 618
618 
В июле 2022 года на конференции Data and AI Summit компания Databricks представила новый проект для экосистемы Apache Spark под названием Spark Connect. Что это такое и как оно пригодится разработчикам распределенных приложений и дата-инженерам, читайте далее.
Что не так с Apache Spark и зачем нужен новый проект Databricks
Появившись в 2010 году, сегодня Apache Spark стал самым популярным вычислительным движком в области Big Data. Однако, несмотря на все его возможности и преимущества, этот фреймворк также имеет ряд недостатков, которые существенно ограничивают современные варианты использования. В частности, драйверная архитектура Spark является монолитной: клиентские приложения запускаются поверх планировщика, оптимизатора и анализатора. При этом отсутствует встроенная возможность удаленного подключения к кластеру Spark без использования SQL, Scala/Java, R и Python. Текущая архитектура и API требуют, чтобы приложения работали rfr ка можно ближе к REPL-циклу (Read-Eval-Print loop, форма организации простой интерактивной среды программирования в рамках CLI-интерфейса), т. е. на драйвере. Это ограничивает интерактивное исследование данных такое, как есть в Jupyter Notebook или Google Colab. Наконец, несовместимые с JVM языки программирования не могут использоваться в Apache Spark.
Кроме того, монолитная архитектура драйверов Spark приводит к следующим проблемам:
- нестабильность – поскольку все приложения работают непосредственно на драйвере, некоторые пользователи могут вызывать критические исключения, например, нехватка памяти, которые могут привести к отключению кластера для всех пользователей;
- сложности обновления — текущая запутанность платформы и клиентских API, например, главная и второстепенная зависимости в пути к классам, не позволяют плавно обновлять версии Spark, что препятствует внедрению новых фичей;
- трудности отладки и наблюдаемости: — у пользователя может не быть правильного разрешения безопасности для подключения к основному процессу Spark, а отладка JVM-процессов снимает все границы безопасности, установленные фреймворком. Кроме того, подробные журналы и системные метрики недоступны непосредственно в приложении.
Чтобы преодолеть все эти проблемы, компания Databricks, которая развивает Apache Spark и занимается коммерциализацией этой технологии, в июле 2022 года представила новый проект – Spark Connect. Что это такое и как работает, рассмотрим далее.
Что такое Spark Connect
Spark Connect – это приложение разделенной клиент-серверной архитектуры для Apache Spark, которая позволяет удаленно подключаться к кластерам Spark с использованием API DataFrame и неразрешенных логических планов в качестве протокола. Разделение между клиентом и сервером позволяет использовать Spark и его открытую экосистему из любой точки мира, а также встраивать его в различные приложения для работы с данными, IDE, интерактивные блокноты, используя любые языки программирования.
По сути, этот проект создает тонкий клиент, позволяющий выполнять запросы Spark на устройствах с низкими вычислительными мощностями за счет модернизации драйвера, что позволяет обойти некоторые недостатки монолитного драйвера и улучшить поддержку мультиарендности. Connect будет полезен в следующих случаях:
- запуск заданий Spark из различных приложений или устройств с низким уровнем вычислительных ресурсов;
- использование мультиарендных кластеров;
- улучшенное управление памятью заданий Spark на клиенте, чтобы обеспечить явное выделение ресурсов и избежать OOM-ошибки;
- устранение конфликтов зависимостей, т.к. теперь они определяются в клиенте для каждого приложения;
- разделение обновлений серверной и клиентской версий фреймворка;
- мощные возможности пошаговой отладки;
- улучшенная наблюдаемость — доступ к журналам/метрикам в клиенте вместо просмотра централизованного хранилища логов.
Клиентский API Spark Connect основан на API DataFrame, который использует неразрешенные логические планы в качестве независимого от языка протокола между клиентом и драйвером Spark. Этот клиент преобразует операции DataFrame в неразрешенные планы логических запросов, которые кодируются с использованием Protobuf и отправляются на сервер с помощью платформы gRPC. К примеру, последовательность операций с датафреймом в таблице логов преобразуется в логический план и отправляется на сервер.
