901
901 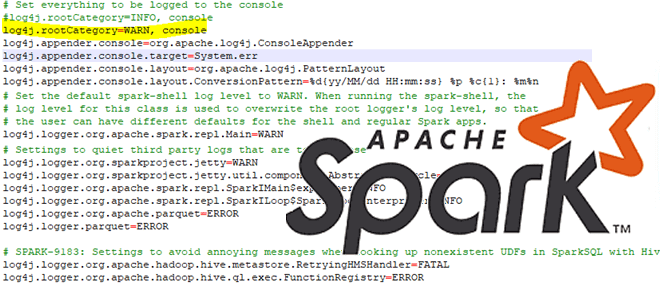
Сегодня рассмотрим особенности отладки PySpark-приложений: как Python-код исполняется в JVM, какие сложности возникают у разработчика при тестировании и исправлении ошибок в программе, написанной локально и запускаемой в кластере, а также как настроить вывод событий в лог-файл.
Запуск и выполнение PySpark-кода
Хотя Apache Spark и имеет Python API, позволяя писать код на этом популярном языке программирования, PySpark использует библиотеку Py4J для отправки и выполнения заданий. Py4J позволяет программам Python, работающим в интерпретаторе Python, динамически получать доступ к объектам Java в виртуальной машине Java. Методы вызываются так, как если бы объекты Java находились в интерпретаторе Python: к коллекциям Java можно получить доступ через стандартные методы коллекций Python. Py4J также позволяет программам Java вызывать объекты Python.
Таким образом, Py4J помогает PySpark со стороны драйвера взаимодействовать с JVM. Когда pyspark.sql.SparkSession или pyspark.SparkContext создается и инициализируется, PySpark запускает JVM для связи. На стороне исполнителя рабочие процессы Python выполняют и обрабатывают собственные функции или данные Python. Благодаря модели отложенных вычислений, они не запускаются, если приложение PySpark не требует взаимодействия между рабочими процессами Python и JVM. Фактический запуск происходит, когда необходимо обработать собственные функции или данные Python, например, при выполнении UDF-функции pandas или API PySpark RDD. Работая локально разработчик PySpark-приложения может напрямую отлаживать сторону драйвера с помощью IDE без функции удаленной отладки. При запуске PySpark-программы в кластере можно выполнять отладку удаленно с помощью удаленного отладчика с открытым исходным кодом.
Справедливости ради стоит отметить, что Python-код выполняется медленнее аналога на Scala или Java, о чем мы рассказываем в новой статье.
Логирование в Apache Spark
Поскольку для отладки очень важно логирование ошибок, разберем особенности журналирования PySpark-программ. PySpark использует библиотеку логирования Log4j, которая предлагает несколько уровней логирования, перечисляемые в порядке возрастания серьезности: TRACE, DEBUG, INFO, WARN, ERROR и FATAL. По умолчанию для PySpark установлено значение WARN. Это означает, что будут регистрироваться только те события, которые потенциально могут нарушить нормальный поток выполнения программы. При установке уровня ведения журнала на DEBUG будут регистрироваться все события, включая подробную диагностическую информацию. Это очень полезно при отладке, когда разработчик ищет причину ошибки, пытаясь понять, почему приложение ведет себя не так, как ожидается. Сделать это можно, используя следующий код:
!pip install pyspark
!apt-get install openjdk-8-jdk-headless -qq > /dev/null
#импорт модулей
from pyspark.sql import SparkSession
import pyspark
import sys
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
# Создаем объект SparkSession и устанавливаем имя приложения
spark = SparkSession.builder.appName("MySparkApp").getOrCreate()
# Установка пути к файлу лога
log_file = os.path.join(os.getcwd(), "spark.log")
sc = spark.sparkContext
# Установка уровня логирования
sc.setLogLevel("DEBUG")
# Создание логгера
logger = sc._jvm.org.apache.log4j
logger.LogManager.getRootLogger().setLevel(logger.Level.DEBUG)
logger.LogManager.getLogger("org").setLevel(logger.Level.ERROR)
logger.LogManager.getLogger("akka").setLevel(logger.Level.ERROR)
logger.LogManager.getLogger("org.apache.spark").setLevel(logger.Level.ERROR)
# Создание функции для перенаправления вывода в файл
def redirect_stdout_to_file(log_file):
class LoggerWriter:
def __init__(self, logger, level):
self.logger = logger
self.level = level
def write(self, message):
if message != "\n":
self.logger.log(self.level, message)
def flush(self):
pass
sys.stdout = LoggerWriter(logger.LogManager.getLogger("stdout"), logger.Level.INFO)
sys.stderr = LoggerWriter(logger.LogManager.getLogger("stderr"), logger.Level.ERROR)
# Перенаправление вывода в файл
redirect_stdout_to_file(log_file)
Этот код создает объект SparkSession с именем приложения «MySparkApp», устанавливает путь к файлу лога как текущая директория + «spark.log» и получает контекст Spark из объекта SparkSession. Далее устанавливается уровень логирования Spark на «DEBUG» и создается логгер для записи логов.
Для различных компонентов Spark установлены уровни логирования ОШИБКА (ERROR). Функция redirect_stdout_to_file()обеспечивает перенаправление вывода в файл. Также в коде создается класс LoggerWriter, который инициализируется с логгером и уровнем логирования, определяется метод write для записи сообщений в лог с помощью метода log() логгера и метод flush для очистки буфера вывода. Для перенаправления вывода в файл sys.stdout и sys.stderr заменены на экземпляры LoggerWriter и вызвана функция redirect_stdout_to_file с параметром log_file для перенаправления вывода в указанный файл лога.
Освойте возможности Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники