
В октябре 2021 года российская компания «Аренадата Софтвер» выпустила новый продукт для аналитики больших данных под брендом Arenadata. Что такое Arenadata LogSearch (ADLS), при чем здесь Elasticsearch и какие потребности закрывает эта корпоративная адаптация open-source технологии полнотекстового поиска от отечественных разработчиков. Elasticsearch, OpenSearch и Arenadata LogSearch: близнецы или тройняшки? Среди...

Сегодня рассмотрим, как Uber эффективно обрабатывает миллионы запросов на поездки c помощью технологий надежного хранения и быстрой аналитики больших данных. Вас ждет краткий ликбез по системе геопространственной индексации H3 и рассказ о том, почему компания заменила NoSQL-Cassandra c компонентом Saga интеграционного фреймворка Camel на геораспределенную облачную NewSQL-СУБД Spanner от Google....
Чтобы добавить в наши курсы для дата-инженеров еще больше полезных примеров, сегодня рассмотрим, как построить конвейер преобразования CSV-файлов и загрузить данные в масштабируемую NoSQL-СУБД GridDB с помощью Apache NiFi. Краткий ликбез по GridDB и Apache NiFi в кейсе построения ML-системы для анализа данных временных рядов. Анализ данных временных рядов c...
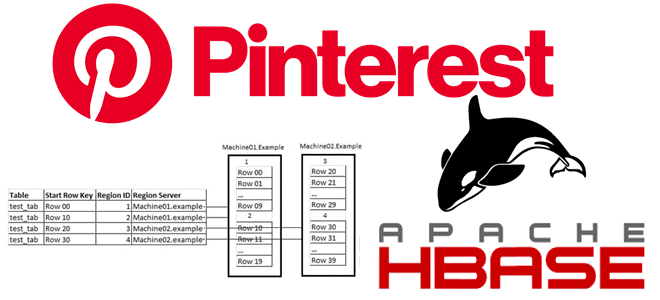
Обучая дата-инженеров и разработчиков распределенных приложений для аналитики больших данных, сегодня рассмотрим кейс компании Pinterest по построению масштабируемого решения для индексации записей в Apache HBase. Чем хранилище Ixia отличается от Lily HBase Indexer, зачем понадобился собственный аналог Solr и ElasticSearch, а также как все это работает в реальном времени с...

Рассмотрим пока еще фантастический пример из ближайшего будущего, где вся информация структурирована в виде графа знаний, доступ к сегментам которого определяется принадлежностью человека или машины к конкретной партии или корпорации. Как построить справочник организаций с помощью ИИ и графовой аналитики больших данных. Постановка задачи: построение справочника организаций Систематизация и упорядочивание...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим работу Data Science исследователей из Пизанского университета и сотрудников крупного ритейлера H&M по анализу данных торгового ассортимента компании с помощью ML-моделей на графах. Читайте далее, как машинное обучение на графовых нейросетях автоматизирует подбор сочетаемых предметов одежды и...

Сегодня в качестве полезного примера для обучения дата-инженеров и разработчиков Spark-приложений, разберем кейс компании Pinterest по интерактивной аналитике больших данных средствами SQL-модуля этого популярного фреймворка. Читайте далее, почему дата-инженеры решили заменить HiveServer2 на Spark Thrift JDBC/ODBC, зачем понадобилось писать собственный клиент поверх Apache Livy и как это было сделано. Зачем...

Сегодня рассмотрим, как методы графовой аналитики больших данных помогают бороться с эпидемией финансовых мошенничеств: выявлять номера злоумышленников, идентифицировать фрод-транзакции, выявлять и предотвращать схемы отмывания денег. Читайте далее, что под капотом AML-систем и как инструменты Data Science предотвращают злоупотребление методами социальной инженерии. Немного истории: что такое социальная инженерия и чем это...

На протяжении всей истории человечества пандемии являлись причинами глобальных макроэкономических изменений. Например, эпидемия чумы привела к окончательному падению монгольской империи, изменив баланс сил между мусульманским и европейским миром в пользу последнего. А эпидемия испанки, разразившаяся в конце первой мировой войны, привела к окончательной капитуляции Германии. Последняя пандемия COVID-19 изменила мир...

Реклама является одним из наиболее крупных сегментов практического применения технологий Big Data. Поэтому сегодня рассмотрим, как Flink SQL реализует потоковую аналитику больших данных в AdTech-кейсах. Разбираем пример JOIN-соединения двух потоков событий - показов и кликов, чтобы вычислить конверсию рекламной кампании средствами Apache Flink или Spark. Потоки Big Data за фасадом...

