
Запуская наш новый курс по Эксплуатация Apache NIFI, сегодня рассмотрим 3 популярных вопроса про этот Big Data фреймворк с комментариями компании Cloudera. Читайте далее, может ли NiFi заменить пакетные ETL-оркестраторы, как использовать REST API для управления потоками данных в этом фреймворке, а также где настраивать политики управления доступом в многопользовательской...

Сегодня в рамках обучения разработчиков распределенных приложений и дата-инженеров рассмотрим практический пример потоковой интеграции данных из 2-х разных источников с Apache Kafka. Читайте далее, как мгновенно передать данные между реляционными СУБД с помощью готовых JDBC-коннекторов через cURL-вызовы к REST API Kafka Connect. Apache Kafka как средство потоковой интеграции данных Интеграция...

Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...
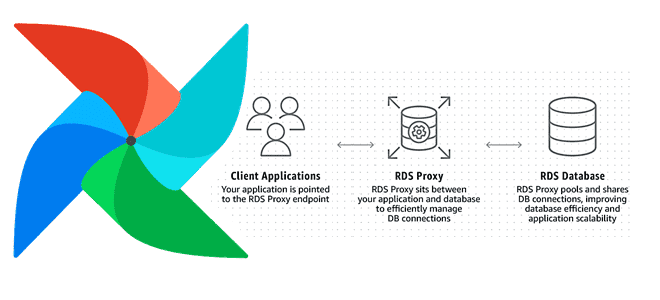
Увеличение пропускной способности и повышение скорости обработки данных на любой Big Data платформе при приемлемых затратах – одна из главных задач дата-инженера. Сегодня мы рассмотрим, как улучшить производительность множества экземпляров Apache AirFlow с помощью прокси-сервера Amazon RDS и сколько это стоит в денежном выражении: кейс компании Datafy. Больше не значит...

Cегодня рассмотрим некоторые инструменты защиты данных в Greenplum. Читайте далее про особенности шифрования в этой MPP-СУБД и лучшие практики обеспечения информационной безопасности и защиты в этой системе хранения и аналитики больших данных. Администраторы и суперпользователи Greenplum Для надежной защиты данных, хранящихся в MPP-СУБД Greenplum, и обеспечения информационной безопасности кластера рекомендуется...

Продолжая добавлять в наши практические курсы по Apache Kafka и Spark еще больше интересных примеров, сегодня рассмотрим, как с помощью этих технологий Big Data анализировать метаданные сетевых потоков в реальном времени. В этой статье мы приготовили для вас кейс по потоковой аналитики больших данных о сетевом трафике с помощью Apache...

Развивая наш новый курс «Greenplum для инженеров данных», сегодня рассмотрим, почему в этой MPP-СУБД возникают проблемы нехватки памяти, каковы типовые способы их решения и чем очереди ресурсов отличаются от ресурсных групп. Читайте далее про схемы управления ресурсами в Greenplum и особенности параметра конфигурации statement_mem. Очереди vs Группы: 2 схемы управления...

Чтобы добавить в наши практические курсы по Apache Kafka еще больше интересных примеров, сегодня рассмотрим кейс немецкой ИТ-компании Mobimeo, которая несколько раз перекраивала свою систему аналитики больших данных, чтобы быстро узнавать о событиях клиентских приложений. Читайте далее, зачем дата-инженеры Mobimeo предпочли AVRO формату JSON, почему вместо брокера сообщений ActiveMQ решили...
В этой статье поговорим про Viewflow: что такое, как устроено, чем полезно аналитикам данных и Data Scientist’ам. Встречайте новый фреймворк на базе Apache AirFlow от DataCamp – американского edu-стартапа в области ИИ, который упрощает создание и управление материализованными представлениями на SQL, R и Python в концепции low code, т.е. практически...

Сегодня разберем еще одну интересную тему из нашего нового курса «Greenplum для инженеров данных» по построению конвейеров приема данных для этой MPP-СУБД в рамках веб-интерфейса платформы автоматизированного управления потоками работ Apache NiFi. Читайте далее, как устроен коннектор VMware Tanzu Greenplum для Apache NiFi и какие возможности он предоставляет дата-инженеру. Что...

