 913
913 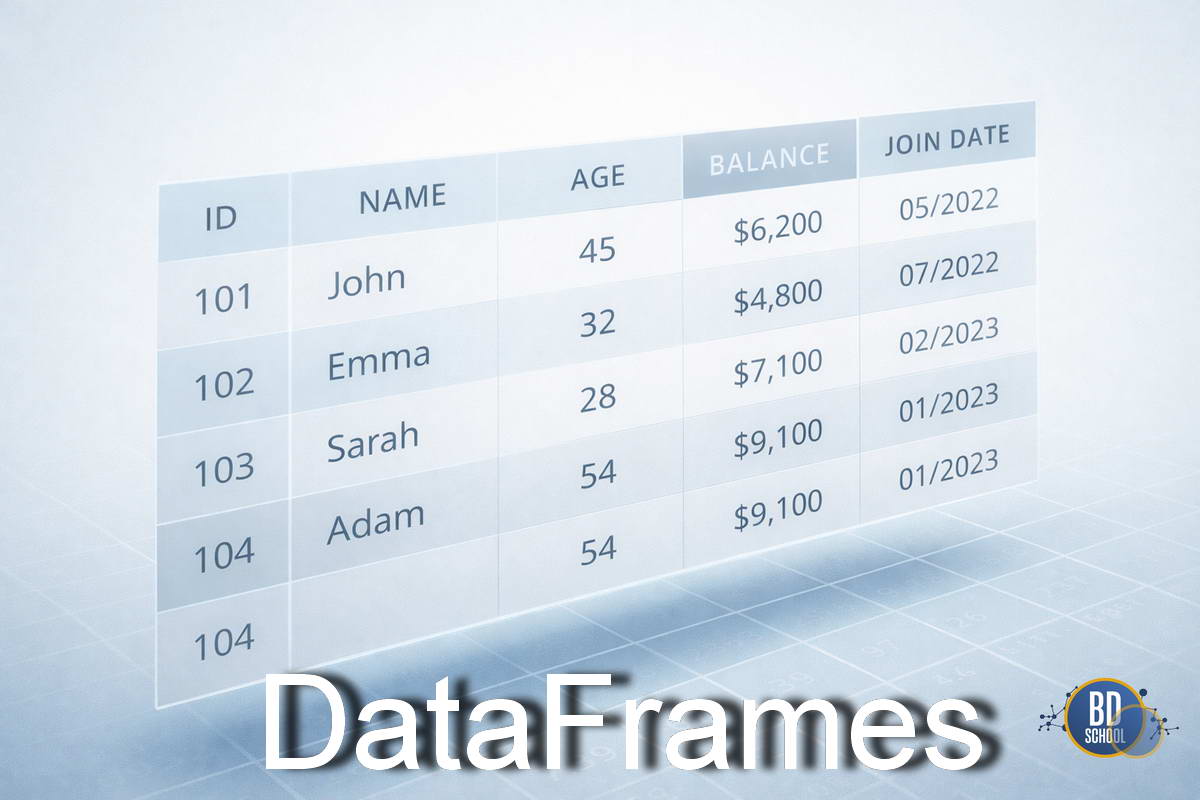
Содержание
- Анатомия DataFrame
- Series vs DataFrame и работа с Осями
- Архитектура памяти Dataframe в Pandas - BlockManager
- Практика - Базовый синтаксис (Pandas)
- Механизм работы
- Сценарии использования Dataframes
- Взаимодействие и Код
- Сравнение Pandas vs Spark DataFrame vs Polars
- Оптимизация и "подводные камни"
- Заключение
- Референсные ссылки
DataFrame — это табличная структура данных с именованными столбцами и индексами строк, предназначенная для удобного хранения, преобразования и анализа структурированных данных в аналитических и научных вычислениях.
Представьте себе лист Excel, но с возможностью программного управления и обработки миллионов строк за секунды. Это основной объект для манипуляции данными в языке Python (библиотека Pandas) и экосистеме Big Data (Apache Spark). DataFrame хранит данные разных типов (числа, строки, даты) в столбцах, но имеет строгую структуру. Без понимания этого инструмента работа современного дата-сайентиста или аналитика невозможна.
Анатомия DataFrame
Чтобы эффективно работать с DataFrame, нужно понимать его внутреннее устройство. Он не просто хранит ячейки, а связывает их в интеллектуальную систему.
Конструкция держится на трех основных компонентах:
- Index (Индекс). Это «адрес» каждой строки. Обычно это последовательность чисел от 0 до N, но индексом могут быть даты или уникальные ID. Индекс позволяет мгновенно находить нужные записи без перебора всего массива.
