 1138
1138 
Содержание
Чтобы добавить в наши курсы для дата-инженеров еще больше реальных примеров и лучших DataOps-практик, сегодня мы расскажем, как специалисты крупной норвежской компании DNB обеспечивают надежный доступ к чистым и точным массивам Big Data, применяя передовые методы проектирования данных и реализации конвейеров их обработки. В этой статье мы собрали для вас 10 лучших практик современной инженерии больших данных, которые позволят эффективно управлять data pipeline’ами и повысить качество данных.
Бизнес-контекст: архитектура конвейера обработки данных в DNB
DNB ASA – это крупнейшая финансовая группа в Норвегии, 34% которой принадлежит министерству торговли и промышленности этой страны. Корпорация включает целую группу предприятий: инвестиционный банк, страховую компанию, агентство недвижимости и др. [1]. Для DNB управление на основе данных (data-driven management) является обязательным залогом успешной деятельности. Поэтому корпорация стремится внедрять лучшие DataOps-практики, чтобы обеспечить надежный доступ к чистым, пригодным для использования и точным данным. Каждый день огромные массивы Big Data используются для создания отчетов и наглядных панелей (дэшбордов), аналитики больших данных, отправки информации в другие прикладные системы и принятия оптимальных управленческих решений.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
15 июня, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
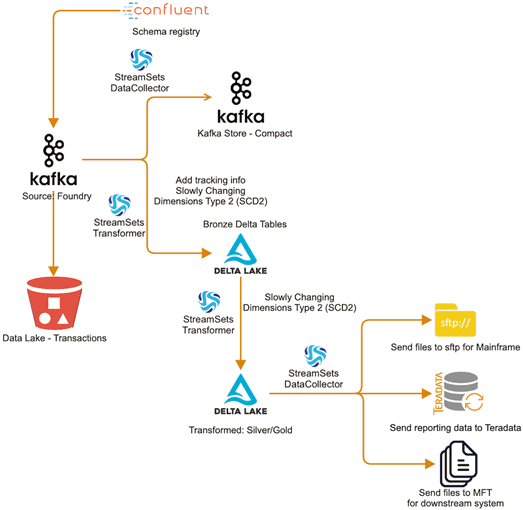
На высоком уровне архитектуру конвейеров сбора и обработки данных в DNB можно описать следующим образом [2]:
- потоки данных аккумулируются в топиках Apache Kafka;
- в качестве хранилища исторических данных выступает озеро данных (Data Lake) в виде Amazon S3 bucket;
- за маршрутизацию потоков данных из топиков Kafka отвечают компоненты платформы, аналогичной Apache NiFi — StreamSets Data Collector и StreamSets Transformer. ETL-маршрутизатор StreamSets Data Collector отправляет нужные данные в отдельный топик Kafka, а механизм выполнения (execution engine) StreamSets Transformer на базе Apache Spark запускает конвейеры обработки данных в кластерах Spark, включая различные дистрибутивы Hadoop;
- данные для оперативной аналитики хранятся в Delta Lake, облачном open-source хранилище поверх существующего озера данных с API Apache Spark и поддержкой ACID-транзакций;
- результаты аналитических запросов из Delta Lake с помощью StreamSets Transformer отправляются в соответствующие места назначения, такие как корпоративное DWH (Data Warehouse) на базе Teradata и прочие системы-получатели.
10 рекомендаций по эффективному построению Big Data Pipeline’ов
Чтобы реализовать вышеописанную архитектуру и обеспечить ее работу наиболее эффективным способом, дата-инженеры DNB используют лучшие DataOps-практики и соответствующий инструментарий стека Big Data. Также они предлагают собственные рекомендации по инженерии больших данных, которые можно адаптировать к реальной деятельности любой компании. Эти советы для самостоятельного обучения Data Engineer’ов перечислены далее [2]:
- Используйте шаблоны проектирования для данных, процессов и конвейеров, чтобы быстрее создавать новые объекты и отслеживать существующие. К примеру, можно создавать пользовательские процессоры обработки данных, которые будут решать ваши задачи лучше типовых обработчиков. Разумеется, в случае подобной кастомизации необходимо обеспечить возможность использования вновь созданных решений и для других команд. Также придерживайтесь унифицированных правил именования конвейеров, заданий и топологий, указывая в них параметры, которые помогают быстро идентифицировать объект, например, привязка к проекту, источнику, получателю, среде и пр. Еще имеет смысл фрагментировать конвейеры и использовать эти участки повторно, создавая из готовых блоков нужную бизнес-логику.
