 1143
1143 
Содержание
Сегодня в качестве полезного примера для обучения дата-инженеров и разработчиков Spark-приложений, разберем кейс компании Pinterest по интерактивной аналитике больших данных средствами SQL-модуля этого популярного фреймворка. Читайте далее, почему дата-инженеры решили заменить HiveServer2 на Spark Thrift JDBC/ODBC, зачем понадобилось писать собственный клиент поверх Apache Livy и как это было сделано.
Зачем это нужно: предыстория миграции от Hive к Spark
Более 475 миллионов человек в месяц активно используют популярный фотохостинг Pinterest в качестве соцсети. Чтобы лучше понимать интересы своих клиентов и получать больше выгоды от рекламодателей, Pinterest развернул собственную масштабируемую платформу интерактивных запросов на базе Apache Spark SQL. Ежедневно она обрабатывает сотни петабайт данных, обеспечивая выполнение запланированных и интерактивных запросов.
Запланированные запросы выполняются по расписанию с заранее определенной частотой и обычно имеют строгие цели уровня обслуживания (SLO, Service Level Objectives), про которые мы рассказывали здесь. А интерактивные запросы выполняются по мере необходимости и обычно не имеют строго заданной периодичности. В отличие от запланированных запросов, пользователи ждут завершения интерактивных запросов, не зная о потенциальных проблемах, которые могут вызвать сбои.
Изначально Pinterest использовал Apache Hive, Presto и Spark SQL для аналитики больших данных, но постепенно компания отказываемся от Hive в пользу Spark SQL, оставляя Presto для быстрых интерактивных запросов, а Spark SQL — для всех запланированных и интерактивных запросов к большим наборам данных. При этом применяется сервер Apache Spark Thrift JDBC/ODBC, похожий на HiveServer2, чтобы выполнять клиентские запросы Spark SQL по протоколам JDBC/ODBC. Использование сервера Spark Thrift позволит существующим инструментам поддержки протокола JDBC/ODBC беспрепятственно работать со Spark SQL. Но этот подход не обеспечивает нужной изоляции между запросами, отправленными на один и тот же Thrift-сервер. Поэтому в случае проблем на нем это может повлиять на все другие запросы.
Ранее, используя Hiveserver2 для интерактивных запросов, дата-инженеры Pinterest столкнулись с проблемами, когда неправильный запрос приводил к отключению всего сервера и сбою всех запросов, выполняемых одновременно. Чаще всего это было вызвано выполнением одного запроса в локальном режиме с оптимизацией запросов, которая занимала слишком много памяти, или запросом, загружающим собственный jar-файл и вызывающим сбоя ядра на сервере. Поэтому было решено заменить Hiveserver2 на аналогичный инструмент фреймворка Spark. Как это было сделано, мы рассмотрим далее.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
21 сентября, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Синергия Apache Livy и Spark SQL
Однако, с Apache Spark оказалось все не так просто. Один из распространенных механизмов выполнения SQL-запросов в этом фреймворке – интерфейс командной строки (CLI, Command Line Interface). Но этот подход не очень подходит для интерактивных приложений и непосредственных пользователей. Вместо этого можно создать сервис, который запускает CLI spark-sql как shell-приложение в кластере YARN от различных клиентов. Однако, это приводит к накладным расходам на ожидание выделения контейнера в кластере YARN и последующему запуску сеанса Spark для каждого запроса. Весь процесс может занять до нескольких минут, в зависимости от доступности ресурсов в кластере. Разумеется, этот вариант не подойдет для интерактивных запросов. Кроме того, в этом случае усложняется получение результатов, предоставление обновлений хода выполнения на уровне операторов и трассировка стека исключений из логов драйверов в случае сбоя. Поэтому дата-инженеры Pinterest решили улучшить взаимодействие с кластером Spark с помощью RESTful-интерфейса Apache Livy, о котором мы рассказывали в этих статьях.
Итак, с помощью Livy можно легко отправлять SQL-запросы SQL в кластер YARN и управлять контекстом Spark с помощью простых вызовов REST, получая абстракцию над сложной инфраструктурой Apache Spark, которая обеспечивает прямую интеграцию с клиентами и пользователями.
Livy предоставляет два варианта сеансов для отправки заданий:
- пакетный – похожий на Spark-submit для отправки пакетных приложений, где все операторы запроса запускаются вместе. Это затрудняет использование некоторых функций интерактивных запросов, например, выбор вариантов запуска оператора, изменения сеанса Spark с помощью операторов SQL, создание многоразовых пользовательских сеансов и кэширование.