- Columns (Колонки). Это имена переменных или признаков. Каждый столбец имеет имя (заголовок) и, что критически важно, определенный тип данных.
- Data (Данные). Это само содержимое ячеек. В библиотеке Pandas данные часто хранятся в виде массивов NumPy для максимальной скорости вычислений.
Когда вы пишете код, вы всегда обращаетесь к координатам: df[колонка][индекс]. Взаимодействие этих компонентов определяет, как мы обращаемся к информации. Мы не говорим «ячейка C5», мы говорим «строка с индексом ‘2023-10-01’ и колонка ‘Revenue’».
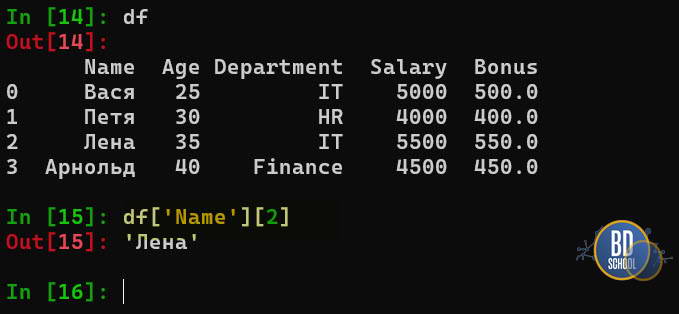
Другие варианты обращения к данным вы можете посмотреть на следующей таблице
| Операция | Синтаксис | Результат (тип) |
| Выбор столбца | df[col] | Series |
| Выбор строки по метке | df.loc[label] | Series |
| Выбор строки по индексу (позиции) | df.iloc[loc] | Series |
| Срез строк | df[5:10] | DataFrame |
| Выбор строк по булеву вектору | df[bool_vec] | DataFrame |
Ключевая особенность архитектуры — гетерогенность столбцов. Вы можете хранить целые числа в колонке «Возраст» и текст в колонке «Имя». Однако внутри одного столбца тип данных всегда должен быть одинаковым. Это позволяет компьютеру оптимизировать память и применять быстрые векторные операции.
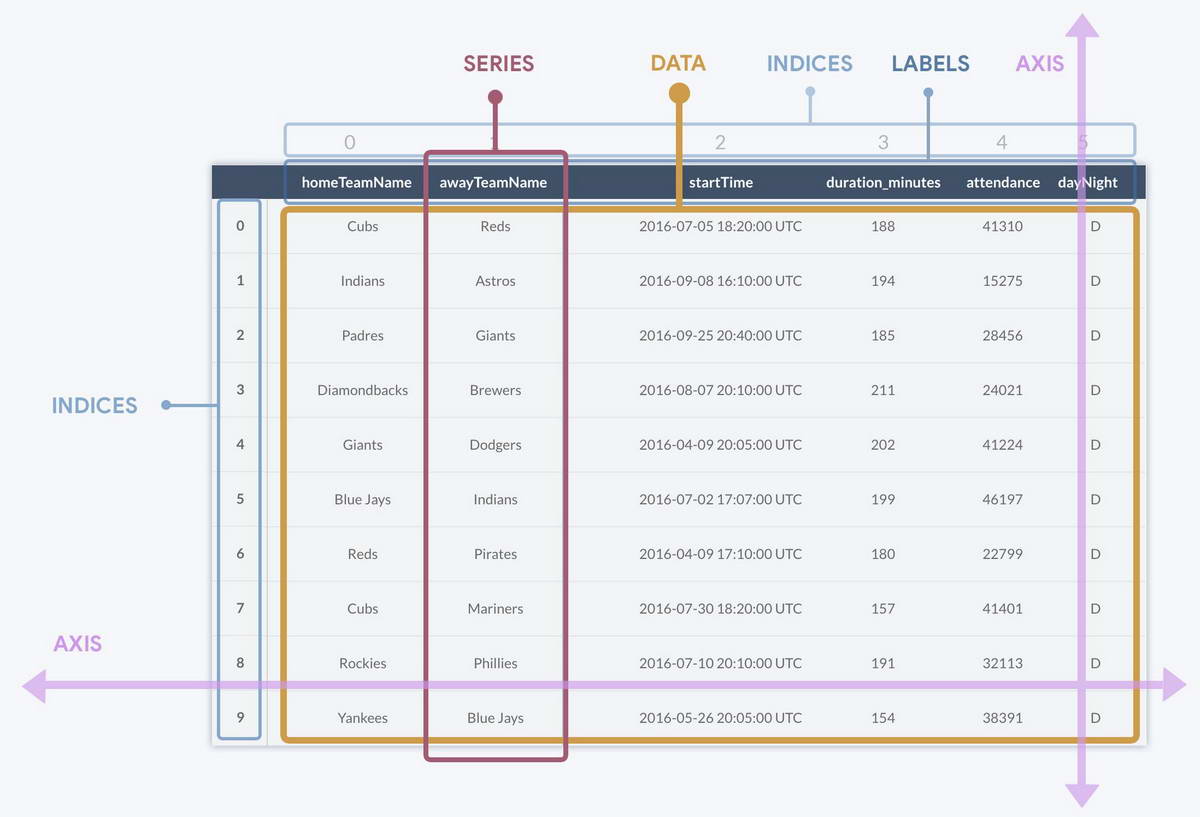
Series vs DataFrame и работа с Осями
Важно различать одномерные и двумерные структуры.
