 550
550 
Год назад мы уже писали, как в Apache Flink появились табличные хранилища и зачем они нужны. Сегодня заглянем под капот Flink Table Store, познакомившись со структурой файлов и каталогов.
Архитектура и принципы работы Flink Table Store
Поскольку Apache Flink объединяет пакетную обработку данных с потоковой, для работы этого универсального stateful-механизма и используются табличные хранилища (Table Store). Table Store — унифицированное хранилище для создания динамических таблиц для потоковой и пакетной обработки, поддерживающее высокоскоростной прием данных и своевременный запрос данных. Table Store может хранить большие наборы данных и возможность чтения/записи как в пакетном, так и в потоковом режиме средствами SQL-запросов с минимальной задержкой. Примеры того, как это сделать, мы рассматривали здесь.
Также хранилище таблиц поддерживает добавочные моментальные снимки для потокового потребления по умолчанию, избавляя разработчика от необходимости самостоятельно комбинировать разные конвейеры. Для записи поддерживается потоковая синхронизация из журнала изменений баз данных (CDC) или пакетная вставка/перезапись из автономных данных. Внутри Table Store используется гибридная архитектура хранения с форматом озера для хранения исторических данных и системой очередей для хранения добавочных данных. Озеро данных хранит колоночные файлы в файловой системе или объектном хранилище и использует древовидную LSM-структуру для поддержки большого объема обновлений данных и высокопроизводительных запросов. В качестве системы очередей используется Apache Kafka для сбора данных в режиме реального времени.
Flink Table Store обеспечивает абстракцию таблиц подобно классической базе данных. В пакетном режиме выполнения Flink хранилище работает как таблица Hive и поддерживает различные операции пакетных SQL-запросов. В потоковом режиме хранилище таблиц действует как очередь сообщений, обрабатывая запросы журнала изменений потока из непрерывной очереди сообщений.
Моментальный снимок фиксирует состояние таблицы в некоторый момент времени. Пользователи могут получить доступ к последним данным таблицы через последний снимок. Изменяя периоды, можно получить доступ к предыдущему состоянию таблицы через более ранний snapshot.
Подобно Apache Hive, Table Store использует ту же концепцию партиционирования для разделения данных основе значений некоторых столбцов. Каждая таблица может иметь один или несколько ключей секций для идентификации конкретного раздела. Это позволяет эффективно работать с фрагментами записей в таблице. Ключи раздела должны быть подмножеством первичных ключей, если они определены.
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
12 января, 2026
Продолжительность
16 ак.часов
Стоимость обучения
48 000
Непартиционированные таблицы или разделы в партиционированных таблицах подразделяются на сегменты (backet), чтобы обеспечить дополнительную структуру данных для более эффективных запросов. Диапазон сегмента определяется хэш-значением одного или нескольких столбцов в записях. Пользователи могут указать столбцы сегментации, указав ключ сегментирования (bucket-key). Если этот параметр не указан, в качестве ключа сегмента будет использоваться первичный ключ или полная запись.
Сегмент — представляет собой наименьшую единицу хранения для операций чтения и записи, поэтому их количество ограничивает максимальный параллелизм обработки. Не стоит делать слишком много сегментов, поскольку это приводит к большому количеству маленьких файлов и низкой производительности чтения. Обычно рекомендуемый размер данных в каждом сегменте составляет около 1 ГБ.
Table Store адаптирует дерево LSM (дерево слияния с журнальной структурой) в качестве структуры данных для хранения файлов. Все файлы таблицы хранятся в одном базовом каталоге. Файлы Table Store организованы в многоуровневом стиле. Начиная с файла моментального снимка, можно рекурсивно обращаться ко всем записям из таблицы при чтении.
