 669
669 
Содержание
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим работу Data Science исследователей из Пизанского университета и сотрудников крупного ритейлера H&M по анализу данных торгового ассортимента компании с помощью ML-моделей на графах. Читайте далее, как машинное обучение на графовых нейросетях автоматизирует подбор сочетаемых предметов одежды и обуви.
Постановка задачи: кейс ритейлера H&M
H&M – это широко известная международная корпорация, которая занимается продажей повседневной одежды, обуви и аксессуаров. Торговый ассортимент ритейлера содержит сотни тысяч товаров, которые могут быть связаны несколькими типами отношений, например, совместимость стилей, совместная покупка, совместный просмотр и пр. Точно зная связи между товарами, продавец может лучше настроить рекомендательные системы на сайте и повысить эффективность офлайн-представления товаров. Задача определения связей между различными объектами типичная для графовой аналитики, об основах которой мы писали здесь, здесь и здесь.
Применительно к кейсу H&M товары являются узлами графа торгового ассортимента, а отношения между ними – ребрами. Некоторые отношения, такие как совместимость стилей, обычно создаются вручную и не охватывают равномерно весь граф.
Для решения этой проблемы Data Science специалисты пизанского университета предложили применить методы машинного обучения, чтобы обогатить информацию об узлах графа на основе их текстового описания и визуальных изображений. Исследователи доказали, что индуктивное обучение улучшит знания о совместимости стилей товаров модного ассортимента, а дальнейшее усовершенствование графа существенно повысит производительность трансдуктивных задач с незначительным влиянием на разреженность данных.
Исходные данные о предметах одежды, обуви и аксессуарах интересны из-за их полиморфизма и сложности отношений: совместимость, транзакция, сходство, замещение и пр. Модные предметы считаются совместимыми, если их можно носить одновременно в рамках одного наряда. На практике совместимость модных предметов до сих пор чаще всего определяется вручную экспертами предметной области: дизайнерами и стилистами. Однако, когда ассортимент компании состоит из десятков тысяч наименований, а количество товарных пар растет пропорционально количеству товаров, ручная маркировка становится крайне непрактичной. Кроме того, когда в ассортименте появляются новые товары, они довольно долго отсутствуют в этом ручном анализе совместимости. Это негативно влияет на работу рекомендательных систем, которые рекомендуют покупателям дополнительные продукты.
Для автоматизации поиска отношений между множеством товаров используется индуктивное машинное обучение, основанное на выявлении общих закономерностей по частным эмпирическим данным. В отличие от трансдуктивного соединения, которое предполагает, что все узлы присутствуют во время обучения, индуктивное прогнозирование связей направлено на предсказание отношений для новых, ранее ненаблюдаемых узлов. Но индуктивное прогнозирование обычно дает низкую производительность на существующих узлах. Поэтому Data Scientist’ы решили объединить эти 2 метода, чтобы совместно использовать преимущества каждого из них. Как это было сделано, мы рассмотрим далее.
Графовая аналитика больших данных и машинное обучение
Индуктивное прогнозирование связей работает для обогащения графа новыми связями, а затем обучения трансдуктивной модели на новом графе, чтобы максимизировать производительность прогнозирования связей, получая таким образом лучшее из обоих миров. Напомним, в Machine Learning трансдуктивное обучение считается полу-контролируемым из-за частичного привлечения учителя, когда прогноз предполагается делать только для прецедентов из тестовой выборки.
Граф, узлы которого представлены товарами, а ребра – отношениями совместимости между ними, является маркированным, т.е. узлы и ребра имеют метки из текстовой и визуальной информации о товарах.