-
Series: Это один столбец с его индексом. Это одномерный массив.
-
DataFrame: Это контейнер для нескольких объектов Series. Эти Series склеены вместе и имеют общий индекс.
При операциях с таблицей мы часто указываем направление. В Pandas и NumPy это называется осями (axes):
-
axis=0 Двигаемся вдоль индекса (по вертикали). Если мы считаем среднее с axis=0, мы схлопываем строки и получаем среднее для каждого столбца.
-
axis=1 Двигаемся вдоль колонок (по горизонтали). Операция применяется к каждой строке отдельно.
Архитектура памяти Dataframe в Pandas — BlockManager
В отличие от того, как мы видим таблицу на экране, Pandas не хранит данные построчно. Под капотом работает механизм BlockManager, который группирует колонки по типам данных.
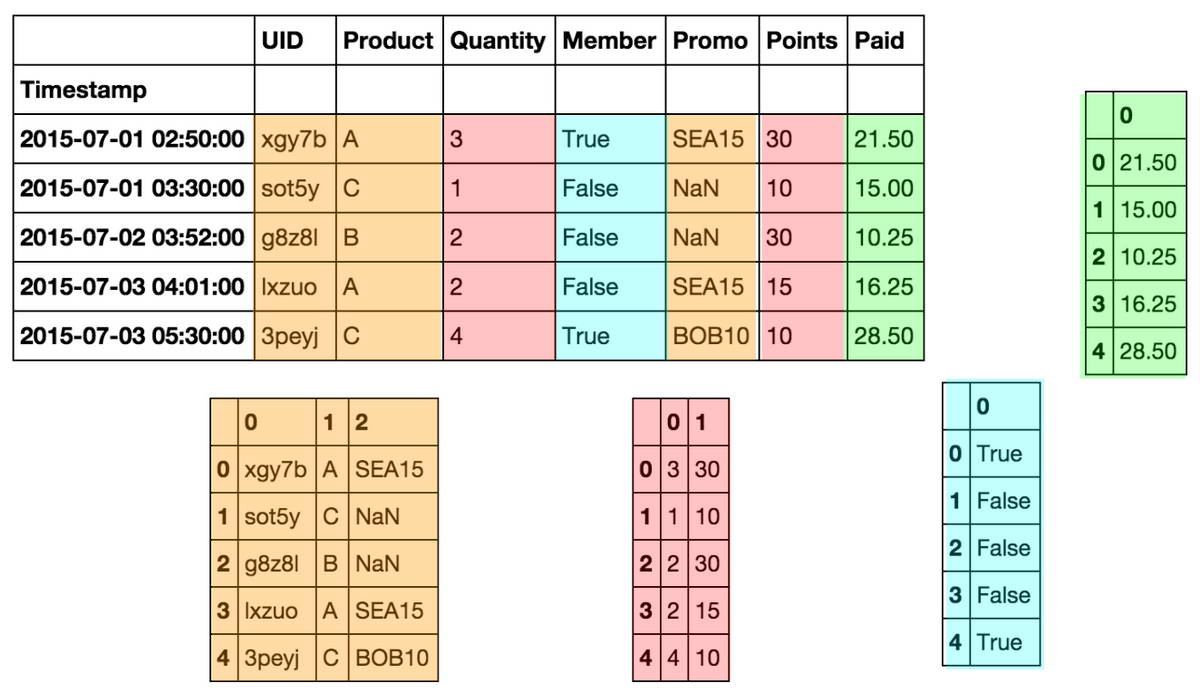
DataFrame физически состоит из одного или нескольких блоков.
- Все колонки типа int собираются в один блок.
- Все колонки типа float — в другой.
- Объекты (строки) — в третий.
Именно внутри блока данные хранятся в памяти непрерывно (contiguous memory). Это ключевой момент для понимания производительности.
