Чтобы добавить в наши курсы для дата-инженеров еще больше полезных примеров, сегодня рассмотрим, как построить конвейер преобразования CSV-файлов и загрузить данные в масштабируемую NoSQL-СУБД GridDB с помощью Apache NiFi. Краткий ликбез по GridDB и Apache NiFi в кейсе построения ML-системы для анализа данных временных рядов.
Анализ данных временных рядов c GridDB: краткий ликбез
Предположим, необходимо построить систему обнаружения аномалий на фондовом рынке с учетом даты и время изменения цены на акции различных компаний и валюты. Это типичный кейс применения алгоритмов машинного обучения (Machine Learning) для анализа данных временных рядов. Поэтому в качестве средства хранения данных целесообразно выбрать такую систему, которая будет по умолчанию поддерживать данные временных рядов. Таким NoSQL-хранилищем является GridDB – высокопроизводительная масштабируемая key-value база данных от компании Toshiba, оптимизированная для хранения и обработки огромных объемов информации. В отличие от многих других масштабируемых NoSQL-СУБД, GridDB обеспечивает ACID-транзакции и согласованность данных на уровне контейнеров, которые аналогичны таблицам в реляционных базах. Пример интеграции GridDB с Apache Kafka через JDBC-коннектор смотрите в нашей новой статье.
Однако, чтобы данные хранились в базе, их прежде следует туда загрузить. Современные дата-инженеры используют для этого специальные инструменты – ETL-фреймворки, которые автоматизируют копирование данных из источника в место назначение, при необходимости изменяя форматы и структуру представления записей. Популярным ETL-инструментом в области Big Data сегодня считается Apache NiFi – система управления потоками данных с удобным веб-GUI и возможностью перемещения данных в реальном времени. Как это работает, мы рассмотрим далее на практическом примере построения конвейера получения данных для ML-системы.
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
25 июня, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
ETL-конвейер в реальном времени с Apache NiFi
NiFi определяет способ извлечения, преобразования и загрузки данных с помощью множества готовых процессоров и контроллеров. Процессор отвечает за задачу, входы и выходы которой определяются его сконфигурированными контроллерами. NIFI передает данные в виде потокового файла (Flow File), который может содержать любой формат: CSV, JSON, XML, текстовые или даже двоичные данные. Потоковый файл состоит из непосредственно самого содержимого (контент) и атрибутов (метаданные потокового файла, похожие на пары «ключ-значение»). Независимо от формата NIFI может распространять данные из любого источника в любое место назначения благодаря абстракции потокового файла. Можно использовать процессор для обработки файла потока, чтобы сгенерировать новый файл потока. Все процессоры вместе соединены для создания потока данных с помощью отношений (connection), которые действуют как очередь для потоковых файлов. Для упрощения разработки конвейеров можно объединить несколько процессоров в группу.
Процессор может манипулировать атрибутом потокового файла, обновляя, добавляя или удаляя атрибуты, а также изменять содержимое потокового файла. Когда процессор создает новый потоковый файл, он немедленно сохраняется на диске, и NiFi просто передает ссылку на него следующему процессору. Добавление новых данных в существующий файл потока или изменение его содержимого приведет к созданию нового файла потока, а не просто изменению метаданных.
Для каждого процессора могут быть определены отношения, в которые он направляет один или несколько потоковых файлов после завершения их обработки. Каждое отношение создает соединение с другим процессором. При наличии необработанных отношений в процессоре NIFI сообщит об этом и не позволит запустить следующий процессор, пока не будут обработаны текущие отношения.
В NIFI каждый процессор будет работать в зависимости от сложности. Чтобы справиться с ростом времени на обработку данных, NIFI имеет конфигурацию обратного давления (backpressure), позволяя определить пороговые значения для объекта и размера данных и остановить процессор при достижении любого из них.
Пусть исходные данные для обучения ML-модели (обучающий датасет) представляет собой файл в формате CSV. Тогда задача загрузки полезных данных из CSV-файла в GridDB сводится к следующим шагам:
- разделить данные на несколько таблиц на основе значения столбца записи;
- конвертировать данные в подходящую форму представления;
- объединить несколько столбцов в один;
- конвертировать даты в нужный формат.
