 1390
1390 
Какова роль каталогов метаданных в корпоративных Data Lake, почему Hive Metastore не отвечает всем потребностям современной дата-инженерии в гибком управлении данными и в чем преимущества формата открытых таблиц Iceberg над таблицами Hive и Delta Lake.
Каталоги метаданных в Data Lake
Для организации данных в корпоративных озерах используются каталоги метаданных, которые определяют таблицы в хранилище Data Lake. С этими каталогами все корпоративные приложения используют общее определение и представление данных в озере, что упрощает их обработку и получение согласованных результатов. Каталоги используются для определения того, какие наборы данных существуют в Data Lake, где именно они находятся и каким образом таблицы структурированы по столбцам, именами, типам данных и пр. Почему отсутствие каталогов является проблемой в корпоративных платформах хранения и обработки Big Data, и как этого избежать, читайте в нашей новой статье.
Одним из самых популярных каталогов метаданных является Hive Metastore (HMS). Оно содержит схему, структуру таблиц и расположение наборов данных в хранилище Data Lake. При этом каталоги обеспечивают структуру, аналогичную реляционным базам данных поверх файлового хранилища, и совместно используются несколькими приложениями. Это обеспечивает согласованные результаты между различными приложениями и упрощает управление данными. По умолчанию Hive записывает информацию хранилища метаданных в базу данных MySQL в файловой системе главного узла. Почему это не надежно и как подключить внешнее хранилище метаданных, развернув в AWS EKS, мы рассказываем здесь.
Однако, предоставляя общее определение структуры набора данных в хранилище Data Lake, каталоги метаданных не координируют согласованные изменения данных или эволюцию схемы между транзакционными приложениями.
Например, большой набор данных из сотен тысяч файлов в Apache Hive содержит структуру набора данных, включая имена столбцов и типы данных, а также разделы, организованные в каталоги. Но они не определяют, какие файлы присутствуют и являются частью набора данных. В результате приложения должны считывать метаданные файлов из хранилища Data Lake, чтобы найти нужные файлы. Пока набор данных статичен и не изменяется, различные приложения могут работать с согласованным представлением набора данных. Но, если одно приложение записывает и изменяет набор данных, эти изменения необходимо координировать с другим приложением, которое считывает из того же набора данных. Например, когда ETL-процесс обновляет набор данных, добавляя и удаляя несколько файлов из хранилища, другое приложение, считывающее набор данных, может обрабатывать частичное или несогласованное представление набора данных и генерировать неправильные результаты. Это происходит, когда некоторые файлы были добавлены или удалены из хранилища, но не все необходимые изменения были внесены.
Без автоматической координации изменений данных между приложениями в озере данных организациям необходимо создавать сложные конвейеры или промежуточные области. Альтернативой является формат открытых таблиц, такой как Apache Iceberg. В отличие от Hive Metastore, где изменения вносятся через Hive, в Iceberg все приложения являются равноправными участниками, а несколько инструментов могут обновлять таблицы напрямую и одновременно. Кроме того, Iceberg описывает полную историю таблиц, включая изменения схемы и данных. А хранилище метаданных Hive описывает только текущую схему набора данных без исторической информации или изменений данных при путешествии во времени.
В отличие от реляционных СУБД и классических DWH, реализующих атомарные транзакции и путешествия во времени через закрытую, вертикально интегрированную и проприетарную систему управления доступом, Iceberg позволяет всем приложениям напрямую работать с таблицами в хранилище Data Lake. Эта гибкость снижает затраты за счет использования преимуществ архитектуры озера данных и значительно повышает скорость вычислений, поскольку все приложения могут работать с наборами данных сразу на месте без их переноса между несколькими отдельными и закрытыми системами. Чем еще Apache Iceberg отличается от Hive, мы рассмотрим далее.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
12 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Apache Hive vs Iceberg
Apache Hive является популярным средством организации Data Lake, будучи инструментом стека SQL-on-Hadoop. Hive позволяет обращаться к данным в распределенной файловой системе Hadoop (HDFS) через стандартные SQL-запросы. Однако, эта NoSQL-СУБД сама по себе не предназначена для хранения объектов и не очень хорошо подходит для транзакционных нагрузок с изменениями в схемах таблиц. В частности, таблицы Hive разделены по фиксированным столбцам, поэтому для перераспределения набора данных приходится создавать новую таблицу и перезагружать весь датасет. Это долго и требует много усилий. Поэтому многие компании, включая Airbnb, о чем мы рассказывали здесь, переводят корпоративную инфраструктуру хранилища данных до современного стека на основе Apache Iceberg и Spark, чтобы повысить удобство сопровождения и использования своего Data Lake.