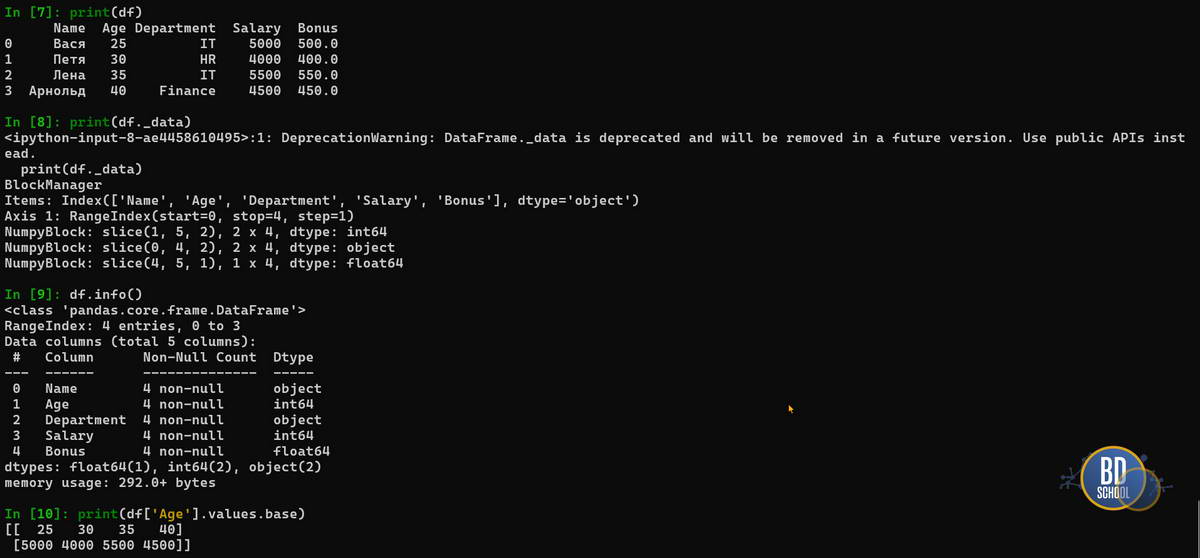
Инспекция памяти
Вы можете увидеть это устройство своими глазами. Атрибут _mgr (_data depreciated) покажет внутреннюю кухню BlockManager, а .values.base подтвердит, что разные колонки одного типа делят общую память.
# Посмотреть, как BlockManager сгруппировал данные print(df._mgr) # Проверить, что колонка 'Age' (int) делит память с 'Salary' (int) # Вывод покажет значения и других колонок из того же блока print(df['Age'].values.base)
Влияние на скорость (Performance)
Понимание блочной структуры помогает избегать скрытых тормозов в коде.
Срезы (Slicing)
- Если вы делаете срез колонок одного типа (например, только числовые Age и Salary), Pandas не копирует данные. Он создает «вид» (view), что очень быстро.
- Если срез затрагивает разные типы (например, число Age и строку Department), Pandas вынужден копировать данные в новую структуру.
Добавление строк (Appending)
Это одна из самых дорогих операций. Добавление новой строки заставляет Pandas:
- Создавать новые блоки.
- Копировать все данные из старых блоков в новые.
- Заново перераспределять память.
Best Practice: Никогда не добавляйте данные в цикле построчно (append). Гораздо эффективнее собрать данные в список и один раз объединить их через pd.concat().
Добавление колонок
Здесь Pandas работает умнее. Копирование блоков откладывается (lazy) до тех пор, пока какая-либо операция реально не потребует перестройки памяти.
Практика — Базовый синтаксис (Pandas)
Разберем основные операции, с которыми инженер сталкивается ежедневно. Для примеров используем библиотеку Pandas — стандарт индустрии.