Благодаря наличию множества готовых процессоров и графическому интерфейсу NiFi это сможет реализовать даже начинающий дата-инженер. Например, контроллер AvroRegistry определяет схемы читаемых данных, в т.ч. CSV-файла и схемы контейнера GridDB, куда эти данные следует записать. А контроллер DBCPConnectionPool отвечает за все соединения с базой данных в потоке и использует интерфейс JDBC GridDB. Он позволяет настроить все параметры соединения с GridDB: драйвер JDBC, пути JAR, URL-адреса подключения, имя пользователя и пароль.
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
25 июня, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
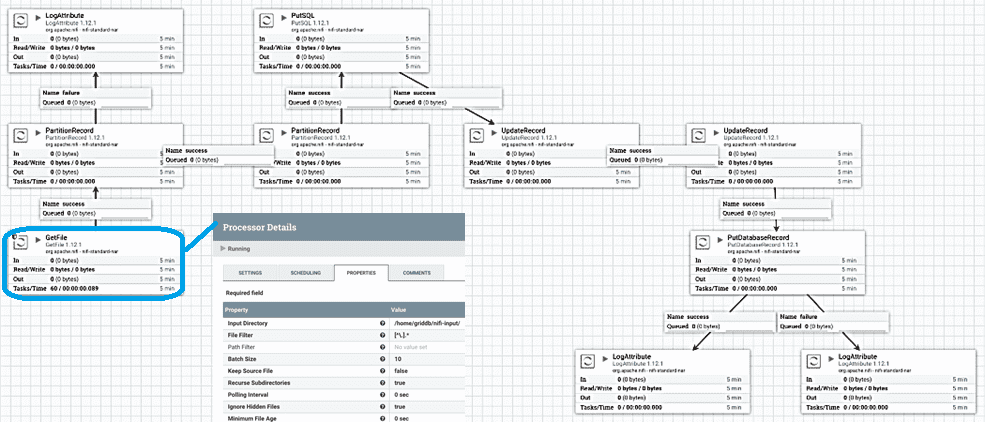
Таким образом, конвейер загрузки данных из CSV-файла в NoSQL-СУБД GridDB средствами Apache NiFi будет состоять из следующих процессоров:
- LogAttributes показывают количество неудачно или успешно обработанных записей;
- GetFile считывает CSV-файл с диска по заданным в настройках контроллера путям. Поскольку исходный CSV-файл удаляется после чтения, рекомендуется создать новый промежуточный каталог и копировать файлы по мере необходимости. Это делается с помощью контроллеров. Например, контроллер RawCSVReader используется для чтения исходного («сырого») CSV из GetFile, а контроллер RawCSVRecordSetWriter перезапишет CSV для следующего процессора в цепочке. Второй процессор PartitionRecord разделяет ввод, чтобы каждая строка CSV-файла стала одной записью. Записи по-прежнему читаются и записываются контроллерами RawCSVReader и RawCSVRecordSetWriter соответственно.
- PartitionRecord преобразует записи. В нашей схеме их два. Первый разделяет записи из потока на основе значения столбца, устанавливая для отдельных атрибутов нужные значения полей, чтобы их могли далее использовать процессоры PutDatabaseRecord и PutSQL для определения имени таблицы в приемнике данных, т.е. контейнера в GidDB;
- PutSQL – выполняет SQL-операции с атрибутами из предыдущих процессоров. В частности, создать таблицу (контейнер) в GridDB, чтобы положить туда нужные данные;
- UpdateRecord обновляет записи. В рассматриваемом конвейере их снова два. Первый процессор изменяет формат даты CSV с MM/dd/yyyy на yyyy-MM-dd, поскольку это ожидаемый формат для преобразования в метку времени в следующем процессоре. Процессор UpdateRecord объединяет поля даты и времени, а затем преобразует запись в AVRO, используя AvroRecordSetWriter в качестве вывода. Так можно преобразовать строку даты, например, 2021–02–11 18:14:17, в эпоху 1613067247, чтобы перезаписать ее в поле отметки времени процессором PutDatabaseRecord.
- PutDatabaseRecord записывает входящие записи в GridDB с помощью контроллера DBCPConnectionPool. Записи читаются с помощью контроллера AvroReader.
Про совместное использование Apache NiFi с AirFlow читайте в нашей новой статье. Другой пример ETL-конвейера смотрите здесь и здесь. А еще больше практических примеров администрирования и использования Apache NiFi для современной дата-инженерии вы узнаете на специализированных курсах для разработчиков, ИТ-архитекторов, инженеров данных, администраторов, Data Scientist’ов и аналитиков Big Data в нашем лицензированном учебном центре обучения и повышения квалификации в Москве:

