 1580
1580 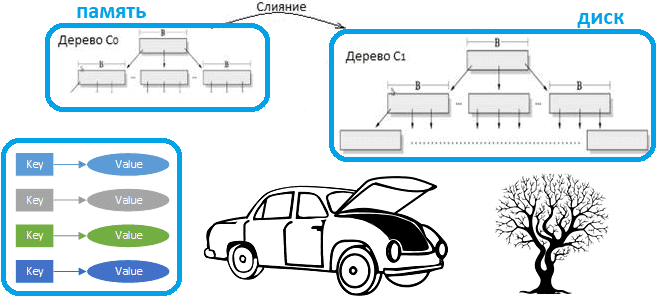
Что такое LSM-дерево и как эта структура данных, лежащая в основе многих NoSQL-баз с распределенным типом ключ-значение, позволяет им обеспечивать высокую скорость записи и чтения. Смотрим на примере Apache HBase.
Зачем нужны LSM-деревья
Типичная СУБД состоит из нескольких компонентов, каждый из которых отвечает за обработку различных аспектов хранения, поиска и управления данными. Одним из них является механизм хранения, который отвечает за обеспечение надежного интерфейса для эффективного чтения и записи данных из/в базовое устройство хранения. Это компонент, который реализует два из четырех ACID-требований к базам данных: атомарность и долговечность. Кроме того, производительность механизма хранения становится одним из важнейших критериев при выборе базы данных. Для реализации механизмов хранения используются деревья B+ и LSM (Log Structured Merge).
Термин Log Structured означает, что данные структурированы один за другим, как журнал только для добавления, а Merge относится к алгоритму, с помощью которого данные управляются в древовидной структуре. Хорошая производительность достигается за счёт того, что деревья оптимизированы под своё хранилище, а слияние осуществляется эффективно и группами по нескольку записей, используя алгоритм, напоминающий сортировку слиянием.
Почти все NoSQL-базы используют LSM-дерево в качестве базового механизма хранения, поскольку он позволяет им достичь высокой пропускной способности записи и быстрого поиска по первичному ключу. Зная, как работают LSM-деревья, можно быстрее отладить проблемы, которые возникают при эксплуатации и настройке баз данных. Например, чтобы настроить Cassandra для конкретной рабочей нагрузки, необходимо выбирать между различными стратегиями уплотнения, что является критическим этапом в жизненном цикле управления данными LSM-дерева. Напомним, рабочая нагрузка базы данных – это количества операций, которые СУБД может выполнить за заданный промежуток времени в соответствии с заданным набором показателей или шаблонов запросов. Чаще всего выделяют два вида нагрузки: транзакционный (OLTP) и аналитический (OLAP).
LSM-деревья становятся все популярнее по мере того, как физические устройства хранения данных развиваются от вращающихся дисков до твердотельных накопителей с флэш-памятью. Традиционные механизмы хранения на основе деревьев B+ предназначены для вращающихся дисков, медленны при записи и предлагают только адресацию на основе блоков. Но современные приложения требуют интенсивной записи и генерируют большие объемы данных. Новые устройства хранения предлагают байтовую адресацию и работают быстрее, чем твердотельные накопители.
LSM-дерево реализует быстрый доступ к данным по индексу в условиях частых запросов на вставку, храня пару ключ-значение, но обновляя только файл журнала и буферизации записи. Эта структура данных используется в качестве серверной части хранилища для многих масштабируемых NoSQL-СУБД с распределенным типом ключ-значение, таких как Lucene, Apache HBase, Google BigTable, LevelDB, DynamoDB, Cassandra, ScyllaDB, InfluxDB, RocksDB, terakdb, Sled и пр. Эти базы данных поддерживают гораздо большую скорость записи, чем традиционные реляционные решения. Как LSM-дерево реализует это, рассмотрим далее.
Как работает дерево Log Structured Merge
LSM-дерево поддерживает две или более различные структуры, каждая из которых оптимизирована под устройство, в котором она будет храниться. Синхронизация между этими структурами происходит блоками. Простая версия LSM-дерева — двухуровневое дерево — состоит из двух древоподобных структур C0 и C1. C0 меньше по размеру и хранится целиком в оперативной памяти, а C1 находится в энергонезависимой памяти. Новые записи вставляются в C0. Если после вставки размер C0 превышает некоторое заданное пороговое значение, непрерывный сегмент удаляется из C0 и сливается с C1 на устройстве постоянного хранения. LSM подчеркивает, что случайный ввод-вывод на диск требует больших затрат на запись, в последовательная запись выполняется намного быстрее, поскольку головка записи диска находится рядом с местом последней записанной записи, а задержка вращения и поиска минимальна. Поскольку данные организованы в несколько уровней, эта структура данных имеет древовидный вид. В базовой конфигурации LSM-дерево состоит из двух структур данных, использующих как оперативную память, так и постоянный диск:
- Memtable – структура в памяти, которая буферизует входящие данные от клиентов перед их сбросом на диск. Это первая точка контакта для каждой операции чтения или записи, получаемой деревом LSM. Сброс происходит, когда Memtable достигает определенного порога размера, индивидуального для разных СУБД. Структура данных Memtable должна обеспечивать отсортированную итерацию по своему содержимому. Объем данных, которые может хранить Memtable, ограничен оперативной памятью, и при превышении установленного порогового размера все содержимое Memtable должно быть записано в файл SSTable, где элементы сортируются по ключу, и должна быть создана новая Memtable для приема входящих записей.