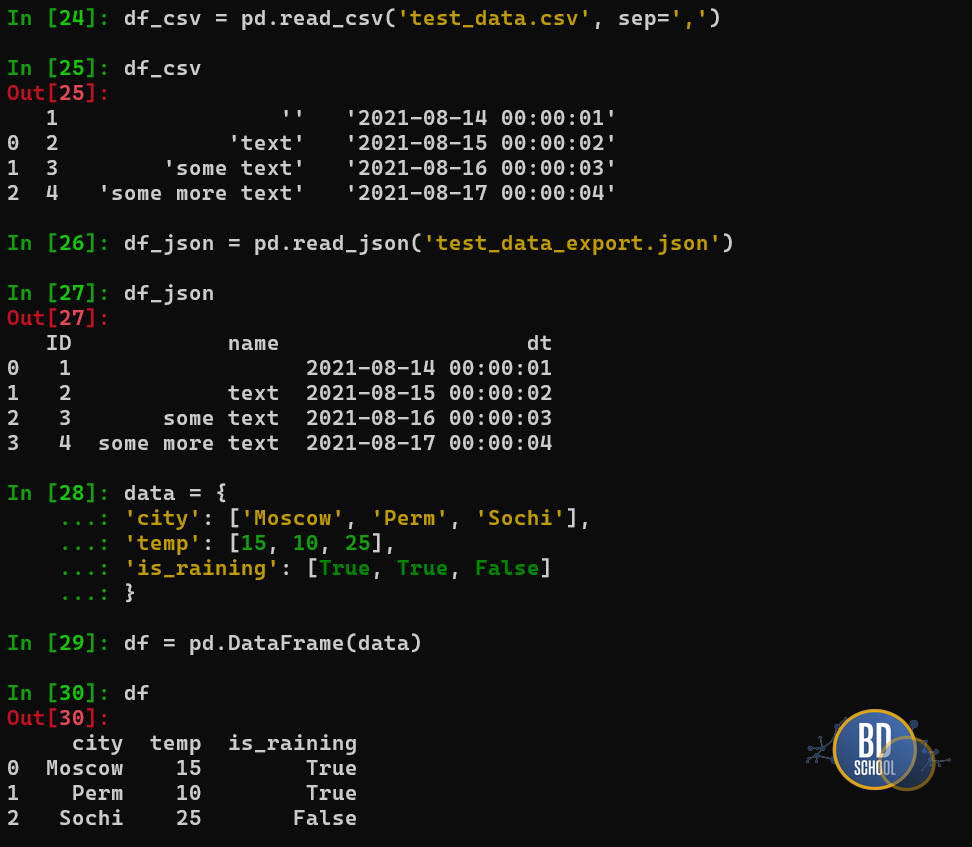
Загрузка и Создание
Мы редко создаем данные вручную, обычно мы их читаем.
import pandas as pd
# Сценарий 1: Чтение из файла (Самый частый кейс)
# Pandas сам распознает заголовки и типы данных
df_csv = pd.read_csv('test_data.csv', sep=',')
df_json = pd.read_json('test_data_export.json')
# Сценарий 2: Создание из словаря (для тестов)
data = {
'city': ['Moscow', 'Perm', 'Sochi'],
'temp': [15, 10, 25],
'is_raining': [True, True, False]
}
# Ключи словаря станут колонками
df = pd.DataFrame(data)
Доступ к данным — loc vs iloc
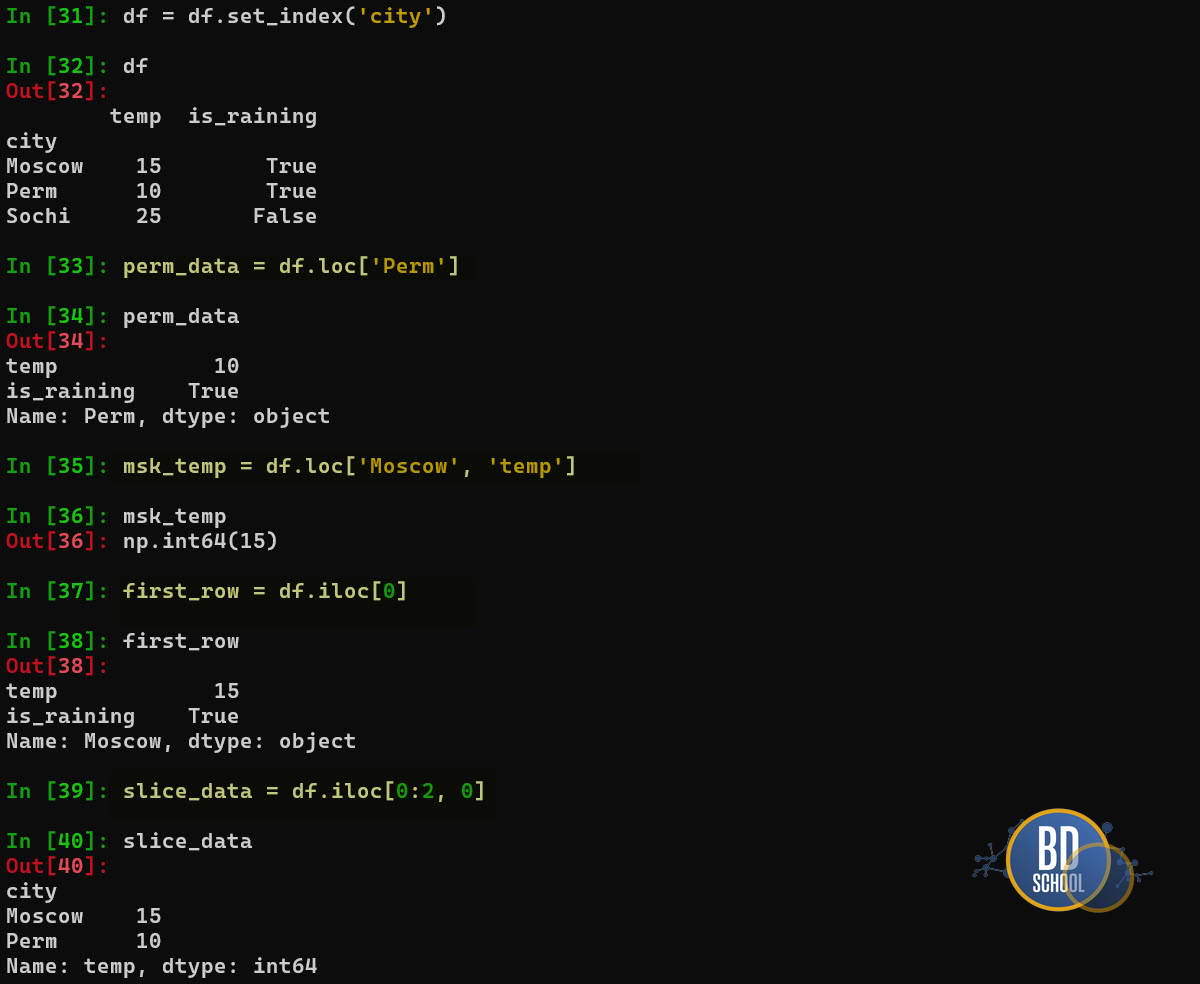
Это самая запутанная тема для новичков. Запомните главное правило: loc смотрит на названия, iloc — на позиции.
Представьте, что у нас есть DataFrame df, где индексом являются имена городов ( для примера возьмем справочник созданный нами в предыдущей практике Moscow-Perm-Sochi)
# Установим город как индекс
df = df.set_index('city')
# --- .loc (LABEL based) ---
# "Дай мне данные для строки с меткой 'Perm'"
perm_data = df.loc['Perm']
# "Дай мне температуру (колонка) для Москвы (строка)"
msk_temp = df.loc['Moscow', 'temp'] # Вернет 15
# --- .iloc (INTEGER based) ---
# "Дай мне первую строку таблицы" (неважно, как она называется)
first_row = df.iloc[0]
# "Дай мне первые 2 строки и 1-ю колонку"
slice_data = df.iloc[0:2, 0]
Используйте loc для бизнес-логики («найди клиента X»), а iloc — для технических операций («дай последние 5 строк»).
Механизм работы
Почему DataFrame работает быстрее, чем обычные списки Python? Секрет кроется в способе обработки команд. Основные принципы механики включают:
- Векторизация (Vectorization). Операции применяются ко всему столбцу сразу. Вам не нужно писать циклы, чтобы умножить цены на налог. Вы просто умножаете колонку на число, и процессор делает это пачкой.