Сегодня рассмотрим, как построить конвейер потоковой обработки событий на Apache Kafka, Flink и SQL Stream Builder с визуализацией результатов в Grafana. Далее вас ждет практический кейс применения технологий Big Data в реальном производстве на примере телеметрии процессов ферментации продуктов в небольшой частной пивоварне. Постановка задачи: бизнес-контекст и используемые технологии В...
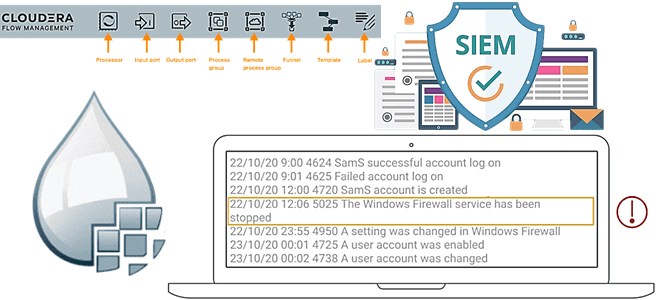
В этой статье для дата-инженеров рассмотрим, что такое Cloudera Flow Management и как это позволяет ускорить аналитику больших данных в кейсах информационной безопасности. Читайте далее о преимуществах SIEM-анализа, преобразования и распределения security-событий с помощью Apache NiFi и его легковесного агента MiNiFi для устройств интернета вещей (Internet Of Things, IoT). Что...

Продолжая разбирать кейс компании Tesla по организации централизованного управления устройствами интернета вещей (Internet of Things, IoT), сегодня разберем, как выполняется обработка сообщений в топиках Apache Kafka с помощью Confluent Schema Registry и Kafka Streams. Читайте далее, как определить потоковый процессор для парсинга данных в CSV и JSON-форматах с использованием схемы...

Чтобы дополнить наши курсы по Kafka и Spark интересными примерами, сегодня рассмотрим практический кейс разработки микросервисного конвейера машинного обучения на этих фреймворках. Читайте далее, зачем выносить ML-компонент в отдельное Python-приложение от остальной части Big Data pipeline’а, и как Docker поддерживает эту концепцию микросервисного подхода. Постановка задачи и компоненты микросервисного ML-конвейера...

Продолжая обучение основам Apache Hadoop для начинающих администраторов, сегодня рассмотрим архитектуру и принципы работы YARN в кластере. Также разберем, какие отказы могут случиться на каждом из его компонентов и как Resource Manager системы YARN обеспечивает высокую доступность кластера Apache Hadoop. Зачем Apache Hadoop нужен YARN и как он работает Поскольку...

Мы уже рассказывали про коннектор Greenplum-Spark, 2-я версия которого вышла в октябре 2020 года. А сегодня рассмотрим российскую альтернативу для отечественной MPP-СУБД Arenadata DB на базе Greenplum, выпущенную компанией Аренадата в июле 2021 года. Краткий обзор ADB-Spark Connector: архитектура, принципы работы, сценарии использования, а также отличия от PXF-фреймворка и варианта...

При том, что Apache Hadoop – высоконадежная экосистема хранения и аналитики больших данных, отказы случаются и в ней. Сегодня в рамках обучения начинающих администраторов и разработчиков Hadoop разберем, какие типы сбоев возможны в распределенной файловой системе HDFS и механизмы их предупреждения, а также рассмотрим процедуру вывода узлов из кластера для...

Продолжая разбирать тонкости сериализации данных в Apache Kafka на практических примерах, сегодня рассмотрим кейс индийской ИТ-компании Naukri Engineering о повторной обработке сообщений и особенностях форматов. Читайте далее, чем хороши заголовки Kafka и почему их не так просто использовать, а также зачем писать свой сериализатор с десериализатором для достижения 100%-ного SLA....
Добавляя в наши курсы по Apache AirFlow еще больше полезных практик, сегодня разберем опыт дата-инженеров американской компании Groupon по настройке этого фреймворка. Читайте далее, как добавить собственные KPI исполнения конвейеров обработки данных в эту workflow-платформу, делая его веб-GUI более наглядным и удобным для управления DAG’ами. Типовые возможности веб-GUI Apache Airflow...

Продолжая разбирать особенности разработки потоковых приложений Apache Flink, сегодня рассмотрим проблему падения пропускной способности задания из-за встроенного хранилища состояний RocksDB и ее зависимость от производительности дисков. Вас ждет настоящая детективная история о том, как важно заглядывать под капот облачных кластеров и настраивать конфигурации своих stateful-приложений потоковой аналитики больших данных с...