В рамках обучения аналитиков Big Data и разработчиков Apache Spark и Kafka, сегодня рассмотрим кейс ИТ-компании Southworks по онлайн-обработке потокового видео как наглядный пример эффективного сочетания этих потоковых фреймворков с пакетными задачами. Читайте далее, как реализовать лямбда-архитектуру масштабируемой Big Data системы на базе Apache Kafka, Spark Structured Streaming и NoSQL-СУБД...

Продолжая разговор про практическое обучение разработчиков Apache Spark, сегодня рассмотрим пример повышения скорости выполнения SQL-запросов к большому датафрейму. Читайте далее, как определить и исправить асимметрию распределения данных по разделам, зачем добавлять контрольные точки в длинные DAG и в чем здесь опасность, чем хороша широковещательная трансляция, для чего фильтровать данные перед...

Сегодня рассмотрим преимущества потоковой обработки данных с Apache Kafka и Flink над пакетными Big Data технологиями в виде Hadoop, Spark и Oozie. В качестве примера разберем реальный кейс аналитики больших данных по пользовательским сеансам в музыкальном онлайн-сервисе Spotify, а также возможность замены Apache Flink на Spark Structured Streaming. От рекламы...

Сегодня рассмотрим, что такое Data Build Tool, как этот ETL-инструмент связан с корпоративным хранилищем и озером данных, а также чем полезен дата-инженеру. В качестве практического примера разберем кейс подключения DBT к Apache Spark, чтобы преобразовать данные в таблице Spark SQL на Amazon Glue со схемой поверх набора файлов в AWS...

В этой статье разберем несколько популярных сценариев потоковой аналитики больших данных на Kafka, CDC-платформе Debezium и быстром OLAP-хранилище Apache Pinot. Читайте далее, почему все эти Big Data технологии отлично подходят для консолидации и интеграции данных из разных источников в реальном времени, включая аналитический аудит изменений, отслеживание событий в распределенном домене...

Чтобы сделать курсы Hadoop и Spark для инженеров данных еще более интересными, сегодня мы рассмотрим кейс фудтех-компании iFood - лидера рынка доставки еды в странах Латинской Америки. Читайте далее, в чем проблема быстрых операций со множеством файлов в облачном хранилище Amazon S3 и как ее решить с помощью префиксов корзины...

Продолжая разговор про оптимизацию приложений Apache Spark в Kubernetes, сегодня разберем, как сократить расходы на облачный кластер с помощью спотовых узлов. А в качестве практического примера рассмотрим кейс компании Weather2020, дата-инженеры которой смогли всего за 3 недели развернуть террабайтные ETL-конвейеры в AWS с AirFlow и Spark на Kubernetes без глубокой...

Сегодня рассмотрим особенности ухода с коммерческого дистрибутива Hadoop к версии сообщества на примере американской рекламной платформы Outbrain. Читайте далее, зачем дата-инженеры компании приняли такое решение, почему им не подошли альтернативы от MapR, Cloudera и Google Cloud Platform (DataProc), как проходила миграция на Apache Hadoop и что получилось в итоге. Предыстория:...
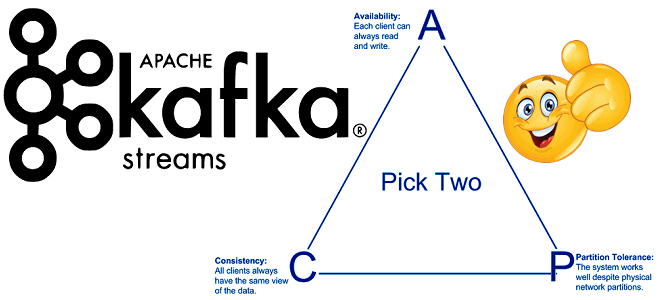
Продолжая включать интересные практические примеры в наши курсы Apache Kafka для разработчиков, сегодня поговорим о согласованности в распределенных системах с высокой доступностью. Читайте далее, что такое eventual consistency, почему это важно для микросервисной архитектуры, при чем здесь ограничения CAP-теоремы и как решить проблемы обеспечения конечной согласованности с Kafka Streams. ...
Чтобы сделать наши курсы по Apache Kafka еще более полезными, сегодня мы поговорим про базовые и расширенные возможности обеспечения информационной безопасности этой Big Data платформы. А в качестве практического примера разберем кейс международной финтех-компании BlackRock, которая разработала собственное security-решение для Kafka на базе протокола OAuth и серверов единого доступа KeyCloak....