- SSTable — таблица сортированных строк, концепция Google BigTable. Это файл на диске, куда записи значения ключа из Memtable сбрасываются в отсортированном порядке. Файл SSTable создается, когда Memtable достигает своей емкости или когда происходит уплотнение. Данные в SSTable хранятся отсортированными для облегчения эффективного чтения. Со временем на диске может быть несколько SSTable из-за частой записи в Memtable. Они постоянно реорганизуются и сжимаются в разные уровни, которые обычно имеют пространство имен от уровня 0 до уровня N. Чем выше уровень, тем больше сжатие и зависимости разных SSTables с перекрывающимися ключами. Несмотря на очень простую структуру, архитектура SSTable способна хранить и обслуживать петабайты данных, о чем свидетельствует их использование в проектах Google.
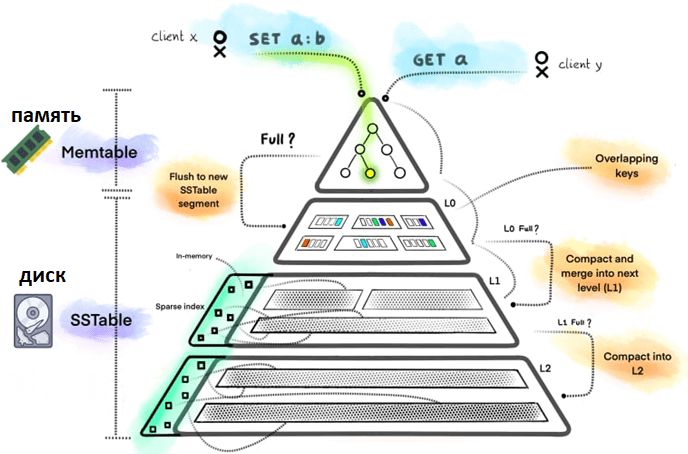
В практических реализациях файлы SSTable также дополняются сводкой SSTable и индексным файлом, который действует как первая точка контакта при чтении данных из SSTable. В этом случае SSTable разделен на файлы данных, файл индекса и файл сводки (используется в Casssandra и ScyllaDB). Файлы данных SSTable обычно кодируются в определенном формате с любыми необходимыми метаданными, а записи значений ключа хранятся в фрагментах, называемых блоками. Эти блоки также могут быть сжаты для экономии места на диске. Разные уровни могут использовать разные алгоритмы сжатия. Они также используют контрольные суммы в каждом блоке для обеспечения целостности данных. Индексный файл перечисляет ключи в файле данных по порядку, указывая для каждого ключа его положение в файле данных.
Сводный файл SSTable хранится в памяти и содержит образцы ключей для быстрого поиска в индексном файле. По сути, это индекс для индексного файла SSTable. Для поиска определенного ключа сначала обращаются к сводному файлу, чтобы найти короткий диапазон позиций, в которых можно найти ключ, и загружает это конкретное смещение в память.
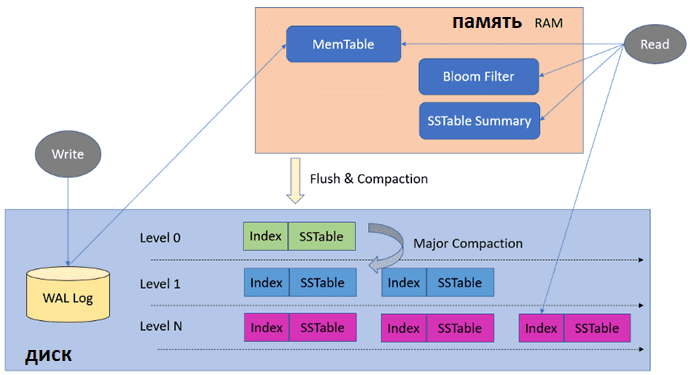
Архитектура LSM-дерева позволяет удовлетворить запрос на чтение либо из оперативной памяти, либо за одно обращение к устройствам постоянного хранения. Запись тоже всегда быстра независимо от размеров хранилища. SSTable на устройствах постоянного хранения неизменяема. Поэтому изменения хранятся в MemTable, а удаления должны добавлять в MemTable специальное значение. Поскольку новые считывания происходят последовательно по индексу, обновлённое значение или запись об удалении значения встретятся раньше, чем старые значения. Периодически запускаемое слияние старых SSTable на устройстве постоянного хранения будет производить эти изменения, удалять и обновлять значения, избавляясь от ненужных данных.
