 1120
1120 
Содержание
В этой статье по обучению Apache Spark рассмотрим, чем графический веб-интерфейс этого фреймворка полезен разработчику распределенных приложений. Читайте далее, где посмотреть кэшированные данные, визуализацию DAG, переменные среды, исполняемые SQL-запросы, а также прочие важные метрики кластерных вычислений и аналитики больших данных.
9 страниц Apache Spark UI
Apache Spark предоставляет набор пользовательских веб-интерфейсов (UI) для отслеживания состояния и потребления ресурсов кластера на следующих 9 вкладках [1]:
- Jobs Tab (Задания) – сводная страница всех заданий в приложении Spark с детализацией сведений по каждому заданию (Jobs detail);
- Stages Tab (Этапы) — сводная страница с текущим состоянием всех этапов каждого задания в Spark-приложении с детализацией сведений по каждому из них (Stages detail);
- Storage Tab (Хранилище) – сводная страница с сохраненными (кэшированными) RDD и датафреймами Spark-приложения с детализацией сведений об их уровнях хранения, размерах, разделах и используемых исполнителях;
- SQL Tab – информация о заданиях Spark SQL, включая их продолжительность, а также физические и логические планы запросов;
- JDBC/ODBC Server Tab — информация о сеансах и отправленных SQL-операциях;
- Structured Streaming Tab — краткая статистика по запущенным и выполненным запросам заданий структурированной потоковой передачи;
- Streaming (DStreams) Tab – данные по микропакетам в DStream API;
- Environment Tab (Среда) — значения различных переменных среды и конфигурации, включая JVM, Spark и системные свойства;
- Executors Tab (Исполнители) — сводная информация об исполнителях, созданных для приложения, включая использование ресурсов.
Для отображения системных метрик в веб-интерфейсе фреймворк использует слушатели — специальные перехватчики событий, о которых мы писали здесь. Далее мы рассмотрим несколько типичных кейсов, когда разработчику Spark-приложений пригодятся сведения из всех этих вкладок веб-GUI.
Задания и этапы
На сводной странице Jobs Tab отображается высокоуровневая информация о состоянии, продолжительности и ходе выполнения всех заданий, а также общая временная шкала событий. На странице с детальными данными (Jobs detail) по заданию показаны все его этапы, временная шкала событий и визуализация DAG. Временная шкала отображает в хронологическом порядке события, связанные с исполнителями и заданиями. Подробная информация о заданиях сгруппирована по их статусу (Active, Completed, Failed) демонстрирует подробную информацию о заданиях, включая идентификатор, описание, время отправки, продолжительность, сводку этапов и индикатор выполнения.
Именно здесь можно столкнуться с нетипичной ситуацией, когда одно действие запускает несколько заданий. Чаще всего это случается при вызове функции show(), которая по умолчанию возвращает только 20 строк, обрабатывая один раздел. Но если Spark не найдет искомые данные в первых 20 строках, он запустит другое задание, которое будет обрабатывать больше разделов. Фреймворк будет повторять это, пока не найдет нужные данные или не обработает все разделы [2].
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
1 июня, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
На вкладке Stages отображается сводная информация об этапах всех заданий в приложении Spark с учетом их статусов (active, pending, completed, skipped, failed). Здесь же можно завершить активные этапы и посмотреть подробную информацию о каждой задаче. На странице детальных сведений об этапе (Stages detail) показано общее время выполнения всех задач, местоположение, произвольный размер чтения/записи и идентификаторы связанных заданий. Также здесь можно посмотреть визуальное представление DAG этого этапа. Вершины этого направленного ациклического графа представляют собой структуры данных (RDD или DataFrame), а ребра – вычислительные операции. Узлы сгруппированы по области действия (BatchScan, WholeStageCodegen, Exchange и т. Д.) и аннотированы идентификатором.
Также здесь отображаются сводные показатели для всех задач в таблице и на временной шкале: время десериализации задач, их продолжительность, общее время сборки мусора JVM, время сериализации и получения результата, задержка планировщика, пиковая память выполнения и другие важные индикаторы вычислительных процессов в кластере Apache Spark [1]. Также на вкладке «Этапы» в таблице с задачами можно посмотреть «Уровень локальности» (Locality Level) данных для каждой задачи, о чем мы рассказываем в этой статье.
Потоковая обработка данных
При выполнении заданий структурированной потоковой передачи в микропакетном режиме вкладка Structured Streaming в Spark в веб-GUI покажет статистику по запущенным и выполненным запросам, в т.ч. последние исключения в случае неудачи. Также на странице статистики отображаются некоторые полезные показатели о состоянии потоковых запросов: скорость поступления и обработки данных, продолжительность микропакетных операций и количество обработанных записей.