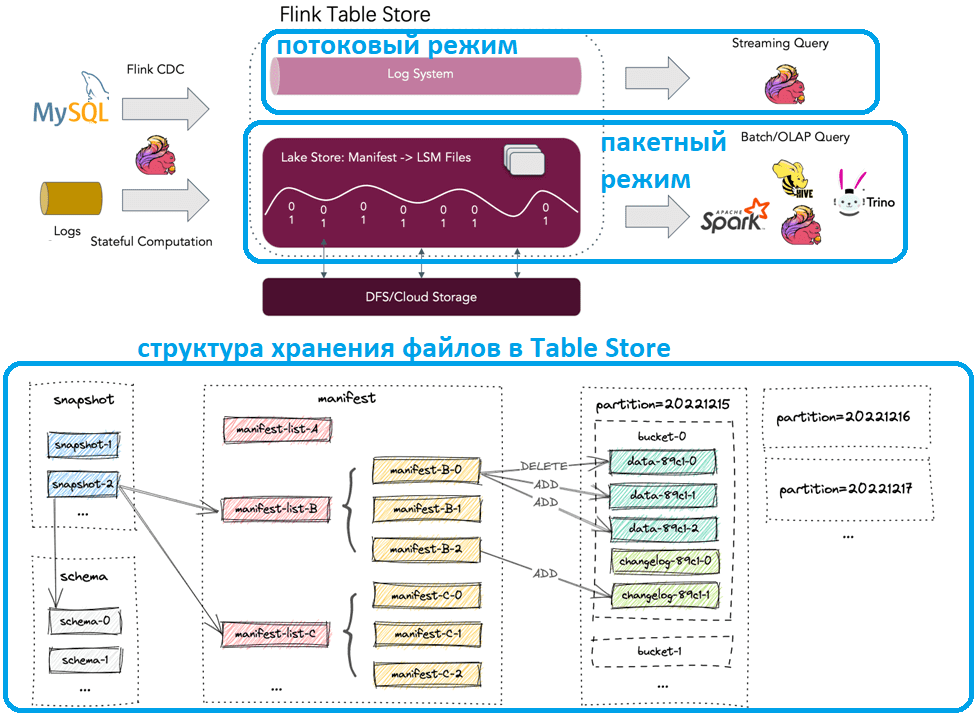
Помимо Apache Flink, Table Store также поддерживает чтение данных другими вычислительными SQL-движками, такими как Apache Hive, Apache Spark и Trino. Табличное хранилище использует те же подключаемые файловые системы, что и Apache Flink. Можно использовать стандартный механизм подключаемых модулей для настройки структуры плагинов при использовании Flink в качестве вычислительного механизма. Однако, для других движков, таких как Spark или Hive, предоставленные JAR-файлы opt могут конфликтовать. Чтобы избавить пользователей от таких конфликтов, Flink Table Store предоставляет автономные и унифицированные движком подключаемые JAR-файлы файловой системы, позволяя запрашивать таблицы с помощью Apache Spark или Hive.
Разобравшись с архитектурой и базовыми концепциями Flink Table Store, далее познакомимся со структурой файлов и каталогов, которые обеспечивают работу этих идей.
Структура файлов и каталогов
Все файлы моментальных снимков хранятся в каталоге snapshot и представляют собой JSON-файлы, содержащий информацию об каждом снимке, включая используемый файл схемы и список манифестов со всеми его изменениями. Все списки манифестов и файлы манифестов хранятся в каталоге manifest. Список манифеста содержит перечень имен файлов манифеста, каждый из которых описывает изменения в файлах данных LSM и файлах журнала изменений. Например, какой файл данных LSM создается, и какой файл удаляется в соответствующем снимке. Файлы данных сгруппированы по разделам и сегментам. Каждый каталог сегмента содержит LSM-дерево и его файлы журнала изменений.
Поскольку, как уже было отмечено ранее, общее количество сегментов сильно влияет на производительность, Table Store позволяет настраивать количество сегментов с помощью команды ALTER TABLE и реорганизовывать структуру данных с помощью INSERT OVERWRITE без повторного создания таблицы или раздела. При выполнении заданий по перезаписи фреймворк автоматически сканирует данные со старым номером сегмента и хэширует запись в соответствии с текущим номером. Однако, команда ALTER TABLE только изменяет метаданные таблицы, не выполняя реорганизацию или переформатирование существующих данных. Реорганизация существующих данных делается только с помощью INSERT OVERWRITE. Номер сегмента не влияет на выполнение заданий чтения и записи. После изменения номера сегмента любые вновь запланированные задания вставки с помощью SQL-запроса INSERT INTO, которые записывают в существующую таблицу или раздел без учета реорганизации, будут выдавать исключение TableException. Масштабирование сегмента помогает справляться с внезапными скачками пропускной способности ETL-конвейеров, обеспечивающих синхронизации транзакций.
Table Store используют протокол двухэтапной фиксации для атомарной фиксации пакета записей в таблице. Каждая фиксация создает не более двух моментальных снимков во время фиксации. Для любых двух модулей записи, изменяющих таблицу одновременно, если они изменяют разные сегменты, их фиксации сериализуемы. Если они изменяют один и тот же сегмент, гарантируется только изоляция моментальных снимков. Это означает, что конечное состояние таблицы может быть сочетанием двух фиксаций, при том никакие изменения не будут потеряны.
Чтобы достичь компромисса между производительностью запроса и записи данных, Table Store адаптирует стратегию уплотнения, аналогичную универсальному уплотнению в нереляционной key-value базе данных RocksDB, которая часто используется в stateful-приложениях Flink в качестве хранилища состояний. По умолчанию, когда модули записи хранилища таблиц добавляют записи в дерево LSM, они также выполняют сжатие по мере необходимости. Можно запустить сжатие вручную в специальном compaction-задании.
Читайте в нашей новой статье, как табличное хранилище Flink стало новой платформой данных под названием Apache Paimon.
Узнайте больше про применение Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