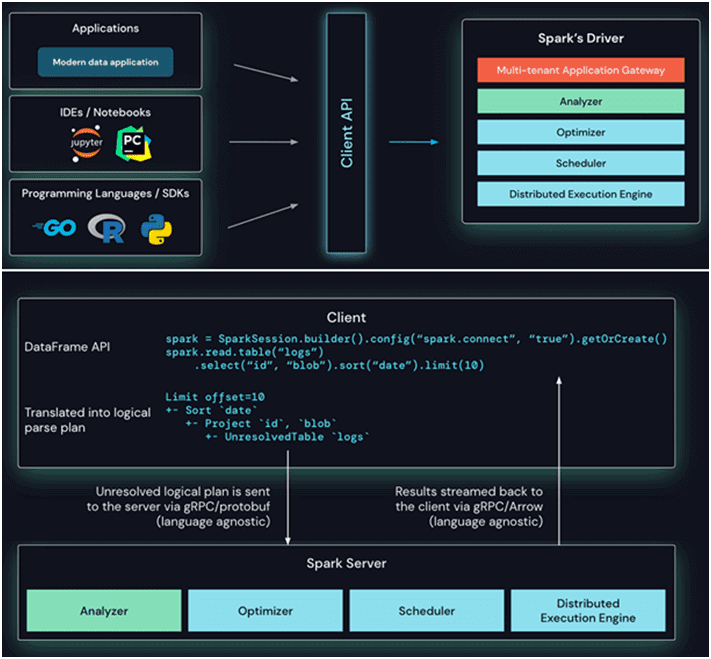
Конечная точка Connect, встроенная в сервер Spark, получает и преобразует неразрешенные логические планы в операторы логического плана. Это похоже на синтаксический анализ SQL-запроса, когда анализируются атрибуты и отношения и строится первоначальный план синтаксического анализа. После этого запускается стандартный процесс выполнения Spark, гарантирующий, что Connect использует все оптимизации и улучшения Spark. Результаты передаются обратно клиенту через gRPC в виде пакетов строк, закодированных Apache Arrow, о чем мы подробно рассказываем в новой статье.
Благодаря этой новой архитектуре Connect устраняет вышеотмеченные операционные проблемы и дает следующие преимущества:
- стабильность — приложения, использующие слишком много памяти, теперь будут влиять только на свою собственную среду, поскольку работают в отдельных процессах. Пользователи могут определять свои собственные зависимости от клиента, не беспокоясь о возможных конфликтах с драйвером Spark.
- простота обновления — драйвер Spark теперь можно легко обновить независимо от приложений, например, чтобы воспользоваться улучшениями производительности и исправлениями безопасности. Это означает, что приложения могут быть совместимы с предыдущими версиями, если определения RPC на стороне сервера поддерживают это.
- возможность отладки и мониторинга – Spark Connect обеспечивает интерактивную отладку во время разработки непосредственно из пользовательской IDE, а сами приложения можно отслеживать с помощью собственных метрик платформы и библиотек логов.
В будущем разработчики Spark Connect планируют сделать его доступным в качестве экспериментального API самого Apache Spark. Хотя этот проект неплохо решает некоторые проблемы с изоляцией и асинхронизацией, он еще имеет несколько критичных недостатков, из-за которых его пока не следует применять в production:
- отсутствие механизма очередей для обработки скачкообразного трафика параллельных заданий и их выстраивания в кластере, что приводит к необходимости создавать настраиваемое решение для управления частотой заданий поверх кластера Spark;
- слабое регулирование скорости отправки и количества заданий Apache Livy, который используется в качестве прокси-сервиса для доставки полезной нагрузки Spark-заданий в кластер.
Возможно, в следующем выпуске эти недостатки будут устранены, а проект Spark Connect займет достойное место в экосистеме самого популярного вычислительного движка в мире Big Data. Как оптимизировать работу Spark-приложений на платформе Databricks, читайте в нашей новой статье. А о том, как идеи Databrics воплотились в официальном выпуске фреймворка 3.4.0 в апреле 2023 года вы узнаете здесь.
Узнайте больше про использование Apache Spark в аналитике больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

