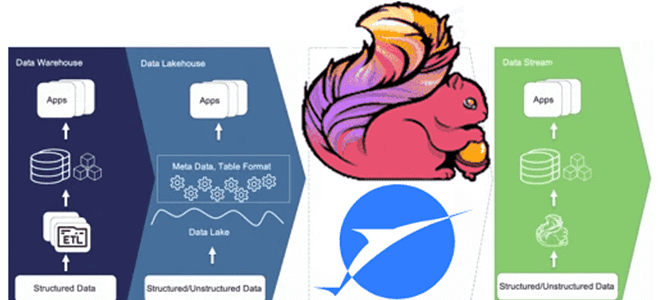
Что не так с архитектурой данных Lakehouse, зачем разработчики Apache Flink создали на основе табличного хранилища новую дата-платформу, чем хорош подход Streamhouse и как устроен Apache Paimon.
Что такое архитектура данных Streamhouse
Не успели дата-архитекторы освоиться с Lakehouse – архитектурой данных, которая объединяет преимущества хранилищ и озер данных, комбинируя масштабируемость и гибкость с метаданными и табличными форматами, как появился новый подход. Архитектура Lakehouse, о которой мы писали здесь и здесь, демонстрируют ежедневную или ежечасную задержку передачи данных. А потоковая передача данных обеспечивает высокую скорость с задержкой обработки порядка нескольких миллисекунд. Обработка больших объемов данных всегда представляет собой компромисс между стоимостью и задержкой.
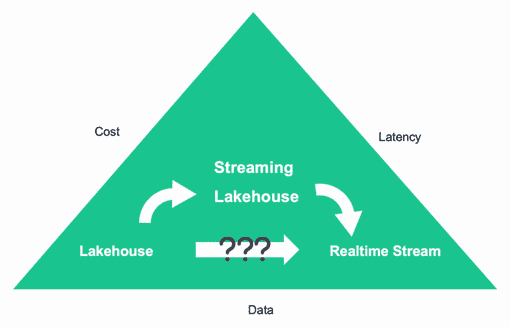
Если в приоритете стоимость, следует выбирать Lakehouse, а когда важнее сократить задержку, потоковая передача в реальном времени становится более предпочтительным вариантом.
Однако, на практике не всегда можно сделать однозначный выбор из-за многообразия бизнес-сценариев, которые должно поддерживать хранилище данных. Чтобы не делать однобокий выбор, разработчики Apache Flink из компании Ververica предложили новую архитектуру данных под названием Streamhouse. Как видно из названия, она объединяет подход Lakehouse с потоковой обработкой, предоставляя решение для обновления пакетных заданий с задержкой, близкой к реальному времени. Streamhouse обрабатывает данные как в пакетном, так и в потоковом режиме, при этом формат таблицы соответствует концепциям потоковой передачи. Хотя данные можно сохранять в многоуровневом объектном хранилище, в большинстве случаев обычно достаточно экономичного объектного хранилища.
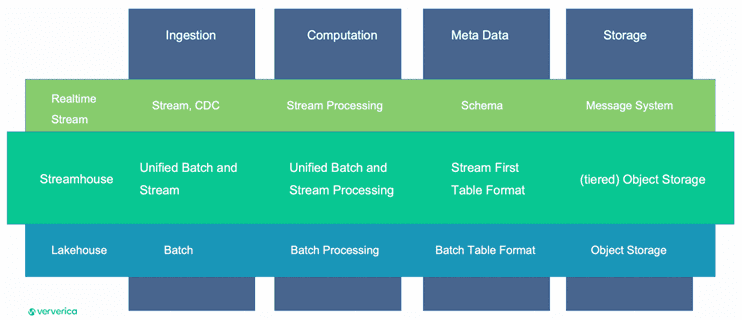
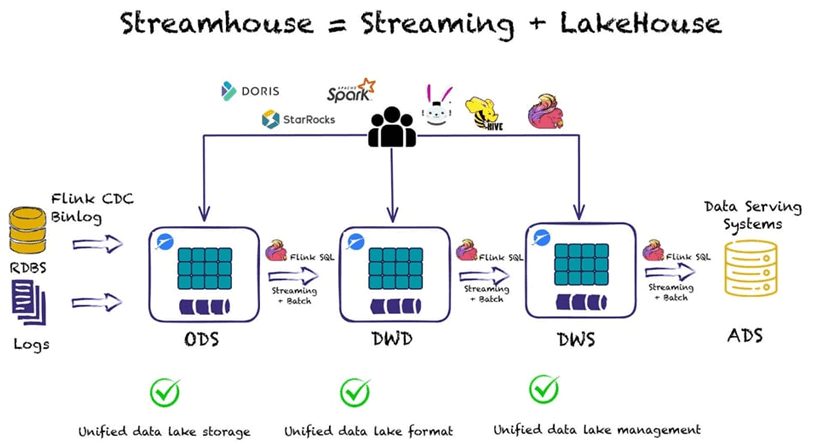
Архитектура Streamhouse основана на Apache Flink для потоковой обработки и Apache Paimon в качестве уровня потокового хранения. Основная идея Streamhouse — потоковая передача ETL и получение данных из CDC или запись данных журнала в дешевое хранилище типа AWS S3, HDFS и пр., простым способом с использованием однострочного оператора. Когда данные попадают в озеро данных, пользователи могут создавать разные задания для создания разных бизнес-уровней, т. е. ODS, DWD, DWS и ADS, которые обеспечивают обновления во время потока данных. В то же время можно добавить любой механизм запросов сверху, поскольку данные доступны напрямую. В частности, можно добавить OLAP-системы, такие как Apache Doris и StarRocks, или механизмы запросов, такие как Flink SQL, Spark, Trino или Hive для выполнения пакетных или инкрементальных запросов.
Таким образом, Streamhouse поддерживает все уровни корпоративного хранилища данных:
- хранилище операционных данных (ODS, Operational Data Store) для получения и обработки необработанных данных, которые необходимо сохранить в хранилище данных. Структура таблицы данных на уровне ODS такая же, как и структура таблицы данных, в которой хранятся необработанные данные. Уровень ODS служит промежуточной областью для хранилища данных.
