
Сегодня рассмотрим, как Uber эффективно обрабатывает миллионы запросов на поездки c помощью технологий надежного хранения и быстрой аналитики больших данных. Вас ждет краткий ликбез по системе геопространственной индексации H3 и рассказ о том, почему компания заменила NoSQL-Cassandra c компонентом Saga интеграционного фреймворка Camel на геораспределенную облачную NewSQL-СУБД Spanner от Google.
Гексагоны и графы: трудности пространственной геолокации
Одна из главных задач каршеринга и службы такси – быстро предоставить клиенту машину с учетом его геолокации. Для этого Uber использует две объекта данных: объект поставки и объект поездки, описывающие машину/такси и пользователя. Они реализованы в разных мобильных приложениях и обрабатываются разными микросервисами без совместного использования ресурсов, и синхронизация данных происходит на уровне хранилища. Геопространственный индекс хранит информацию о местонахождении водителей и клиентов, чтобы сопоставить их местонахождения для поиска ближайших доступных машин.
В Uber геопространственный индекс реализован с помощью open-source системы H3, которая делит пространство на сеть из гексагонов – шестиугольных ячеек. Несмотря на то, что поиск кратчайшего пути – это типовая задача для графовых алгоритмов, к рассматриваемому кейсу они не применимы, т.к. подъездные пути не всегда проходят по прямой. Поэтому с учетом мобильности пользователя и водителя в пределах видимости и пешего/автомобильного перемещения, лучше определять места их нахождения как ячейки на сетке правильных шестиугольников, которые полностью покрывают городскую территорию. Это не значит, что графовые алгоритмы не подходят для решения задач транспортной логистики – о том, как они успешно используются для вычисления расстояний, мы писали здесь и здесь.
Возвращаясь к кейсу Uber, отметим, что H3 включает функции преобразования координат широты и долготы, поиска центра ячеек, определения геометрии их границ и поиска соседей. Также этот иерархический геопространственный индекс поддерживает моделирование потоков и подходит для применения машинного обучения к геопространственным данным.
С геопространственным индексом не нужна специальная поддержка баз данных для хранения или извлечения данных, а основные функции хранения и доступа к ячейкам может удовлетворить практически любая СУБД. Таким образом, при обновлении локации водителя, реализация сервиса объекта поставки сводится к простому обновлению данных в базе. А сопоставление пользователей и водителей как процесс поиска доступных для клиента машин будет состоять всего из пары шагов:
- определить нужные ячейки с помощью функции geoToH3(), чтобы получить идентификатор H3-ячейки с местоположением пользователя, и вызов метода h3.kRing(), чтобы найти идентификаторы 6 соседних шестиугольников, примыкающих к ячейке клиента. Результат будет представлять собой массив из 7 строк с идентификаторами H3-ячеек: 1 – там, где находится пользователь, и 6 соседних. Для примера назовем его cells_of_interest.
- поиск в базе данных через SQL-запрос, чтобы найти близких к пользователю водителей (driver_id) из таблицы driver, значение локации которых входит в ранее полученный массив из 7 строк с идентификаторами H3-ячеек.
SELECT driver_id
FROM driver USING INDEX (driver_by_location_and_availability)
WHERE available AND location IN cells_of_interest;
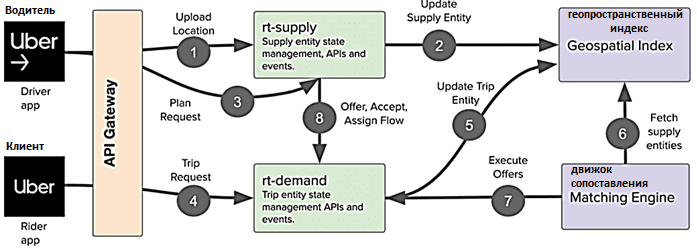
Архитектура микросервисной геоинформационной системы Uber
Итак, сервис поиска водителей Uber состоит из трех основных компонентов: службы для запуска логики мобильных приложений, базы данных и диспетчера транзакций для обеспечения согласованности. Все микросервисы работают на подах Kubernetes без совместного использования. Согласованное хеширование в NoSQL-СУБД Redis используется для разделения работы по разным экземплярам сервиса и улучшает коэффициент попадания в кэш памяти. Сами данные хранятся в высокопроизводительной и надежной NoSQL-СУБД Cassandra. А логи ведутся в топиках Apache Kafka, чтобы отслеживать изменения, внесенные в базу данных. Например, в одном сообщении указано, что местоположение водителя изменилось. Если запись в базу данных завершилась неудачно, можно просто повторно запустить команды, хранящиеся в Kafka, чтобы привести СУБД в согласованное состояние. Таким образом, Kafka выступает здесь в роли поддерживающего инструмента для повышения надежности, а не как средство интеграции микросервисов.
Для согласованной реализации распределенных транзакций поверх NoSQL-СУБД работают 2 дополнительных механизма:
- последовательная очередь в каждом экземпляре сервиса используется для упорядочивания входящих запросов;
- компонент интеграционного фреймворка Camel, Saga используется для реализации распределенной транзакции, когда нужно обновить несколько записей атомарно. Например, когда водитель принимает заказ, необходимо обновить объект водителя и объект пользователя в рамках одной транзакции. Иначе база данных может остаться в несогласованном состоянии, когда со стороны пользователя запрос принимается водителем, а со стороны водителя запрос не принимается. Saga предоставляет способ определить серию связанных действий в маршруте Camel, которые должны быть либо успешно завершены или компенсированы. Это позволяет координировать обмен данными распределенных сервисов для достижения глобально согласованного результата.