- Выравнивание (Alignment). При сложении двух таблиц DataFrame автоматически сопоставляет данные по индексам. Если индексы не совпадают, система подставит значение NaN (Not a Number), но не выдаст ошибку.
- Бродкастинг (Broadcasting). Это механизм распространения операций меньшей размерности на большую. Например, при вычитании среднего значения из всего столбца это число «растягивается» на длину всей таблицы.
Таким образом, механизм DataFrame берет на себя рутинную работу по итерациям и сопоставлению. Разработчик описывает «что» нужно сделать, а библиотека решает «как» это сделать эффективно.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
6 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Сценарии использования Dataframes
DataFrame используется на всех этапах жизненного цикла данных, от загрузки до моделирования. Это универсальный контейнер для аналитики.
Наиболее частые сценарии применения:
- Разведочный анализ (EDA). Загрузка «сырых» данных для первого взгляда. Аналитики используют методы describe() или head() для оценки распределения значений, поиска аномалий и понимания структуры.
- Очистка данных (Data Cleaning). Реальные данные редко бывают идеальными. DataFrame предоставляет инструменты для заполнения пропусков, удаления дубликатов и исправления опечаток в текстовых полях.
- Инженерия признаков (Feature Engineering). Создание новых колонок на основе существующих. Например, выделение дня недели из даты или вычисление отношения «цена/качество» для обучения нейросетей.
- ETL-процессы. Извлечение данных из баз, их трансформация в нужный формат и загрузка в хранилище. DataFrame служит буфером для обработки информации в памяти.
В итоге, практически любая задача по обработке табличных данных в Data Science решается через этот интерфейс.