- измерения (DIM, Dimension), где модели данных строятся на основе измерений. В таблицах определяются первичные ключи и атрибуты, а также связи с другими измерениями. Это обеспечивает согласованность данных при анализе данных и снижает риски несогласованности спецификаций и алгоритмов расчета.
- детальное хранилища данных (DWD, Data Warehouse Detail), где модели данных строятся на основе домена, т.е. деятельности предприятия. Можно создать таблицу фактов, которая использует самый высокий уровень детализации на основе характеристик конкретной бизнес-деятельности. Здесь можно дублировать некоторые ключевые поля атрибутов измерений в таблицах фактов и создавать широкие таблицы на основе привычек использования данных на предприятии. Также можно сократить количество связей таблицы фактов с таблицами измерений, чтобы повысить удобство использования таблиц фактов.
- сводка хранилища данных (DWS, Data Warehouse Summary), где модели данных строятся на основе конкретных предметных объектов, которые надо проанализировать. Можно создать общую сводную таблицу на основе требований к метрикам приложений и продуктов верхнего уровня.
- прикладные сервисы данных (ADS, Application Data Service) для хранения метрических данных продуктов и создания различных отчетов.
Познакомившись с назначением и историей возникновения новой архитектуры данных, далее рассмотрим, что представляет собой Streamhouse с технической точки зрения.
Apache Flink и Paimon
Apache Flink позволяет работать с динамическими таблицами, которые напоминают материализованные представления в базах данных. Однако, в отличие от материализованных представлений, динамические таблицы не подлежат прямым запросам. Чтобы обойти это ограничение, было предложено встроенное хранилище динамических таблиц. Впоследствии эта идея из фичи Apache Flink под названием Flink Table Store, о котором мы писали здесь, превратилась в отдельный проект под названием Paimon. Эта инициатива стала проектом фонда Apache и сегодня находится в стадии инкубации. По сути, Apache Paimon – это уровень хранения для Flink, который использует формат таблицы, позволяя напрямую обращаться к промежуточным данным в динамических таблицах. Это похоже на архитектуру Lakehouse, также поддерживает потоковую передачу данных и быстрые аналитические запросы, включая интеграцию с универсальными концепциями Flink и захват измененных данных CDC (Change Data Capture).
Apache Paimon — это платформа потокового озера данных, которая поддерживает высокоскоростной прием данных, отслеживание изменений данных и эффективную аналитику в реальном времени. Paimon предлагает следующие основные возможности:
- унифицированная пакетная и потоковая передача, включая пакетную запись и пакетное чтение, а также потоковую запись изменений и потоковое чтение журналов изменений таблицы;
- озеро данных с низкой стоимостью, высокой надежностью и масштабируемыми метаданными;
- различные механизмы слияния, включая дедупликацию, частичное обновление и агрегацию данных;
- логгирование изменений, с поддержкой поиска и полного сжатия данных;
- таблицы только для добавления (AO, Append-Only) – Paimon автоматически сжимает небольшие файлы и обеспечивает упорядоченное чтение потоков. Это позволяет использовать Paimon вместо очередей сообщений, которые рассчитаны только на кратковременное хранение небольших сообщений.
