 969
969 
Содержание
Однажды мы уже рассказывали про StreamSets Data Collector, сравнивая его с Apache NiFi. Сегодня рассмотрим, как устроен этот исполнительный движок для запуска конвейеров обработки больших данных, каким образом он связан с Apache Spark и чем полезен инженеру Big Data при организации ETL-процессов на локальных и облачных озерах данных (Data Lake, Delta Lake).
Демократизация ETL для Delta Lake: автоматизация pipeline’ов и GUI
Получение информации из Data Lake для аналитики больших данных и машинного обучения (Machine Learning) – один из важнейших аспектов современной Big Data инфраструктуры. При этом на практике часто возникает проблема консолидации пакетных и потоковых источников данных. Большие данные часто бывают неструктурированы и несовместимы друг с другом из-за разных форматов и типов. Это затрудняет обновление данных в Data Lake. Кроме того, низкая скорость запросов и отсутствие доступа в режиме реального времени приводит к снижению качества данных и общей производительности озера, что еще больше задерживает развертывание в производственной среде (production). Чтобы обойти эти ограничения, дата-инженеры тратят время на специальные тестовые среды для проверки концепции, пытаясь перенести данные в production. В свою очередь, аналитики Big Data не могут быть в каждый момент уверены в высоком качестве и актуальности результатов, извлеченных из озера данных, что лимитирует их использование для аналитических приложений и моделей Machine Learning [1].
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Решить вышеотмеченные проблемы и повысить ценность облачной аналитики за счет автоматизации задач приема и преобразования данных можно с помощью конвейеров приема и обработки больших данных, организовав автоматизированный ETL-pipeline. При этом дополнительным преимуществом будет возможность его построения в наглядном виде через удобный графический интерфейс, например, в рамках веб-GUI Apache NiFi, о чем мы писали здесь. Альтернативным вариантом является комбинация ETL-платформы StreamSets с масштабируемым Delta Lake – облачным open-source хранилищем поверх существующего озера данных с API Apache Spark и поддержкой ACID-транзакций. Это интеграционное решение от апологетов коммерциализации Apache Spark для enterprise-сегмента, компании Databrics предоставляет следующие преимущества [1]:
- ускоренный переход в облако с меньшими накладными расходами на инженерию данных;
- упрощение процесса консолидации данных из нескольких разрозненных источников за счет удобного GUI;
- обеспечение повышение эффективности управления качеством данных и производительностью облачных озер с помощью технологии Delta Lake;
- возможность сбора измененных данных из нескольких источников в Delta Lake;
- снижение риска сбоев при миграции с локальных Hadoop-кластеров в облачные хранилища, такие как, например, Apache Ozone, Google Cloud Storage или Amazon S3;
- непрерывный мониторинг конвейеров данных для оптимизации ETL-процессов в сочетании со снижением затрат на поддержку.
Таким образом, интеграция Delta Lake от Databricks и StreamSets позволяет пользователям разрабатывать, тестировать и отслеживать ETL-конвейеры пакетной и потоковой передачи больших данных в графическом режиме, снижая порог входа в технологию. Пользовательский интерфейс StreamSets упрощает прием данных из нескольких источников в Delta Lake. А благодаря исполнительному движку StreamSets Transformer можно создавать конвейеры обработки данных, которые выполняются в Apache Spark в виде самостоятельных Спарк-приложения. Как это работает, мы рассмотрим далее.
StreamSets Transformer и Apache Spark
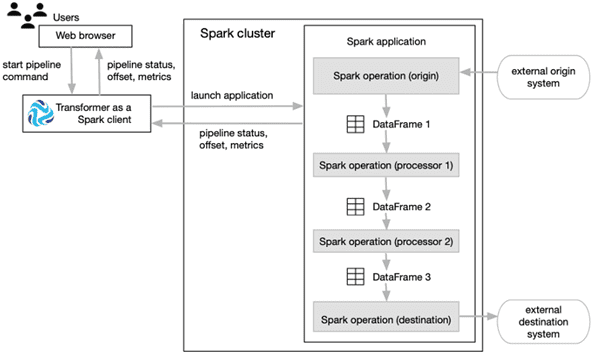
StreamSets Transformer – это механизм выполнения (execution engine), который запускает конвейеры обработки данных в кластерах Apache Spark, включая различные дистрибутивы Hadoop. Поскольку конвейеры Transformer работают на Spark, развернутом в кластере, конвейеры могут выполнять преобразования, требующие интенсивной обработки всего набора данных в пакетном или потоковом режиме. Принцип работы этой технологии можно представить следующим образом [2]:
- Transformer должен быть установлен на компьютер, настроенный для отправки заданий Spark в кластер, например, на узел данных (data node) Hadoop или облачную виртуальную машину;
- Аналогично Apache NiFi, доступ к пользовательскому интерфейсу Transformer осуществляется через браузер, в котором проектируется и запускается data pipeline. Эти конвейеры считывают данные из одного или нескольких источников, преобразуют их, выполняя нужные операции со всем набором данных, а затем записывают преобразованные данные в места назначения, работая в пакетном или потоковом режиме.