Взаимодействие и Код
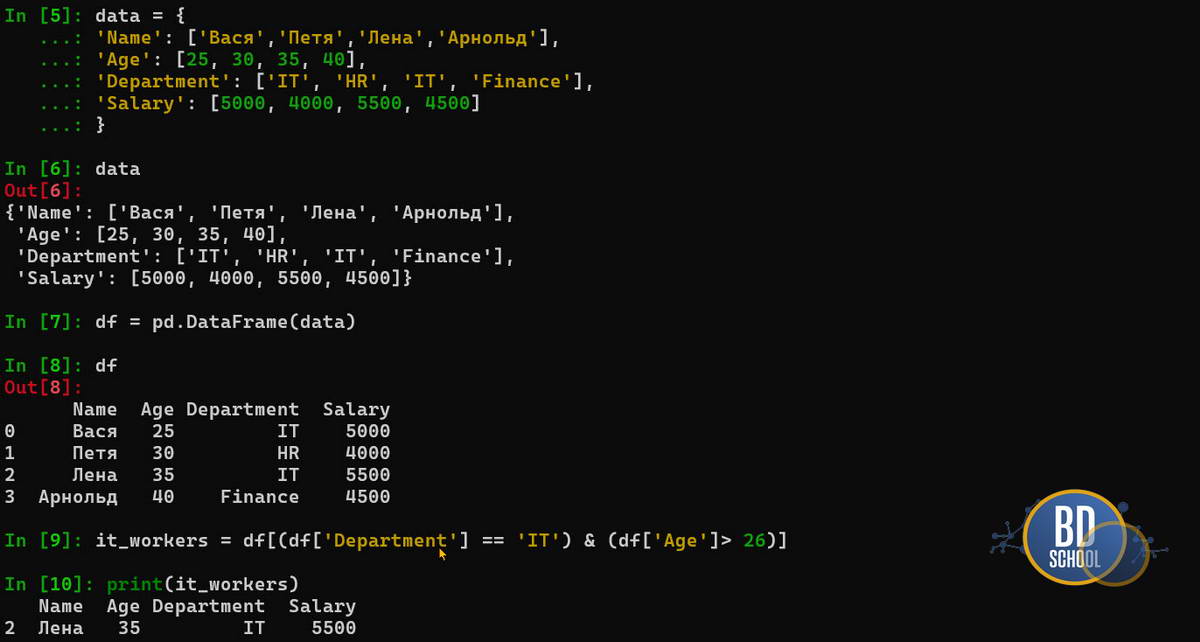
Стандартом индустрии для локальной обработки данных является библиотека Pandas. Рассмотрим базовые операции на языке Python. Сначала мы создадим простой DataFrame и выполним фильтрацию.
import pandas as pd
# Создаем данные из словаря
data = {
'Name': ['Вася', 'Петя', 'Лена', 'Арнольд'],
'Age': [25, 30, 35, 40],
'Department': ['IT', 'HR', 'IT', 'Finance'],
'Salary': [5000, 4000, 5500, 4500]
}
data
# Инициализируем DataFrame
df = pd.DataFrame(data)
# Фильтрация: выбираем сотрудников IT старше 26 лет
it_workers = df[(df['Department'] == 'IT') & (df['Age'] > 26)]
print(it_workers)
Второй важнейший паттерн — группировка и агрегация. Это аналог GROUP BY в SQL. Мы разбиваем данные на группы, применяем функцию и собираем обратно.
# Группируем по отделу и считаем среднюю зарплату
avg_salary = df.groupby('Department')['Salary'].mean()
# Добавляем новую колонку (векторная операция)
df['Bonus'] = df['Salary'] * 0.1
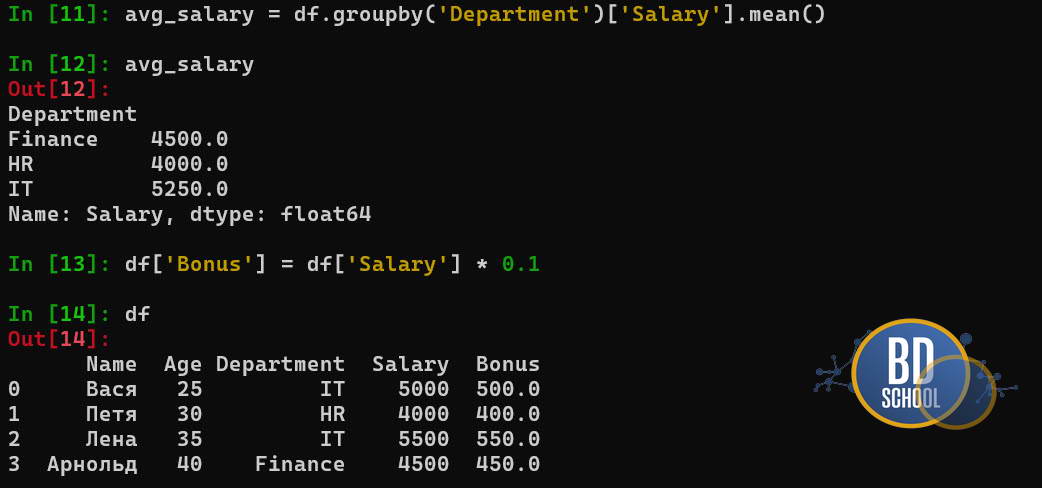
Этот код читается почти как обычный английский текст, что снижает порог входа для новичков, но при этом покрывают 80% повседневной работы аналитика данных.