- Реализуйте идемпотентность, в частности, используйте upsert-операции вместо inserts. Это позволит повторно запускать конвейеры обработки данных, не беспокоясь о создании повторяющихся записей в месте назначения. Также это предупредит остановки data pipeline’а в случае ошибок из-за ограничений первичного ключа / уникальности.
- Используйте потоковую передачу вместо пакетной, чтобы обеспечить аналитическую обработку данных в реальном времени и ускорить цикл принятия управленческих решений.
- Поощряйте сотрудничество и совместное использование решений. Например, в DNB конвейеры, разработанные дата-инженерами, передаются группе разработчиков продукта. Это позволяет повторно использовать ресурсы конвейера для создания новых pipeline’ов, не тратя много времени на поиск наиболее эффективной конфигурации.
- Автоматизируя, помните про безопасность. В DNB все конвейеры разрабатываются с использованием хранилищ учетных данных через AWS Secrets Manager для сохранения учетных данных. Параметры файла среды выполнения активно используются для всех строк подключения к базе данных, URL-адресов реестра схемы, URI брокера Kafka и других аспектов, которые зависят от Runtime. Это позволяет создавать конвейеры один раз, а затем использовать их в различных средах без каких-либо изменений, а также обеспечивает безопасность при использовании некорректных параметров конфигурации в конкретной среде. Кстати, в DNB ни в одном конвейере не используются секретный идентификатор и секретные ключи – вместо этого применяются роли IAM для доступа к ресурсам AWS.
- Параметризуйте конвейеры, чтобы использовать их для нескольких источников и мест назначения данных. Например, конвейер для чтения топика Kafka с последующим добавлением атрибутов отслеживания и отправкой записей в таблицу Delta Lake. После создания конвейера его можно использовать снова в новых заданиях для считывания данных их других топиков Kafka и создания таблиц Delta Lake.
- Маркируйте и тэгируйте данные, чтобы быстрее отслеживать, группировать, искать и предоставлять доступ к ним. Например, для сборщиков данных и преобразователей в рамках платформы StreamSets можно задать название (Name), среду исполнения (Execution Environment – Sandbox, Staging, Prod), поставщика (Provider – AWS, Azure, GCP, On Prem), расположение (Location), регион (Region), среду развертывания конвейера (Pipeline Environment – Dev, Test, Prod). Для конвейеров и заданий можно обозначить источник (Source), цель (Target), происхождение (Origin), место назначения (Destination), продукт (Product), среду (Environment) и другие маркеры, которые позволяют быстрее оперировать с этими объектами.
- Контролируйте доступ по RBAC-модели (на основе ролей), чтобы гибко настраивать права на операции с данными и конвейерами их обработки для различных пользователей.
- Документируйте и комментируйте коммиты кода в каждой версии конвейеров, подробно расписывая, что именно было сделано, включая ссылки на заявки Jira для новых релизов или исправлений ошибок.
- Добавляйте пояснительные описания к максимальному количеству объектов – конвейерам, заданиям, компонентам, топологиям, источникам, местам назначения, процессорам и исполнителям. Это позволит вам и другим инженерам Big Data понять причину создания этих объектов даже спустя много времени. Кроме того, добавление описаний значительно упрощает обслуживание и отладку конвейеров обработки больших данных, предоставляя всю документацию по каждому объекту прямо на месте.
Таким образом, эффективная инженерия данных строится не только на технических средствах стека Big Data, но и на операционных правилах работы с этими инструментами и самими датасетами. Благодаря универсальному подходу, вышеописанные рекомендации являются типовыми и легко адаптируются к различным прикладным случаям, позволяя дата-инженерам сделать pipeline’ы последовательными, устойчивыми, масштабируемыми, надежными, повторно используемыми и готовыми к промышленной эксплуатации (production). А аналитики и Data Scientist’ы смогут сосредоточиться на поиске важных для бизнеса инсайтов, а не беспокоиться о различных аспектах Data Governance/Management.
Hadoop для инженеров данных
Код курса
HDDE
Ближайшая дата курса
в любое время
Продолжительность
40 ак.часов
Стоимость обучения
89 600
Больше практических приемов по инженерии больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Hadoop для инженеров данных
- Построение конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
Источники
- https://ru.wikipedia.org/wiki/DNB_ASA
- https://streamsets.com/blog/13-data-engineering-best-practices-at-dnb/

