 1113
1113 
Содержание
Сегодня рассмотрим, как построить конвейер потоковой обработки событий на Apache Kafka, Flink и SQL Stream Builder с визуализацией результатов в Grafana. Далее вас ждет практический кейс применения технологий Big Data в реальном производстве на примере телеметрии процессов ферментации продуктов в небольшой частной пивоварне.
Постановка задачи: бизнес-контекст и используемые технологии
В процессе создания пива есть 2 ключевых этапа:
- замачивание зерна для образования сусла и его кипячение, чтобы получить сахарный раствор, который, по сути, является кормом для дрожжей;
- брожение сусла, которое должно храниться при определенной температуре в течение времени, пока дрожжи потребляют сахар, выделяя спирт и создавая конечный продукт.
Брожение считается самой сложной фазой, т.к. малейшее изменение условий (тепература, влажность и пр.) может негативно сказаться на качестве результата. Поэтому пивоварам необходимо постоянно следить за температурой внутри емкости и снаружи, а также за удельным весом самого сусла. Телеметрия даст возможность убедиться, что поддерживается нужная температура, а также позволит понять, когда процесс брожения завершен, и можно приступить к следующему этапу производства – кегирование и карбонизизация.
На практике чаще всего для измерения физических параметров жидкостей используются ареометры (приборы для измерения плотности жидкостей и твёрдых тел по принципу Закона Архимеда) или гидрометры – устройства, которые представляют собой специальные погружные датчики. Они плавают в сусле, фиксируя показания температуры и удельного веса. Некоторые из них представляют собой весьма интеллектуальные устройства, включая передатчик Bluetooth и вычислительные модули в контроллерах типа Rasberry PI. Таким образом, подобные датчики можно считать примером конечного IoT-устройства, передающего данные о параметрах технологического процесса брожения в платформу обработки событий интернета вещей, роль которой играет Apache Kafka.
Данные извлекаются из датчика, и API-интерфейс продюсера Kafka передает их далее по конвейеру для последующей обработки. Наиболее важными данными от каждого датчика являются его идентификатор (каноническое имя), температура, метка времени и значение удельного веса (sg). Именно эти параметры (температура и удельный вес) и необходимо отслеживать бизнес-пользователям (т.е. пивоварам) [1]. В качестве средства отображения можно использовать Grafana – мощную open-source платформу визуализации, мониторинга и анализа данных временных рядов. Она поддерживает множество источников данных (Graphite, Elasticsearch, Cloudwatch, Prometheus, InfluxDB и пр.) с настраиваемым редактором запросов и специальный синтаксисом для каждого. Предоставляя множество наглядных графиков, Grafana имеет ряд ограничений, которые осложняют применение этой системы в рассматриваемом кейсе [2]. Об этом мы поговорим далее.
Как передать данные из Apache Kafka в Grafana: архитектура системы телеметрии
Grafana не хранит отображаемые данные временных рядов, обеспечивая только их визуализацию. Несмотря на наличие встроенного механизма оповещения по электронной почте или уведомлений через Slack по определенным правилам, эта система не поддерживает сбор данных, управление тревогами и непосредственное отслеживание событий, предоставляя лишь косвенные способы преобразования логов в числовые метрики, важные для мониторинга [2].
Однако для рассматриваемого кейса телеметрии производственного процесса ферментации наиболее значимо отсутствие в Grafana возможности управлять потоком входящих данных. Поэтому при потреблении потока данных нужен способ материализовать его последнее состояние по ключу. Для этого к Grafana можно подключить SQL Stream Builder, чтобы контролировать поток данных из Kafka, и упростить создание дэшбордов. SQL Stream Builder (SSB) использует непрерывный SQL и материализованные представления для простой очистки, агрегирования и организации данных для представления в Grafana.
