 1483
1483 
Содержание
Мы уже рассказывали о некоторых профессиях Big Data, например, объясняли «для чайников», кто такие аналитик (Data Analyst) и исследователь (Data Scientist): что каждый из них должен знать и уметь, чем они занимаются и как отличаются друг от друга. Сегодня поговорим об инженере данных (Data Engineer) – его рабочих обязанностях, профессиональных компетенциях, зарплате и отличиях от вышеуказанных специалистов.
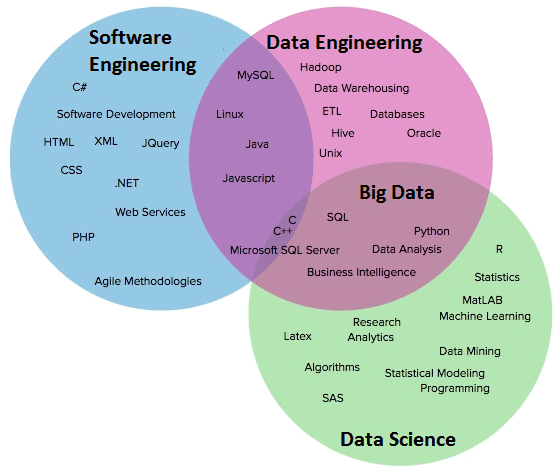
Что делает инженер данных
Чтобы Data Analyst и Data Scientist могли извлекать из информационных потоков и массивов Big Data знания, полезные для бизнеса, все эти большие данные должны соответствующим образом собираться и храниться. Именно этим занимается Data Engineer: настраивает инфраструктуру для Big Data, корпоративных хранилищ информации, ETL-систем, внутренних баз данных и сторонних источников (почта, CRM-, ERP- и других прикладных систем).
Таким образом, инженер данных выполняет следующие операции:
- организация автоматизированного сбора данных из различных источников в единое централизованное хранилище (Data Warehouse) или озеро данных (Data Lake);
- перемещение и хранение информационных массивов;
- настройка, интеграция и создание витрин данных для работы аналитиков и исследователей;
- создание конвейеров регулярной и непрерывной подготовки данных (CI/CD pipelines);
- контроль и повышение качества данных.

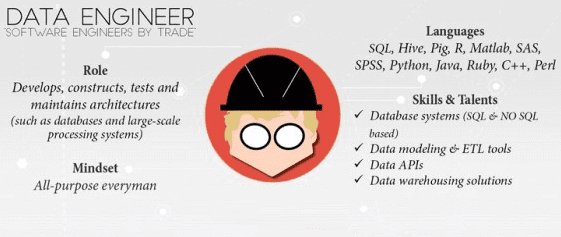
Профессиональные компетенции инженера данных: что должен знать Data Engineer
Тогда как Data Scientist и Data Analyst концентрируются на сути информационных массивов Big Data, инженер данных организует для них инфраструктуру. Для этого ему необходимы профессиональные следующие знания и навыки:
- алгоритмы и структуры данных;
- принципы хранения информации в SQL и NoSQL, а также умение работать с реляционными и нереляционными базами данных (MySQL, MSSQL, PostgreSQL, MongoDB, SQL Server, Oracle, HP Vertica, Amazon Redshift и т.д.)
- ETL-системы (Informatica ETL, Pentaho ETL, Talend и пр.);
- облачные платформы для Big Data решений (Amazon Web Services, Google Cloud Platform, Microsoft Azure и другие подобные решения от крупных PaaS/IaaS-провайдеров);
- стек Apache Hadoop (HDFS, HBase, Cassandra) и SQL-движки для анализа данных, хранящихся в распределенных файловых системах типа HDFS (Apache Hive, Impala и пр.);
- кластеры Big Data на базе Apache (Hadoop, Kafka, Spark);
- языки программирования (Python, Java, Scala) для работы с Big Data системами.
Несмотря на плотную работу с ETL- и OLAP-системами, Data Engineer’у, в отличие от аналитика и ученого по данным, не требуются экспертные знания Business Intelligence (BI), а также специфики предметной области. Гораздо полезнее инженеру по данным будет опыт разработки программного обеспечения и администрирования кластеров, хотя это, в основном, является областью ответственности администратора Big Data. Подробнее об этом читайте в нашей следующей статье.
Зарплата и востребованность инженера данных на рынке труда
В статье «Big Data с чего начать», говоря о профессиях в мире больших данных «для чайников», мы уже упоминали, что ИТ-специалисты этой области очень высоко ценятся на рынке труда как в России, так и за рубежом. При этом, в связи с тотальной цифровизацией и цифровой трансформацией различных отраслей экономики, наблюдается повышенный спрос на Data Professional’ов.
В условиях такого дефицита кадров, зарплата инженеров данных является одной из самых высоких в ИТ. Например, согласно ежегодному исследованию портала Stack OverFlow, в 2019 году американский Data Engineer зарабатывает около 66 тысяч долларов в год, что составляет более 300 тысяч рублей в месяц. Далеко не каждый Data Analyst или Data Scientist может похвастаться таким заработком. В России, по обзору вакансий с популярной рекрутинговой площадки HeadHunter, инженер данных стоит 150-250 тысяч в месяц.
Итак, Data Engineer настраивает инфраструктуру Big Data для аналитиков и исследователей данных. Как сделать это быстро, грамотно, безопасно и с возможностью масштабирования, рассматривается на наших практических курсах обучения и повышения квалификации ИТ-специалистов в лицензированном учебном центре для руководителей, аналитиков, архитекторов, инженеров и исследователей Big Data в Москве:
- HDDE: Hadoop для инженеров данных
- ARMG: Архитектура Модели Данных
- INTR: Основы Hadoop
- NIFI: Кластер Apache NiFi

