 917
917 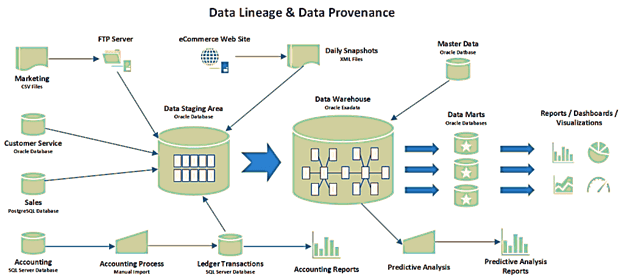
Содержание
В этой статье мы продолжим разговор про основы управления данными и рассмотрим, что такое data provenance и data lineage, чем похожи и чем отличаются эти понятия. Также разберем, почему эти термины особенно важны для Big Data, какие инструменты помогают работать с ними, а также при чем здесь GDPR.
Что такое Data lineage и Data provenance
Прежде всего отметим, что оба термина имеют достаточно близки друг к друг по значению. Они даже переводятся на русский язык одинаково – «происхождение данных». Однако, считать их синонимами не совсем корректно.
Data lineage (линия данных) – информация, которая описывает движение данных от источника их происхождения по точкам обработки и применения. Эти метаданные обеспечивают наглядность, позволяя отследить ошибки и выявить основные причины их появления в процессе анализа. Благодаря Data lineage можно воспроизводить отдельные участки или входы потока данных для пошаговой отладки или восстановления потерянного результата. Визуализации линии данных наглядно показывает, как они преобразуются, каким образом меняется их представление и параметры, а также как информационные потоки разделяются и сходятся [1].
Таким образом, Data lineage – это часть более широкого понятия, которое называется происхождение данных (data provenance). Data lineage предоставляет подробное описание того, откуда берутся данные, включая аналитику их жизненного цикла. Data provenance хранит исторические записи о непосредственном происхождении данных, включая связанные с ними входы, объекты, системы и процессы. Provenance фокусируется на происхождении данных, что позволяет определять их качество, идентифицировать источники, отслеживать ошибки и воспроизводить обновления. Также эти метаданные помогают сортировать информации в хранилище, задавая соответствующие контрольные журналы [2].
Иными словами, Data Lineage представляет собой запись о передаче данных из одной точки в другую, тогда как Data Provenance – это подробное документирование данных с целью обеспечения их воспроизводимости. Data Lineage объясняет, откуда поступили данные, а Data Provenance – это инструкция для их воссоздания [3].
Зачем отслеживать происхождение и жизненный цикл данных и при чем здесь Data Management
В мире Big Data, когда информации становится все больше, Data lineage и provenance позволяют управлять данными, реализуя следующие задачи Data Governance [4]:
- обеспечение качества данных за счет однозначной идентификации их источников;
- повышение доверия к данным через прозрачность всех процессов работы с ними;
- помощь в операционной деятельности Data Steward’а, включая разработку требований к датасетам и проектирование новых конвейеров обработки данных (data pipelines), благодаря полноте представления метаданных и сведений об их изменении в точках трансформации данных.
Также Data Lineage и Provenance обеспечивают полный аудит данных, что особенно важно для соблюдения нормативных актов, таких как GDPR (General Data Protection Regulation) [3]. Напомним, этот генеральный регламент о защите персональных данных (ПД) граждан и резидентов Евросоюза предусматривает наличие политики защиты ПД (Privacy Policy), которая описывает общую информацию по обработке ПД, сведения о целях и характере обработки.
С технической точки зрения Data Lineage и Provenance помогают обеспечить непротиворечивость данных, связывая их метаданные в разрозненных системах на логическом уровне. Еще они позволяют ответить на вопрос Data Engineer’a, какой именно файл, обработанный заданием MapReduce, создал эту конкретную выходную запись. Или, например, в каком топике Apache Kafka, датасет обогатился новыми данными об уже существующих объектах. Это может быть полезно при отладке различных ETL/ELT-процессов, операторов и контроля гранулярности потока данных [1].
Происхождение и линейка данных помогают повысить качество моделей машинного обучения (Machine Learning) и графовой аналитики. Интересны следующие применения Data Lineage и Provenance в Data Science [5]:
- нахождение скрытых закономерностей в разрозненных данных с учетом информации об источниках и трансформациях объектов;
- алгоритмы Machine Learning, в частности, глубокое обучение, могут использовать информацию о том, как именно пользователи работают с данными, чтобы распознавать речь, изображения или видео, а также решать другие подобные задачи;
- обогащение датасетов за счет графового анализа узлов линейки данных.
Инструменты Big Data для работы с lineage и provenance
С инструментальной точки зрения Lineage и Provenance поддерживаются следующими средствами работы с большими данными [6]:
- готовые решения по управлению данными, например, SAP Data Services, Informatica Metadata Manager и прочие специализированные системы;
- уникальные разработки на базе open-source проектов стека Big Data, например, интеграция Apache Hadoop, Spark, Kafka и ETL-инструментов (Airflow, NiFi).
Таким образом, визуализация Lineage и Provenance представляет собой отображение конвейера данных. Например, задание ETL выполняет преобразование необработанных данных из HDFS в таблицу отношений Spark SQL. Далее задание машинного обучения считывает данные из этой таблицы, использую Spark MLLib для обучения модели на основе исторических данных, хранящихся в HDFS. Эта модель Machine Learning используется заданием потоковой передачи Spark, обогащаясь непрерывным потоком входных данных из топика Apache Kafka. Итоговые результаты записываются в другой топик Kafka [7]. Конвейер пакетной ETL-обработки можно визуализировать с помощью DAG-графа в графической веб-GUI Apache Airflow, а потоковой – в Apache NiFi.
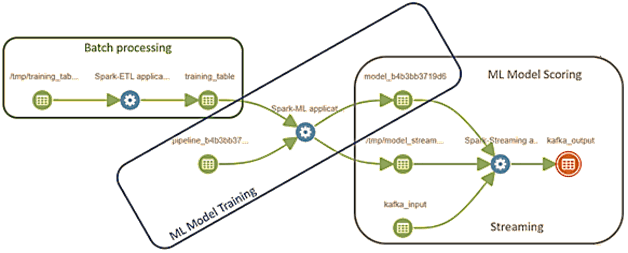
Таким образом, Lineage и Provenance – это не только высокоуровневые понятия Data Governance (Data Management), но и глубоко технические термины, которые демонстрируют трассировку потока Big Data в таблицы и файлы, а также все возможные преобразования с ними. Поэтому знать эти понятия нужно каждому специалисту по работе с большими данными: инженеру, архитектору, аналитику, исследователю и разработчику. В следующей статье мы рассмотрим, какие еще знания полезны для профессиональной работы с большими данными и где они описаны.
Больше подробностей про управление большими данными с помощью lineage и provenance вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://en.wikipedia.org/wiki/Data_lineage
- https://www.talend.com/resources/what-is-data-lineage-and-how-to-get-started/
- https://www.dataversity.net/know-data-came/
- http://grandlogic.blogspot.com/2019/09/do-know-where-your-data-lake-has-been/
- https://www.sas.com/ru_ru/insights/articles/data-management/data-lineage—making-artificial-intelligence-smarter/
- https://medium.com/dailymotion/getting-started-with-data-lineage-6307b2b429b3
- https://blog.cloudera.com/data-science-engineering-platform-data-lineage-provenance-apache-spark/

