
Эта UML-диаграмма последовательности была создана в PlantUML с помощью следующего скрипта:
@startuml skinparam packageStyle rectangle participant Consumer autonumber box Kafka #LightYellow participant Bootstrap_servers participant random_Node participant group_Coordinator participant Broker_with_topic_Partition -> Consumer : subscribe([topic]) activate Consumer Consumer -> Consumer : determine group.id Consumer -> Bootstrap_servers: get cluster metadata activate Bootstrap_servers Bootstrap_servers --> Consumer: cluster metadata Consumer -> random_Node : get group_Coordinator activate random_Node random_Node --> Consumer : group_Coordinator Consumer -> group_Coordinator : connect to group_Coordinator activate group_Coordinator Consumer -> Consumer : start hearbeat Consumer -> group_Coordinator : get partition group_Coordinator -> group_Coordinator: assign partition group_Coordinator --> Consumer: partition loop poll() Consumer -> group_Coordinator : send hearbeat Consumer -> Consumer : define offset Consumer -> Broker_with_topic_Partition: fetch message Broker_with_topic_Partition --> Consumer : message end end box @enduml
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Администрирование кластера Kafka
- Apache Kafka для инженеров данных
- Администрирование Arenadata Streaming Kafka
[elementor-template id=»13619″]
Источники