Напомним, Apache Iceberg — это открытый формат таблиц, предназначенный для устранения традиционных форматов хранения данных на основе файловой системы, в частности, Hive. Iceberg предназначен для высокопроизводительного чтения огромных аналитических таблиц, включая функции сериализуемой изоляции, перемещения во времени на основе моментальных снимков и предсказуемой эволюции схемы. По сравнению с Apache Hive, Iceberg имеет следующие преимущества:
- возможность изменения существующих данных, включая обновление и удаление – в Hive эти изменения не могут быть обработаны на уровне файлов HDFS;
- эффективная работа с большими разделами – Hive предполагает их полную перезапись в новое место для каждого обновления или удаления, что долго и дорого. Обновления существующих разделов в Apache Hive требуют воссоздания существующего сопоставления таблиц с новым расположением, поскольку разделы определяются при создании таблицы и не могут быть изменены по мере роста таблиц.
- безопасность параллельной записи в один и тот же набор данных. В Hive это не безопасная операция, т.к. есть вероятность потери данных, из-за состояния гонки при распараллеливании записи.
- быстрота извлечения всего списка каталогов с уровня раздела даже для больших таблиц. В Apache Hive файлы в разделе сканируются во время выполнения, а в Iceberg вместо этого идет работа с одним файлом манифеста, что повышает производительность.
- ускорение запроса данных — в Apache Hive это может занимать много времени, поскольку наборы данных постоянно растут из-за структуры каталогов для хранения разделов. В случае нескольких разделов добавляется дополнительный уровень накладных расходов к запросам наборов данных, а пользователям приходится следить за физическим расположением таблиц при написании SQL-запросов. В Apache Iceberg нет такой необходимости.
Эти преимущества Apache Iceberg над Hive достигаются благодаря разнице в архитектуре. Ключевое отличие в том, как Apache Iceberg хранит сами записи и их метаданные в объектном хранилище, тогда как Hive – в файловом. Хотя Iceberg тоже использует файловую структуру (файлы метаданных и манифеста), она управляется на уровне метаданных: каждая фиксация на любой временной шкале сохраняется как событие на уровне данных при их добавлении. Уровень метаданных управляет списком моментальных снимков. Кроме того, он поддерживает интеграцию с несколькими механизмами запросов, а параллельные фиксации одних и тех же наборов данных обеспечивают атомарность транзакций с оптимистичным контролем параллелизма.
Любое обновление или удаление на уровне данных создает новый снимок на уровне метаданных из предыдущего последнего snapshot’а и параллельно связывает его, обеспечивая более быструю обработку запроса, поскольку запрос, предоставленный пользователями, извлекает данные на уровне файла, а не на уровне раздела. Изменения схемы и раздела в существующей таблице отслеживаются как отдельные компоненты в моментальных снимках на уровне метаданных. При изменении раздела Apache Iceberg сохраняет предыдущий и последний разделы как отдельные планы. При SQL-запросе к старым данным, Apache Iceberg выполняет план разделения и извлекает данные с разными разделами из нескольких моментальных снимков.