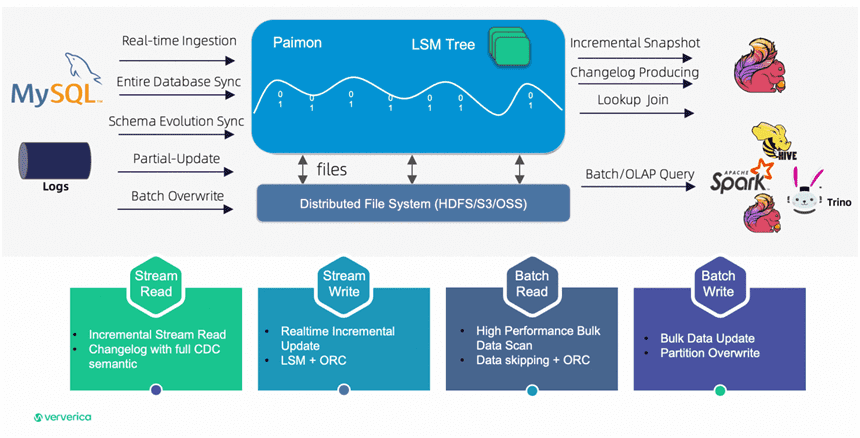
Paimon изначально поддерживает запись и запросы Flink SQL, а также позволяет использовать другие популярные движки: Apache Spark, Hive, Trino и пр. Apache Paimon использует те же подключаемые файловые системы, что и Flink. Paimon предоставляет автономные и унифицированные подключаемые файлы файловой системы, позволяющие пользователю запрашивать таблицы со стороны Spark/Hive.
Paimon поддерживает универсальный способ чтения и записи данных, а также выполнения аналитических запросов, включая потребление данных из исторических снимков (в пакетном режиме), от последнего смещения (в потоковом режиме) и чтение дополнительных снимков гибридным способом. Для записи Apache Paimon поддерживает потоковую синхронизацию из журнала изменений баз данных (CDC) и пакетную вставку/перезапись из автономных данных.
Хотя формат внутренней таблицы Paimon во многом похож на Apache Iceberg, включая моментальные снимки и файлы манифеста, ее базовая структура данных соответствует деревьям слияния с журнальной структурой (LSM), специально разработанным для потоковой передачи. Paimon поддерживает колоночный способ хранения данных в файловой системе или хранилище объектов и использует древовидную LSM-структуру для быстрых обновлений большого объема данных и высокопроизводительных запросов. Paimon обеспечивает абстракцию таблиц, похожую на классическую концепцию баз данных:
- в пакетном режиме выполнения он действует как таблица Hive и поддерживает различные SQL-операции;
- в потоковом режиме выполнения он действует как очередь сообщений, обращаясь к журналу изменений потока из очереди сообщений, где исторические данные никогда не устаревают.
Paimon использует протокол двухфазной фиксации для атомарной фиксации пакета записей в таблице. Каждая фиксация создает не более двух снимков во время фиксации. Для нескольких акторов, изменяющих таблицу одновременно, если они обращаются к разным сегментам, их фиксации могут происходить параллельно. Если пользователи изменяют один и тот же сегмент, гарантируется только изоляция моментальных снимков. То есть окончательное состояние таблицы может представлять собой смесь двух фиксаций, но никакие изменения не теряются.
Таким образом, гибридная архитектура данных Streamhouse с Apache Paimon позволяет реализовать следующие сценарии:
- захват измененных данных с Flink CDC и Paimon, а также Spark для чтения операционных данных из ODS и выполнения пакетной обработки;
- использование Flink SQL для потоковой передачи или пакетного ETL из ODS в DWD, чтобы сократить сквозную задержку передачи данных и/или обеспечить унифицированную сквозную потоковую ETL-обработку.
Узнайте больше про другие дата-архитектуры и возможности Apache Flink для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Потоковая обработка данных с помощью Apache Flink
- Архитектура Данных
- Практическая архитектура данных
- Архитектура данных с Apache Spark
Источники