- интерактивный – позволяет запускать сеанс, отдельно отправляя запросы и операторы, а также явно заканчивать сеанс по мере надобности.
Также Livy обеспечивает мультитенантность, высокую доступность за счет восстановления сеанса и изоляцию отказов. Поэтому именно этот инструмент был выбран для реализации интерактивных запросов Spark SQL в Pinterest.
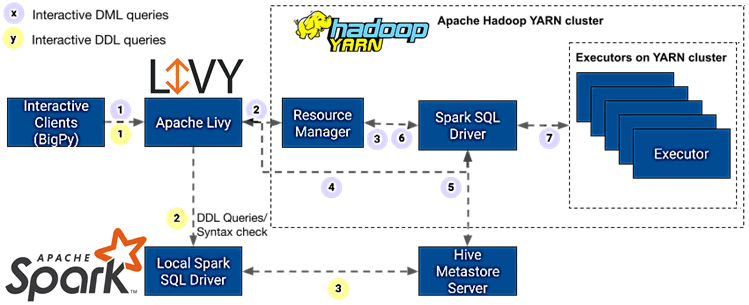
Примечательно, что запросы описания данных (DDL, Data Definition Language) обрабатываются отдельно от запросов манипулирования данными (DML, Data Manipulation Language). Вот как это реализовано для DML-запросов:
- клиенты Querybook и Jupyter отправляют Livy интерактивные DML-запросы;
- Livy запрашивает контейнер у диспетчера ресурсов YARN для запуска клиента удаленного контекста Spark;
- диспетчер ресурсов YARN выделяет контейнер, где запускается клиент удаленного контекста Spark, который затем запускает программу своего драйвера;
- Livy отслеживает ход выполнения запроса, связываясь с клиентом удаленного контекста Spark, у которого запущена программа драйвера;
- драйвер Spark SQL получает метаданные таблицы по мере необходимости для планирования запросов из Hive Metastore Service;
- драйвер запрашивает у диспетчера ресурсов YARN контейнеры для запуска исполнителей с учетом потребностей;
- драйвер Spark SQL назначает задачи и координирует работу между исполнителями до тех пор, пока не будут завершены все задания Spark для пользовательского запроса.
Последовательность выполнения интерактивных DDL-запросов выглядит так:
- клиенты отправляют Livy интерактивные DDL-запросы;
- Livy получает сеанс Spark из пула локальных сеансов и обновляет учетные данные текущего пользователя;
- локальный драйвер Spark SQL получает метаданные таблицы для планирования запросов от Hive Metastore Service и выполняет DDL-операции по мере необходимости.
Оказалось, что этот вариант решения имеет некоторые проблемы. В частности, требовался универсальный стандартный интерфейс отправки пользовательских запросов от любого клиента, который можно использовать в качестве промежуточной зависимости для простого взаимодействия с Livy. Поэтому дата-инженеры Pinterest поверх Livy разработали BigPy – общий клиент Python, совместимый с DB-API. BigPy отслеживает состояние сеанса Livy и сообщает клиентам о том, как ведет себя приложение: выполнилось успешно или с ошибкой, или же выполняется в текущий момент. Также BigPy отвечает за отслеживание состояния Spark-приложения, возвращая ссылки на пользовательский интерфейс, логи драйверов и внешнюю систему мониторинга производительности и настройки приложений под названием Dr. Elephant. Dr. Elephant разработан для мониторинга производительности и настройки Hadoop и Spark: автоматически собирает все метрики, анализирует их и представляет в простой форме для удобного использования. Его цель — повысить продуктивность разработчиков и повысить эффективность кластера за счет упрощения настройки рабочих мест. Он анализирует задания Hadoop и Spark с помощью набора подключаемых настраиваемых эвристик на основе правил, которые дают представление о том, как выполняется задание, а затем использует результаты, чтобы внести предложения о том, как настроить задание, чтобы оно выполнялось более эффективно.
Наконец, BigPy предоставляет возможность извлекать результаты запросов с разбивкой на страницы из хранилища объектов, такого как AWS S3 и возвращает исключения непосредственно от клиентов, упрощая отладку. Таким образом, BigPy позволил использовать модульный способ взаимодействия с Livy в нескольких различных системах, обеспечивая четкое разделение задач и клиентского кода.