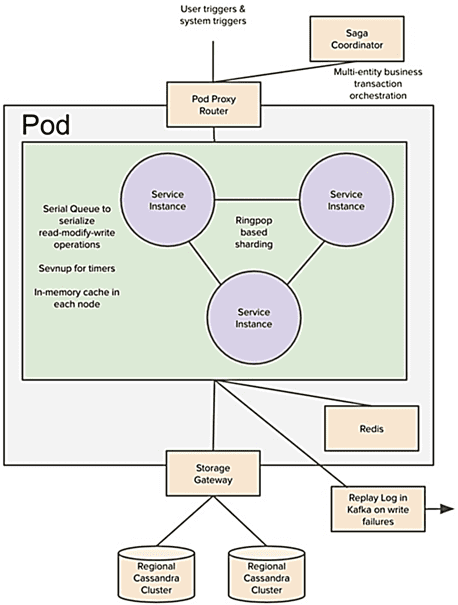
Проблемы NoSQL-баз и их решения со Spanner
Из-за того, что NoSQL-СУБД не поддерживает индексы и распределенные транзакции, Uber использует отдельную таблицу для хранения индекса. Как отмечено выше, за обеспечение согласованности данных в таблице данных и таблице индексов, отвечает компонент Saga, который разбивает большую транзакцию на несколько мелких. Прикладной уровень Saga генерирует компенсационную транзакцию для каждого изменения и координирует процесс фиксации и прерывания транзакции. На практике оказалось, что этот подход с зависимыми обновлениями таблиц и фиксацией компенсирующих транзакций усложняет архитектуру системе, не гарантируя 100%-ную согласованность данных. А утечка логики транзакций базы данных на уровень приложения дополнительно усложняет бизнес-логику.
Поэтому ИТ-архитекторы Uber решили использовать СУБД, которая сможет обеспечить масштабируемость NoSQL, но с поддержкой индексов и распределенных транзакций. Это возможно с системами класса NewSQL, из которых Uber выбрал облачный сервис Google Cloud Spanner. Эта геораспределенная СУБД от Google позиционируется как развитие BigTable: поддерживается язык SQL, но не является чисто реляционной. Каждая таблица Spanner должна обязательно иметь первичный ключ. Поддерживая согласованность распределенных транзакций, Spanner отлично масштабируется и используется внутри инфраструктуры Google как часть ее облачной платформы (GCP, Google Cloud Platform).
Spanner хранит данные в сопоставлении ключ/значение: (key:string, timestamp:int64) → value:string, поддерживает вторичную индексацию и быстрый доступ к данным. С этой СУБД архитектура всей системы становится проще:
- Google Cloud Spanner реплицируется в нескольких регионах для обеспечения высокой доступности и надежности;
- чтобы обновить местоположение водителя, исполняющий сервис должен всего лишь обновить местоположение в соответствующей таблице;
- индекс автоматически обновится с помощью Spanner.
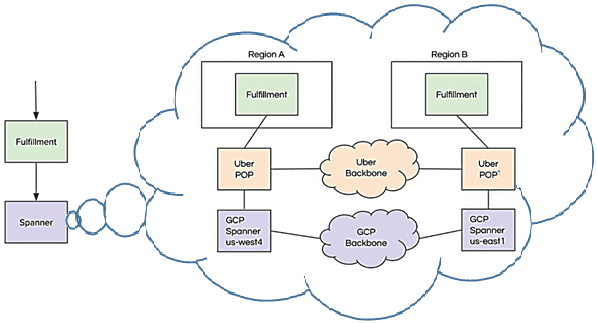
Таким образом, чтобы найти ближайших водителей для пользователя, уровень приложения может напрямую отправить запрос SQL в Spanner, как было рассмотрено выше. Однако, кроме достоинств, описанное решение имеет некоторые недостатки или ограничения, которые разработчики частично устранили. В частности, стандартный клиент Spanner не обеспечивает асинхронной поддержки для исполняющего сервиса, а поддержка DML оказалась недостаточной. Поэтому команда Uber создала собственный клиент Spanner, который имеет больше специфических настроек, перехватывает gRPC для улучшения наблюдаемости и объединяет транзакции для увеличения пропускной способности.
Также Uber разработал для Google Cloud Spanner собственное решения для сбора измененных данных (CDC, Change Data Capture) с использованием таблицы для хранения асинхронных задач как в очереди. Обновление таблицы сущностей и вставка задачи в очередь выполняются внутри одной транзакции Spanner, которая периодически просматривается для обнаружения новых задач и их отправки на исполнение в распределенном режиме.
Узнайте больше практических примеров графовой аналитики больших данных в бизнес-приложениях, а также лучшие практики работы с NoSQL-решениями на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники
- https://megtechcorner.medium.com/how-uber-handles-millions-of-ride-food-requests-efficiently-part-1-2aa8db436204
- https://h3geo.org/docs/
- https://medium.com/nerd-for-tech/how-uber-handles-millions-of-ride-food-requests-efficiently-part-2-270f84d2c3c0
- https://ru.bmstu.wiki/Google_Cloud_Spanner
- https://camel.apache.org/components/next/eips/saga-eip.html