Сводный файл SSTable хранится в памяти и содержит образцы ключей для быстрого поиска в индексном файле. Индексный файл SSTable перечисляет ключи в файле данных по порядку, указывая каждому ключу свою позицию в файле данных. Файл данных SSTable содержит записи значений ключа, хранящиеся в фрагментах, называемых блоками. Эти файлы данных закодированы. Эти блоки также сжимаются для экономии места на диске. Алгоритм сжатия может быть разным для уровней. Для проверки целостности данных используется контрольная сумма.
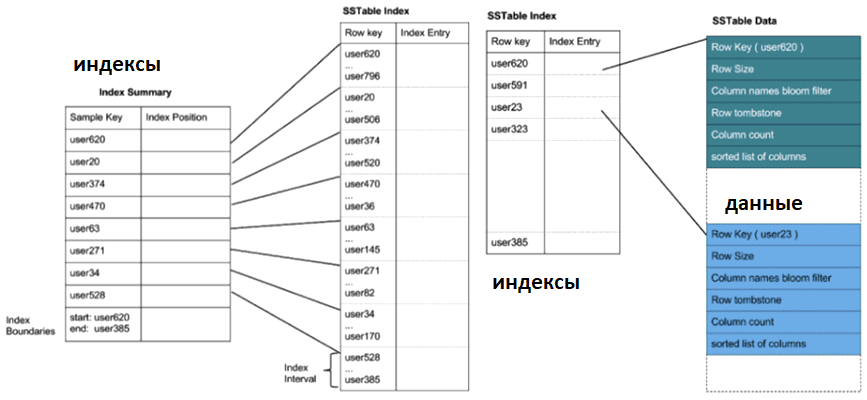
Уплотнение или сжатие — это фоновый процесс, который непрерывно объединяет старые сегменты в новые сегменты. На производительность чтения-записи дерева LSM сильно влияет то, как происходит уплотнение. В различных NoSQL-СУБД оптимизация уплотнения направлена на разные операции. Например, в Cassandra эта оптимизация через уплотнение уровней ориентирована на запись, а в RocksDB, которая используется в Apache Kafka и Flink, — оптимизация чтения. В InfluxDB есть окно времени, а в ScyllaDB действует гибридное уплотнение. С точки зрения реализации для выполнения уплотнения используется выделенный фоновый поток. В качестве оптимизации может быть несколько выделенных потоков уплотнения, работающих в определенный момент времени, как в RocksDB, для сжатия файлов SSTables. Поток уплотнения также отвечает за обновление разреженного индекса после любого слияния, чтобы он указывал на новые смещения ключей в новом файле SSTable.
LSM предполагает, что сперва поиск выполняется в MemTables. Поскольку MemTables расположены в памяти, поиск выполняется быстро, и найденный результат возвращается клиенту. Если ключ недоступен в MemTables, ищется ключ в SSTables с помощью фильтров Блума, которые сужают область поиска. Простая оптимизация заключается в сохранении разреженного индекса в памяти. О том, что такое фильтр Блума, мы писали здесь.
Удаление в LSM фактически следует тому же пути, что и запись данных. Когда поступает запрос на удаление, для этого ключа записывается уникальный маркер. Когда все эти маркеры будут сжаты, значение перестанет существовать на диске.
В Apache HBase концепция LSM реализована с использованием HLog, Memstores и storefiles. Каждый региональный сервер имеет несколько регионов (HRegion). Каждый HRRegion содержит раздел данных для таблицы, у которого столько же хранилищ памяти, сколько семейств столбцов в этой таблице. HRegion отслеживает общий размер хранилища памяти, созданного всеми этими хранилищами. После применения любых операций мутации проверяется, не превышает ли общий размер хранилища памяти настроенный максимальный размер сброса. Если это так, вызывается метод requestFlush(), где делегируется вызов MemstoreFlusher регионального сервера.
Недостатки LSM
Основным недостатком LSM-дерева является стоимость сжатия, которая влияет на производительность чтения и записи. Сжатие является наиболее ресурсоемкой фазой LSM-дерева из-за сжатия/распаковки данных, копирования и сравнения ключей, задействованных в процессе. Выбранная стратегия уплотнения должна минимизировать увеличение чтения, увеличение записи и увеличение пространства. Еще одним недостатком LSM Tree является дополнительное пространство, необходимое для выполнения сжатия. Это заметно в стратегии многоуровневого уплотнения по размеру, поэтому используются другие стратегии уплотнения, такие как уровневое уплотнение. LSM-дерево также замедляет чтение: из-за природы только добавления операции чтения должны выполнять поиск в SSTable на самом низком уровне, с участием файлового ввода-вывода, что всегда очень медленно. Впрочем, несмотря на эти недостатки, LSM-деревья активно используются во многих СУБД и являются популярным подключаемым механизмом хранения во многих сценариях.
Освойте администрирование и эксплуатацию Apache HBase и других компонентов экосистемы Hadoop для хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