Представляя собой комплексный интерфейс для создания заданий потоковой обработки с отслеживанием состояния с использованием языка структурированных запросов, SQL Stream Builder является компонентом Cloudera Streaming Analytics. Он позволяет просто объявлять выражения, которые фильтруют, объединяют, маршрутизируют и обогащают потоки данных в интерактивном режиме. Выполненные SQL-запросы выполняются как задания в кластере Flink, оперируя неограниченными потоками данных до тех пор, пока они не будут отменены. Так можно создавать, запускать и отслеживать задания потоковой обработки в SSB, поскольку каждый SQL-запрос является заданием Flink.
Непрерывный SQL создает вычисления с неограниченными потоками данных и сохранения материализованных представлений в постоянном хранилище, чтобы использовать их в сторонних приложениях для аналитической визуализации. При определении задания в SSB оператор SQL интерпретируется и проверяется на соответствие схеме. После выполнения оператора постоянно возвращаются результаты, соответствующие критериям [3].
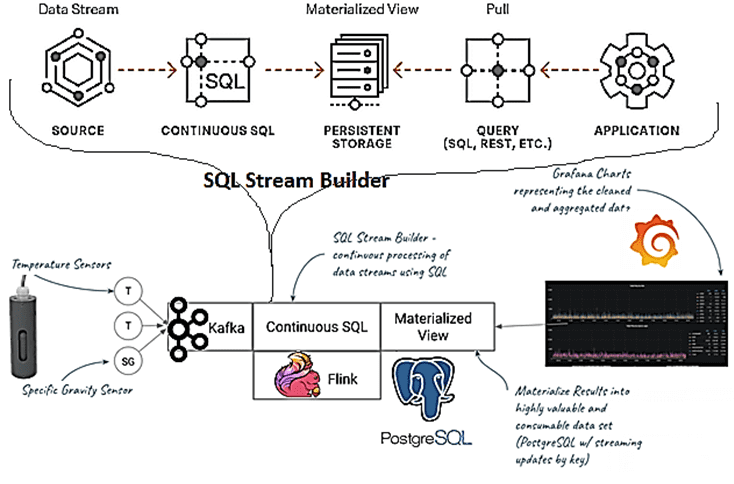
Что внутри SQL Stream Builder и при чем здесь Apache Flink: краткий обзор архитектуры и принципов работы
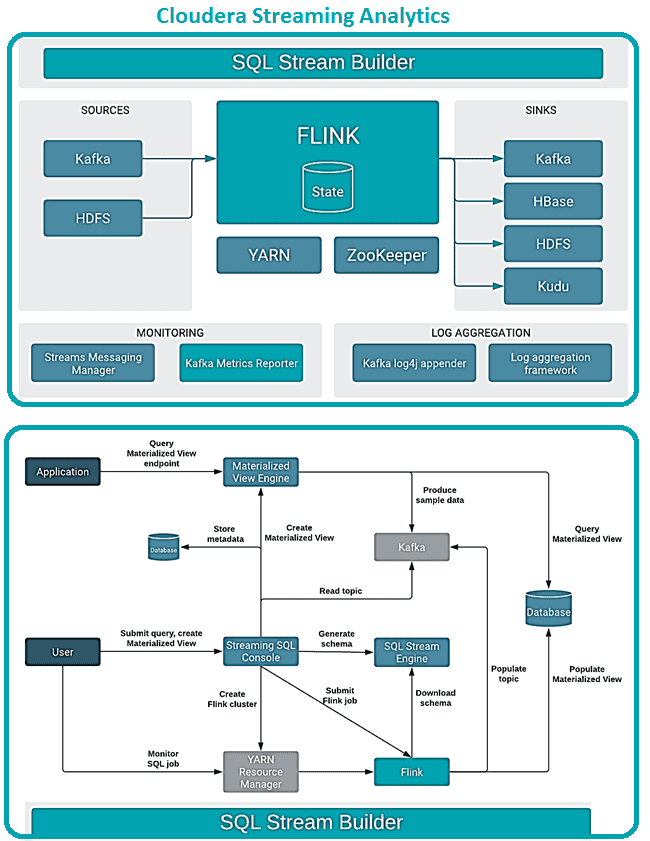
SQL Stream Builder интегрирован в платформу Cloudera, включающую Apache Flink, Kafka, Schema Registry и YARN. Основной точкой взаимодействия пользователя с SQL Stream Builder является GUI-консоль Streaming SQL Console. После отправки пользовательского запроса через GUI в кластере в фоновом режиме создается задание Flink. Схема, соответствующая запросу, загружается через реестр схем (Schema Registry). Топик Kafka также заполняется отправкой задания Flink, отслеживать и управлять которыми можно с помощью диспетчера ресурсов YARN или панели инструментов.