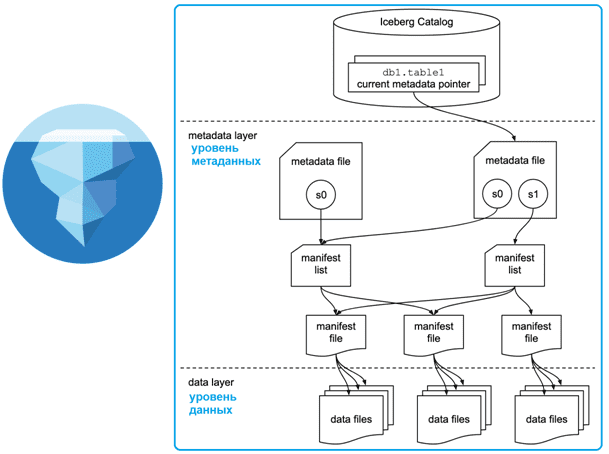
Iceberg использует модель запросов на основе моментальных снимков, в которой файлы данных сопоставляются с использованием файлов манифеста и метаданных. Даже при масштабном росте данных, SQL-запросы к этим таблицам обеспечивают высокую производительность, поскольку данные доступны на уровне файлов. А эти сопоставления хранятся в каталоге Iceberg. Таким образом, Iceberg поддерживает эволюцию схемы данных, упрощая добавление, переименование и изменение порядка имен столбцов. Изменения схемы данных никогда не требуют перезаписи всей таблицы, поскольку имена столбцов однозначно идентифицируются в слое метаданных с помощью идентификаторов, а не имени самого столбца.
Кроме того, разделы в Apache Iceberg динамические. Например, если в таблице присутствует столбец времени события (отметка времени, timestamp), таблица может быть разделена по дате из этого столбца. Apache Iceberg управляет взаимосвязью между timestamp-столбцом времени события и датой. Можно выполнить дополнительные уровни разделения, которые будут привязаны к моментальному снимку через файлы метаданных.
Для работы с данными во времени и отката изменений назад Apache Iceberg поддерживает 2 типа параметров чтения моментальных снимков: snapshot-id, который выбирает конкретный снимок таблицы и as-of-timestamp, выбирающий текущий моментальный снимок с отметкой времени в миллисекундах.
В заключение сравним Apache Iceberg c Hive и Delta Lake — хранилища с открытым исходным кодом, который поддерживает ACID-транзакции и масштабируемую обработку метаданных, объединяя потоковые и пакетные операции с большими данными. Delta Lake работает на базе существующего озера данных (на HDFS, Amazon S3 или Azure Data Lake Storage) и полностью совместимо со всеми API Apache Spark. Подробнее о том, что такое Delta Lake, мы писали здесь.
Сравним Iceberg c Hive и Delta Lake по следующим критериям:
- драйвер развития;
- поддерживаемый формат файлов;
- транзакционность;
- зависимость от вычислительных движков;
- открытость кода.
Результаты сравнения приведены в следующей таблице.
| Критерий | Apache Hive | Delta Lake | Apache Iceberg |
| Драйвер развития | Сообщество, Apache Software Foundation (ASF) | Корпорация Databricks | Netflix, Apple и сообщество ASF |
| Формат файлов | ORC | Parquet | Parquet, ORC, Avro |
| Транзакционность | Да | Да | Да |
| Движок | Spark, Tez | Spark | Любой |
| Открытость кода | Да | Не полностью | Да |
В отличие от Iceberg, который представляет собой независимый проект Apache Software Foundation, где участвуют различные ИТ-компании, Delta Lake спонсируется и контролируется исключительно Databricks. Кроме того, Delta Lake не является полностью открытым исходным кодом, операции записи доступны только через Apache Spark, а оптимизация производительности для ускорения чтения скрыта.
В отличие от Delta Lake, таблицы Hive полностью открыты. Но, как и в Delta Lake, операции обновления в Hive могут выполняться только с помощью одного механизма озера данных, большая часть разработки которого выполняется одним провайдером (Cloudera). Таблицы Hive зависят от формата файла ORC и менее гибки с точки зрения поддерживаемых форматов файлов.
Хотя таблицы Delta Lake и Hive существуют дольше, чем Iceberg, последний быстро набирает популярность благодаря своим архитектурным особенностям, что мы рассмотрели ранее.
Читайте в нашей следующей статье про стратегии перехода от Apache Hive к Iceberg. А освоить тонкости администрирования и эксплуатации Apache Hive и других компонентов экосистемы Hadoop для хранения и аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Данных
- Практическая архитектура данных
- Практическое применение Big Data аналитики для решения бизнес-задач
Источники