Сравнение Pandas vs Spark DataFrame vs Polars
Хотя концепция DataFrame едина, реализации могут отличаться. Выбор инструмента зависит от объема данных и доступных ресурсов. Когда данных становится слишком много для одной машины (Big Data), Pandas перестает справляться. На сцену выходят распределенные системы. Принцип остается тем же (таблица, колонки, операции), но синтаксис и исполнение меняются.
Сравним, как одну и ту же задачу решают разные инструменты. Задача прочитать CSV и отфильтровать строки, где value > 100.
- Pandas. Идеален для данных, которые помещаются в оперативную память одного компьютера (обычно до 10-50 ГБ). Работает на одном ядре процессора. Это самый богатый функционально инструмент.
- Apache Spark DataFrame. Предназначен для Big Data. Используется для кластерных вычислений (терабайты данных). Данные разбиваются на части и обрабатываются параллельно на кластере серверов. Использует «ленивые вычисления» (lazy evaluation): ничего не считает, пока не потребуете результат.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Example").getOrCreate()
# Чтение (ленивое)
sdf = spark.read.csv("big_data.csv", header=True, inferSchema=True)
# Фильтрация (трансформация)
filtered_sdf = sdf.filter(sdf.value > 100)
# Действие (Action) — только тут Spark реально начнет работать
filtered_sdf.show()
- Polars. Современная, сверхбыстрая альтернатива Pandas, написанная на языке Rust. Она использует все ядра процессора и эффективно работает с памятью. Это восходящая звезда в мире аналитики.
import polars as pl
# Чтение
pdf = pl.read_csv("data.csv")
# Фильтрация (синтаксис похож на Pandas, но быстрее)
res = pdf.filter(pl.col("value") > 100)
print(res)
Если вы выучили логику работы с DataFrame в Pandas, переход на Spark или Polars займет у вас пару дней. Логика «выбрать — отфильтровать — сгруппировать» везде одинакова. Выбирайте Pandas для обучения и небольших проектов, Spark — для терабайтов данных, а Polars — для ускорения локальной обработки.
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
20 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Оптимизация и «подводные камни»
При работе с большими таблицами легко написать код, который «завесит» компьютер. Эффективность требует дисциплины. Потому мы можем предложить основные правила оптимизации.
- Избегайте циклов for. Никогда не итерируйтесь по строкам с помощью iterrows(). Это работает в сотни раз медленнее встроенных векторных функций.
- Следите за типами данных. По умолчанию Pandas может использовать int64 или float64. Для небольших чисел (например, возраста) достаточно int8. Это снижает потребление памяти в разы.
- Осторожнее с копиями. При изменении среза данных можно получить SettingWithCopyWarning. Это сигнал, что вы меняете копию, а не оригинал. Используйте .loc для явного указания места записи.
Соблюдение этих простых правил сделает ваши скрипты быстрыми и надежными. Чуть больше информации про DataFrames вы сможете получить посмотрев наши видео про основы работы с библиотекой Pandas ( где объясняется тема Dataframe, Series) которое является частью бесплатного видео курса записанного преподавателями «Школы больших данных» и доступного на сайте нашего проекта «Школы Питон».
Заключение
DataFrame — это универсальный язык общения аналитика с данными. Он превращает хаотичные массивы информации в стройную структуру, готовую к анализу. Неважно, используете ли вы Pandas на ноутбуке или Spark на кластере, логика работы остается прежней. Следующим шагом после освоения DataFrame должно стать изучение SQL для работы с базами данных.
Референсные ссылки
- [Pandas Documentation: Intro to Data Structures] (https://pandas.pydata.org/docs/user_guide/dsintro.html)
- [Apache Spark: DataFrames Guide] (https://spark.apache.org/docs/latest/sql-programming-guide.html)
- [Polars User Guide: Getting Started] (https://docs.pola.rs/user-guide/)