Предсказание связи между двумя узлами — фундаментальная проблема анализа данных с помощью графовых алгоритмов. В графах с атрибутами для прогнозирования связи можно использовать информацию о структуре и атрибутах. Большинство научных исследований сосредоточено на предсказании трансдуктивных связей между существующими узлами графа. Однако, в реальности, необходимо индуктивное предсказание для новых узлов, имеющих только атрибутивную информацию. Это более сложно из-за отсутствия информации о структуре новых узлов для обучения ML-модели. Эту проблему решает новая модель встраивания графов с выравниванием – DEAL (Dual-Encoder graph embedding with ALignment), для индуктивного прогнозирования связей новых узлов с использованием только атрибутивной информации. Модель встраивает узлы графа в векторное пространство и может вычислять вектор внедрения для нового узла запроса только с атрибутами, которые сравниваются с внедрением другого узла для предсказания связи.
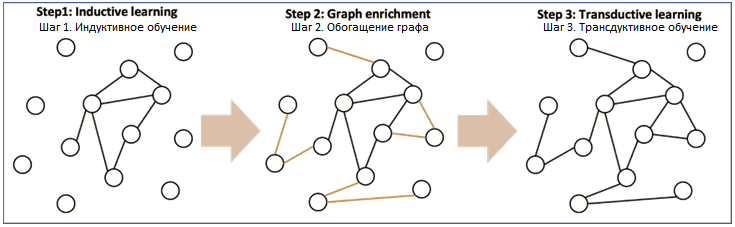
Модель DEAL состоит из трех компонентов: двух кодировщиков внедрения узлов и одного механизма выравнивания. Два кодировщика стремятся выводить встраивание узлов, ориентированных на атрибуты, и встраивание узлов, ориентированных на структуру, а механизм выравнивания выравнивает два типа встраиваний для построения связей между атрибутами и ссылками. Эта модель DEAL универсальна: она работает для индуктивного и для трансдуктивного прогнозирования связей, значительно превосходя существующие методы индуктивного и трансдуктивного прогнозирования связей. Модель машинного обучения работает следующим образом:
- на первом шаге выполняется индуктивное обучение DEAL-модели;
- далее на этапе обогащения графа к нему добавляются новые связи, если выполняются два условия: вероятность существования согласно индуктивному предсказанию связи выше порогового значения, а степень узла ниже предопределенного значения, чтобы избежать добавления слишком много ссылок;
- наконец, на шаге 3 выполняется прогнозирование трансдуктивной связи для изучения структуры расширенного графа, где отношение совместимости стилей распространено на весь граф.
Таким образом, после индуктивного обучения обученная ML-модель используется для создания обогащенного графа во второй задаче преобразования, моделируя предложения по сочетанию одежды как проблему прогнозирования связи. Расширенный граф повышает производительность прогнозирования ссылок по сравнению с исходным графом за счет небольшого уменьшения разреженности данных. Это показывает эффективность и действенность конвейера индуктивно-преобразовательных методов при решении задач аналитики больших данных на крупномасштабных разреженных графах.
Работа алгоритма успешно протестирована на двух собственных наборах данных H&M с данными о предметах мужской и женской одежды, и на общедоступном датасете Amazon. В качестве основного ML-алгоритма использовались современные графовые нейросети (GNN, Graph Neural Network): GCN (graph convolutional networks), GAT (Graph Attention Network) и SAGE. Обогащенный граф существенно улучшает производительность прогнозирования для всех трех рассматриваемых типов графовых нейросетей, делая обнаруженные шаблоны взаимосвязей более регулярными, общими и простыми для изучения.
Описанное решение пока носит экспериментальный характер, поэтому авторы исследования не сообщают, на каких технологиях Big Data это будет реализовано в production. Хотя в действительности реализация зависит от существующих компонентов текущей ИТ-инфраструктуры, потенциально при этом может использоваться Apache Spark. Этот популярный Big Data фреймворк включает пакеты машинного обучения (ML, MLLib) и графовой аналитики (GraphX, GraphFrames), о чем мы писали здесь и здесь.
Узнайте больше практических примеров графовой аналитики больших данных в бизнес-приложениях средствами Apache Spark и других инструментов Big Data на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники
- https://towardsdatascience.com/inductive-learning-for-product-assortment-graph-completion-a44306da5c42
- https://www.esann.org/sites/default/files/proceedings/2021/ES2021-73.pdf
- https://www.ijcai.org/proceedings/2020/0168.pdf