Утилита spark-shell отправляет запрос приложения YARN в диспетчер ресурсов в кластерном режиме. Диспетчер ресурсов YARN запускает мастер приложений, который запускает программу драйвера. Она запрашивает у диспетчера ресурсов дополнительные контейнеры, которые используются для запуска исполнителей. Этот процесс выделения ресурсов может занимать до нескольких минут для начала обработки каждого запроса, добавляя значительную задержку к DDL-запросам метаданных, которые обычно выполняются быстро. Запросы DDL выполняются в драйвере и не требуют дополнительных исполнителей или такой же степени изоляции, как DML-запросы. Чтобы уменьшить избыточную задержку выделения контейнеров в кластере YARN и время запуска сеанса Spark, был реализован локальный пул сеансов в Apache Livy, который поддерживает пул сеансов Spark в локальном режиме.
Сперва нужно было идентифицировать запрос как оператор DDL и реализовать кэшированный пул приложений Spark для его обработки. Это сделано с помощью парсера Spark SQL, чтобы получить логический плана пользовательского запроса, который представляет собой просто дерево логических операторов, унаследованных от класса TreeNode. Пройдя по этому дереву и проверив класс каждого узла на соответствие набору команд выполнения DDL, можно идентифицировать запрос. Программный код для этого выглядит примерно так:
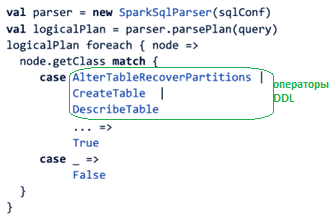
Если запрос является оператором DDL, он отправляется в одно из кэшированных Spark-приложений, пул которых представлен в Livy как набор локально запускаемых программ драйверов Spark. Этот пул полностью автономен и включает следующие функции:
- автоматическая сборка мусора устаревших приложений и запуск новых;
- поток системной службы, отслеживающей работоспособность пула и перенаправляющей запросы к следующему доступному приложению;
- перезапуск приложений с настраиваемой частотой, чтобы убедиться, что он использует самые свежие ресурсы (например, jar-файлы схемы) для гарантии актуальности данных;
- асинхронный запуск облегченной операции с метаданными во время запуска для инициализации контекста Spark и установления активного соединения с хранилищем метаданных для более быстрых последующих операций.
Это решение позволило сократить задержку выполнения SQL-запроса примерно в 7 раз, с 70 секунд до 10 секунд в среднем.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
21 сентября, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Еще несколько улучшений для ускорения аналитики больших данных
Одним из недостатков выполнения каждого запроса в кластерном режиме является то, что проверка синтаксиса может занять столько времени, сколько нужно для запуска приложения. Смягчить эту проблему поможет парсер Spark SQL, который дает логический план запроса перед запуском приложения YARN. Если запрос содержит синтаксическую ошибку, синтаксический анализатор сгенерирует исключение ParseException при генерации логического плана, вернув номер строки и столбца. Это позволило сократить общую задержку проверки синтаксиса в 30 раз, с нескольких минут до менее двух секунд.
В результате этих и других решений система Pinterest ежедневно обрабатывает около 1500 интерактивных запросов Spark SQL, поддерживая SLO безотказной работы 99,5% для Livy. При этом была решена проблема эффективной балансировки нагрузки для Livy, который по сути является веб-сервисом с отслеживанием состояния, храня в памяти состояние сеанса: выполнение запроса, статус, окончательный результат и пр. Когда много клиентов используют механизм HTTP-опроса для получения этих свойств, добавить классический балансировщик нагрузки приложения становится не так просто. Для этого был реализован алгоритм балансировки нагрузки на уровне приложения, который направляет каждый запрос наименее загруженному экземпляру Livy в циклическом режиме. Загруженность определяется количеством активных сессий, запущенных на конкретном экземпляре Livy.
А для быстрой отладки добавлена поддержка слушателей событий в Livy. Событие определяется как любое действие, включая создание сеанса и отправку оператора сеансам, а также запись объектов JSON на локальный диск. Такой мониторинг помогает быстро решить проблемы в случае случайных сбоев. В следующий раз мы продолжим разбирать кейс Pinterest и рассмотрим подробнее, какие именно решения были предложены для предотвращения отказов Spark SQL и Livy. А о том, как дата-инженеры компании организовали вторичную индексацию в Apache HBase, читайте в новой статье.
А практически освоить все возможности Apache Spark и Livy для разработки распределенных приложений и аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Построение эффективных конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
Источники

