Что общего у клиент-серверной архитектуры Spark Connect с JDBC-драйвером подключения к БД, как взаимодействуют клиент и сервер по gRPC, как подключиться к серверу и указать обязательность поля в схеме proto-сообщения.
Как работает Spark Connect
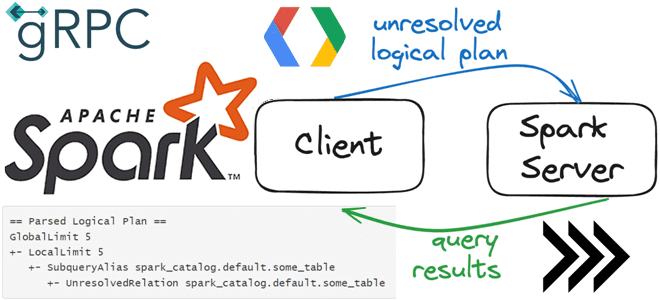
О том, что представляет собой Spark Connect и зачем нужен этот клиентский API, позволяющий удаленно подключаться к кластерам Spark с использованием API DataFrame и неразрешенных логических планов в качестве протокола, мы уже писали здесь и здесь. Сегодня разберем более подробно реализацию этой разделенной клиент-серверной архитектуры. Вообще Spark Connect — это протокол, определяющий, как клиентское приложение может взаимодействовать с удаленным сервером Spark с использованием gRPC — системы удалённого вызова процедур (RPC) с открытым исходным кодом, разработанной в Google в 2015 году. В качестве транспорта она использует протокол HTTP/2, в качестве языка описания интерфейса — протокол сериализации protobuf (Protocol Buffers). Благодаря широкому набору функций (аутентификация, двунаправленная потоковая передача, синхронное и асинхронное взаимодействие, тайм-ауты), а также независимости от языка программирования и фреймворка, gRPC сегодня активно используется в реализации микросервисной архитектуры и подключения мобильных устройств и браузерных клиентов к серверным службам.
Клиенты, реализующие протокол Spark Connect, могут подключаться и отправлять запросы к удаленным серверам Spark, аналогично тому, как клиентские приложения могут подключаться к базам данных с помощью драйвера JDBC, возвращая результат выполнения запроса.
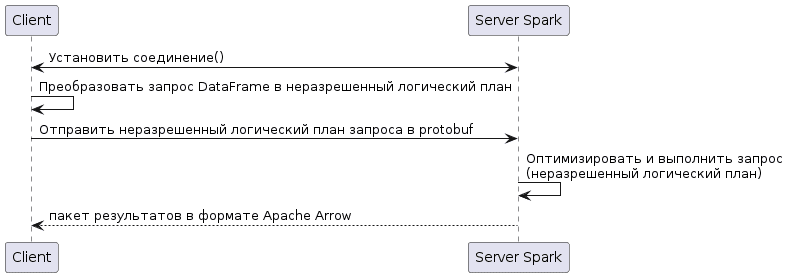
Последовательность работы Spark Connect можно описать так:
- Между клиентом и сервером устанавливается соединение с помощью gRPC, что обеспечивает независимость от языка;
- Клиент преобразует запрос DataFrame в неразрешенный логический план, который описывает цель операции, а не то, как она должна быть выполнена. При этом клиент несет ответственность за создание неразрешенного логического плана и передачу его на сервер Spark для выполнения.
- Неразрешенный логический план сериализуется и отправляется на сервер Spark. По умолчанию gRPC использует Protobuf как язык определения интерфейса (IDL) для описания интерфейса службы и структуры сообщений полезной нагрузки. Поэтому Spark Connect использует именно этот бинарный протокол сериализации, независимый от языка и платформы расширяемый механизм для сериализации структурированных данных. Это необходимо, чтобы клиент и сервер Spark могли использовать разные языки программирования или версии ПО.
- Сервер Spark оптимизирует и выполняет запрос: получает неразрешенный логический план, анализирует, оптимизирует и выполняет его, как и любой другой запрос. При этом Spark выполняет множество оптимизаций неразрешенного логического плана перед выполнением запроса. Все эти оптимизации выполняются на сервере Spark и не зависят от клиентского приложения. Таким образом, Spark Connect позволяет использовать мощные возможности оптимизации запросов Spark даже с клиентами, которые не зависят от Spark или JVM.
- Сервер Spark отправляет результаты обратно клиенту. Результаты отправляются клиенту в виде пакетов записей Apache Arrow. Один пакет записей включает в себя множество строк данных. Полный результат передается клиенту частями пакетов записей, а не всеми сразу. Потоковая передача результатов с сервера Spark на клиент предотвращает проблемы с памятью, вызванные слишком большим запросом.
Организация клиент-серверного взаимодействия
Клиент Spark Connect работает как любой другой клиент gRPC и может быть настроен соответствующим образом. Подобно JDBC или другим подключениям к базе данных, Spark Connect использует строку подключения, содержащую соответствующие параметры, которые интерпретируются для подключения к конечной точке Spark Connect.
Обычно строка подключения соответствует стандартным определениям URI. Схема URI фиксирована и имеет значение sc://. Полный URI должен быть действительным URI и правильно анализироваться большинством систем. Например, имена хостов должны быть действительными и не могут содержать произвольные символы. Параметры конфигурации передаются в стиле синтаксиса параметров URL-адреса HTTP. Это похоже на строки подключения JDBC. Компонент пути должен быть пустым. Все параметры интерпретируются с учетом регистра.
Следующий пример показывает подключение к порту 15002 на хосте myhost.com:
server_url = "sc://myhost.com/"
А в этом примере настраивается подключение с портом 433 с использованием шифрования SSL.
server_url = "sc://myhost.com:443/;use_ssl=true" server_url = "sc://myhost.com:443/;use_ssl=true;token=ABCDEFG"
Поскольку Spark Connect использует обычный клиент gRPC, путь к серверу нельзя настроить так, чтобы он оставался совместимым со стандартом gRPC и HTTP. Поэтому при попытке их совместить будет ошибка. Протоколом сериализации данных в gRPC является Protobuf, Spark Connect использует 3-ю версию этого формата, proto3, который больше не поддерживает использование ограничения. Поэтому для полей, не являющихся сообщениями, также нет функций has_field_name(), позволяющих легко определить, наличие поля.
Разработчики, работающие с protobuf, знают, что для него характерна схема данных, встроенная в само сообщение. Поля, которые семантически необходимы серверу для правильной обработки входящего сообщения, должны быть задокументированы с помощью ключевого слова Required. Для скалярных полей сервер не будет выполнять дополнительную проверку ввода. Для составных полей сервер будет выполнять минимальные проверки, чтобы избежать исключений NULL-указателя, но не будет выполнять никакой семантической проверки, например:
message DataSource {
// (Required) Supported formats include: parquet, orc, text, json, parquet, csv, avro.
string format = 1;
}
Необязательные поля следует пометить ключевым словом optional. Серверная сторона Spark Connect использует эту информацию для перехода к различным вариантам поведения в зависимости от наличия или отсутствия этого поля. Из-за отсутствия настраиваемых значений по умолчанию для скалярных типов само наличие необязательного значения не определяет его значение по умолчанию. Реализация на стороне сервера будет интерпретировать наблюдаемое значение на основе своих собственных правил, например:
message DataSource {
// (Optional) If not set, Spark will infer the schema.
optional string schema = 2;
}
Код курса
SPAD
Ближайшая дата курса
Продолжительность
ак.часов
Стоимость обучения
0
Освойте Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Архитектура данных с Apache Spark
Источники