- При запуске конвейера Transformer он отправляет pipeline как Spark-приложение в кластер, где выполняется всю конвейерную обработку, включая сложные преобразования, такие как объединение, сортировка или агрегирование данных. Если конвейер запускается в кластере Hadoop, Transformer использует Spark Launcher API для запуска Спарк-приложения. В случае запуска конвейера в кластере Databricks, Transformer использует API REST Databricks для выполнения задания Databricks, которое, в свою очередь, запускает приложение Spark.
- Transformer передает определение конвейера в формате JSON в качестве аргумента приложения. Apache Spark запускает приложение в распределенном режиме, разделяя обработку между узлами кластера. Каждый этап конвейера представляет собой операцию Spark, например, при считывании данных из источника в пакетном режиме, источник представляет данные как DataFrame Spark и передает его следующей операции. О том, что представляет собой DataFrame и чем это отличается от других структур данных Apache Spark, мы рассказывали здесь. При отправке данных в место назначения Spark преобразует DataFrame в нужный формат данных, например, AVRO, JSON или Parquet, а затем записывает преобразованные данные в целевую систему.
- Во время работы Spark-приложения пользовательский интерфейс Transformer позволяет отслеживать хода выполнения конвейера, включая просмотр статистики в реальном времени и возникновение ошибок.
Таким образом, StreamSets Transformer работает как клиент Apache Spark, позволяя использовать его производительность и масштабируемость без необходимости писать собственное Java-, Scala- или Python-приложение на базе этого Big Data фреймворка.
2 data pipeline’а для пакетной и потоковой обработки больших данных с примерами
Итак, StreamSets Transformer обеспечивает оба режима обработки больших данных: пакетный и потоковый. Рассмотрим, как это выглядит на практических примерах [2].
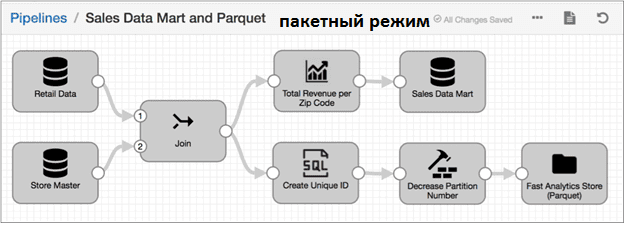
В пакетном режиме вычисления проводятся над данными, которые хранились в течение определенного периода времени в реляционной базе данных или в Data Lake на базе Apache Hadoop HDFS. Например, требуется создать витрину данных для отдела продаж (Sales Data Mart), включающую данные из таблиц Retail и StoreDetails существующего хранилища. При этом необходимо агрегировать данные перед их отправкой через операцию Join, чтобы рассчитать общий доход и количество заказов для каждого почтового индекса (Zip Code). Также нужно отправить одинаковые объединенные данные из таблиц Retail и StoreDetails в файлы Parquet, создав суррогатный ключ для повышения производительности аналитических запросов.
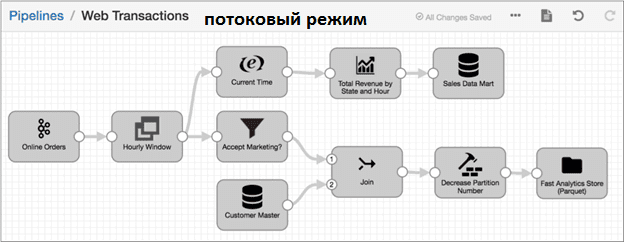
При потоковой обработке поддерживается соединение с исходными системами и выполняются вычисления через определенные пользователем интервалы. Data Pipeline работает непрерывно, пока не будет остановлен. Обычно такой потоковый конвейер используется для обработки данных на стриминговых платформах, таких как Apache Kafka. Например, транзакции веб-сайта (Online Orders) постоянно отправляются в Kafka и включают в себя идентификатор клиента, адрес доставки, идентификатор продукта, количество товаров, цену и информацию о маркетинговой кампании (Accept Marketing). Пусть требуется создать витрину данных для отдела продаж (Sales Data Mart), которая будет включать агрегированные данные об онлайн-заказах, включая общий почасовой доход для каждого региона. Поскольку данные транзакции поступают непрерывно, нужно создать одночасовые окна (Hourly Window) данных перед выполнением агрегированных вычислений и объединить через Join данные транзакций веб-сайта с подробными данными о тех клиентах, которые приняли маркетинговые предложения, из хранилища данных о клиентах (Customer Master). Эти объединенные данные следует записать в файлы Parquet для дальнейшей аналитики Big Data.
Подобные примеры аналитики больших данных, автоматизированные в виде ETL-конвейеров, могут быть реализованы и на базе полностью открытых Big Data технологий, таких как Apache Kafka, Nifi и Spark. Пример подобного конвейера мы рассмотрим в следующий раз.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Освоить все тонкости администрирования и эксплуатации Apache Hadoop, Spark, Kafka и NiFi для аналитики больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Анализ данных с Apache Spark
- Кластер Apache NiFi
- Администрирование кластера Kafka
- Hadoop для инженеров данных
Источники
- https://databricks.com/blog/2019/11/06/automate-and-fast-track-data-lake-and-cloud-etl-with-databricks-and-streamsets/
- https://streamsets.com/documentation/transformer/latest/help/transformer/GettingStarted/GettingStarted-Title/