SSB также требует сервиса Kafka в том же кластере для автоматического заполнения топиков вывода веб-сокета. Выходные данные веб-сокета необходимы для выбора данных в консоли, когда приемник предлагаемых приложений не добавлен в запрос SQL.
При отправке SQL-запроса, Flink генерирует данные в базе данных материализованных представлений, запрашивая нужную информацию. Консоль Streaming SQL и материализованные данные представления представлены в базах данных, где хранятся метаданные заданий SQL, а механизмы материализованного представления представляют данные для создания представлений. SSB поддерживает MySQL или MariaDB и PostgreSQL в качестве баз данных [4].
Возвращаясь к рассматриваемому кейсу, отметим необходимость создания схемы данных. Это можно сделать, создав новую таблицу Apache Kafka и используя функцию определения схемы SQL Stream Builder для создания схемы из данных JSON. В качестве метки времени в операциях SQL будет использоваться атрибут ts, значения которого передают ареометры. Непрерывное задание SQL будет агрегировать данные и преобразовывать их в материализованное представление подобно push-запросу, чтобы трансформировать поток входящих данных в полезные бакеты.
Таким образом можно агрегировать данные в 10-минутных окнах, чтобы найти среднее значение для плотности сусла, а также минимальную и максимальную температуру с помощью стандартных SQL-функций AVG(), MAX() и MIN().
Определив материализованное представление, можно приступать к настройке панелей мониторинга Grafana. При этом первичный ключ материализованного представления должен включать временную метку и время события как логический ключ. Поскольку это данные временного ряда, эти два ключа объединить, чтобы получить первичный ключ. После указания параметров материализованного представления в SQL Stream Builder и выполнения запроса, данные будут объединены и сохранены, а также доступны из Grafana через pull-запрос.
Теперь, наконец, можно создать дэшборды для отображения данных в различных логических представлениях, полезных для бизнеса. В частности, показать временные ряды температуры и удельного веса сусла, а также отображать ключевые сигналы тревоги, когда что-то пойдет не так.
SQL-запрос для отображения данных временных рядов в Grafana будет выглядеть так [1]:
— grafana pull query from MV
SELECT
extract(epoch from ts) AS «time»,
‘fermenter_’||cast(sensor_number as varchar) as «metric»,
mintemp as «temp»
FROM brewhouse
WHERE
$__timeFilter(ts)
ORDER BY 1
Таким образом, небольшой конвейер потоковой обработки событий на Apache Kafka, Flink и SQL Stream Builder позволил реализовать телеметрию процессов пивоварения, чтобы наблюдать за критически важными параметрами ферментации и мгновенно реагировать на любые отклонения их от нужных значений [1]. Другой интересный кейс потоковой аналитики Big Data средствами Apache Flink SQL читайте в нашей новой статье.
Освоить тонкости потоковой аналитики больших данных с Apache Kafka вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://medium.com/cloudera-inc/streaming-data-for-brewery-ops-with-grafana-7aa722f3421
- https://dataenginer.ru/?p=1454
- https://docs.cloudera.com/csa/1.3.0/ssb-overview/topics/csa-ssb-intro/
- https://docs.cloudera.com/csa/1.3.0/ssb-overview/topics/csa-ssb-architecture/