А на вкладке Streaming можно просмотреть данные по DStream API, такие как задержка планирования и время обработки каждого микропакета в потоке данных, что пригодится при отладке Spark-приложения [1].
Кэшированные данные
В статье про лучшие практики работы с кэшем в Apache Spark SQL мы отмечали, что в веб-GUI на вкладке Storage для каждого кэшированного набора данных можно увидеть, сколько места он занимает в памяти или на диске с детализацией по каждому разделу [3]. Здесь же представлены сведения об уровне хранения этих данных, количестве разделов и накладных расходах на память. Примечательно, что недавно сохраненные RDD или DataFrames не отображаются на вкладке Storage до их материализации. Поэтому, чтобы отслеживать конкретный набор данных, следует убедиться, что была запущена операция действия (action) [1]. О разнице между преобразованиями (transformation) и действиями (action) мы писали в этом материале.
Запросы и метрики Spark SQL
Если Spark-приложение выполняет SQL-запросы, то на вкладке SQL отображаются их физические и логические планы, а также связанные с ними задания. Для каждого запроса можно просмотреть подробности: как фреймворк его анализирует, оптимизирует и выполняет. Также при разработке Spark-приложений аналитики больших данных полезно оценить метрики SQL-операторов, которые отображаются в блоке физических операторов. Например, узнать сколько строк выводится после оператора фильтра или каково общее количество, записанных в случайном порядке в shuffle-операциях. Всего Spark UI позволяет просмотреть 22 разных метрики SQL-операторов [1].
Когда Spark работает как распределенный механизм SQL, в веб-GUI становится доступной вкладка JDBC/ODBC Server, которая показывает информацию о сеансах и отправленных SQL-операциях. Она содержит 3 раздела [1]:
- общая информация о сервере JDBC/ODBC – время запуска и безотказной работы;
- данные об активных и завершенных сессиях, включая сведения о пользователе и IP-адрес соединения, идентификатор сеанса, время его начала, окончания и продолжительности, а также количество выполненных операций;
- статистика отправленных SQL-операций, в т.ч. детализацию плана выполнения с проанализированными и оптимизированными логическим и физическим планом или ошибками в операторе.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
1 июня, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Информация о кластере Apache Spark
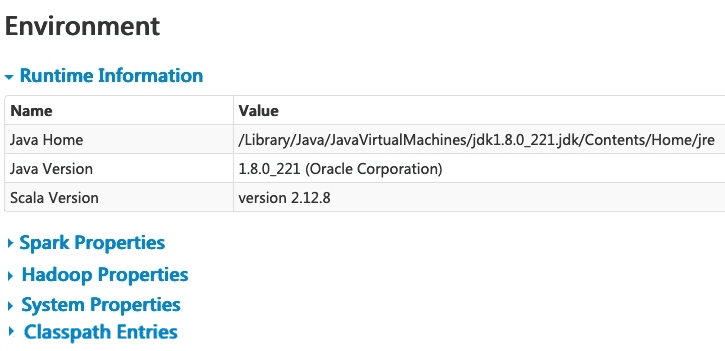
На вкладке Environment отображаются значения переменных среды и конфигурации JVM и Spark, а также системные свойства. Эта страница состоит из пяти частей [1]:
- информация о среде выполнения (Runtime Information) – сведения об используемых версиях Java и Scala;
- свойства приложения (Spark Properties) — spark.app.name и spark.driver.memory, включая свойства hadoop.*;
- свойства Hadoop и YARN (Hadoop Properties);
- системные свойства (System Properties) отображают подробную информацию о JVM;
- Classpath Entries – список классов, загруженных из разных источников, что полезно для разрешения межклассовых конфликтов.
На вкладке Executors отображается сводная информация об исполнителях, созданных для приложения, включая потребление памяти (используемой и зарезервированной для кэширования), диска и ядер ЦП, используемых каждым исполнителем. Здесь же доступна информация о задачах и перемешивании, а также сведения о производительности Spark-приложения, включая время сборки мусора. Доступна детализация типового журнала ошибок в консоли исполнителя и дамп потока JVM. Все эти сведения пригодятся разработчику распределенных приложений для анализа их производительности[1]. А где посмотреть spill-данные, мы рассказываем в этой статье. Справедливости ради стоит отметить, что GUI отлично подходит для мониторинга небольшого количества Spark-приложений, в том числе запущенных в Google Colab, как это мы разбираем здесь. Но отслеживать сотни и тысячи таких заданий в стандартном GUI фреймворка становится не очень удобно. Поэтому дата-инженеры маркетплейса Joom разработали и бесплатно открыли для всех желающих облачный сервис мониторинга проблем с производительностью Spark-приложений и рекомендациями по их устранению. Об этом вы узнаете в нашей новой статье.
А освоить все возможности Apache Spark для эффективной разработки распределенных приложений и аналитики больших данных, вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

