 863
863 
Содержание
Завершая разговор про ETL-инструменты Big Data и цикл статей об Apache NiFi (ANF), сегодня мы сравним его со StreamSets Data Collector (SDC): чем похожи и чем отличаются эти системы маршрутизации данных. Также рассмотрим, в каких случаях следует выбирать ту или иную платформу и почему.
Что общего между Apache NiFi и StreamSets Data Collector: 5 основных сходств
Итак, прежде всего, отметим, чем похожи Apache NiFi и StreamSets Data Collector. Проанализировав эти платформы маршрутизации и загрузки данных, мы выделили 5 ключевых критериев, по которым они очень близки:
- прикладное назначение – обе системы активно используются в качестве ETL-инструментов в комплексных проектах Big Data и интернете вещей (Internet of Things, IoT), в т.ч. индустриальном (Industrial IoT, IIoT). О примерах практического использования SDC мы рассказывали здесь, а кейсы применения ANF описывали в этом материале.
- Открытый исходный код – обе платформы написаны на Java и распространяются по лицензии Apache 2.0. При том, что первый релиз NiFi появился в 2007 году, только в 2014 он был передан NSA фонду Apache Software Foundation. В это же время один калифорнийский стартап (США) выпустил первую версию StreamSets Data Collector в качестве, выложив исходный код своего проекта на GitHub. Первый официальный релиз StreamSets Data Collector вышел в июне 2015 [1].
- Режимы работы – обе системы могут работать как локально, так и в кластере. Однако, если NiFi может работать автономно в распределенном режиме, используя собственную систему управления кластером, то для распределенного функционирования SDC необходим дополнительный менеджер ресурсов YARN или Mesos. Отметим также, что, несмотря на позиционирование в качестве потоковых ETL-средств, и NiFi и SDC могут работать с пакетами [1].
- Интеграция со множеством сторонних систем – Apache Hadoop (HDFS, HBase, Hive), NoSQL-СУБД (Cassandra, MongoDB), поисковыми системами (Apache Solr, Elasticsearch), реляционными СУБД (Oracle, MS SQL Server, MySQL, PostgreSQL, Netezza, Teradata), системами управления очередями сообщений (Apache Kafka, JMS, Kinesis, RabbitMQ), локальными и облачными файловыми хранилищами (Amazon S3 и т.д.). При этом взаимодействие StreamSets Data Collector с реляционными СУБД реализуется за счет поддержки JDBC [2], а в Apache NiFi подобная коммуникация обеспечивается самостоятельным добавлением соответствующего JDBC-драйвера. Для расширения функциональных возможностей у Apache NiFi с целью подключения дополнительных приемников или преобразователей данных имеется собственный API-интерфейс. Работа с любыми форматами неструктурированных, полуструктурированных и структурированных данных (Avro, JSON, CSV, Grok), включая двоичные файлы, в Apache NiFi и StreamSets Data Collector реализуется с помощью встроенного реестра разных схем данных (Schema Registry), аналогично тому, как это выполняется в Apache Kafka.
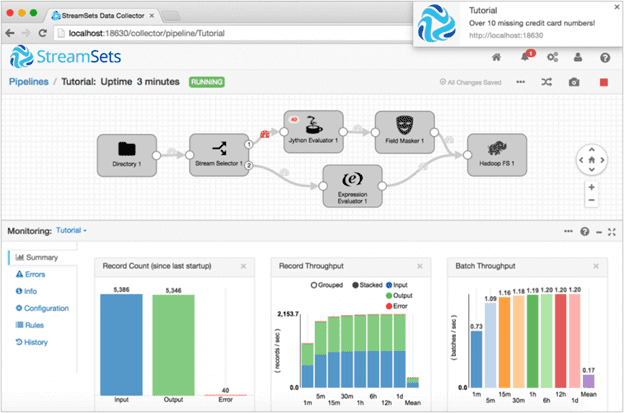
- графический интерфейс – обе системы имеют наглядный GUI, однако интерфейс SDC считается более привлекательным и понятным. Тем не менее, с точки зрения удобства пользования иногда чрезмерная простота ANF становится конкурентным преимуществом этой платформы. В частности, StreamSets Data Collector подсвечивает синтаксис SQL-запросов, что существенно снижает скорость их отображения. Хотя, стоит признать, что в целом интерфейс SDC гораздо более насыщенный и функциональный. Например, Apache NiFi не изменяет автоматически размеры текстовых полей для длинных SQL-запросов, поэтому придется вручную изменять размер всплывающих текстовых полей каждый раз, когда их необходимо отредактировать [1].
Чем отличается Apache NiFi от StreamSets Data Collector: 3 главных характеристики
Несмотря на множество общих моментов, разница между Apache NiFi и StreamSets Data Collector особенно выражена по следующим ключевым параметрам:
- информационный примитив – ANF работает с потоковыми файлами FlowFile, внутри которых скрыты исходные данные с прикрепленной к ним метаинформацией. При загрузке данных в SDC они автоматически конвертируются в линейный формат, ориентированный на записи, и в дальнейшем обрабатываются как поток записей. Благодаря этому в SDC ответственность за понимание формата данных лежит не на отдельном процессоре, как в NiFi, и не требуется преобразование форматов при взаимодействии разных обработчиков событий [3].
- реализация вычислений – из-за разных информационных примитивов, специфика процессоров (обработчиков событий) в рассматриваемых ETL-платформах также существенно отличается друг от друга. В частности, благодаря тому, что ANF работает с потоковыми файлами FlowFile, каждый обработчик событий работает с отдельной порцией данных. Поэтому в случае ошибки программного кода обработчика или при отладке, в NiFi можно остановить лишь конкретный процессор, а не весь поток данных, как в StreamSets Data Collector. Впрочем, это не слишком усложняет отладку конвейера данных в SDC, в графическом интерфейсе которого показываются ошибки каждого из процессоров. Также стоит отметить разное количество типов у обработчиков событий: в ANF различаются типы выходов процессора (ошибка, успех и приемо-передатчик данных), а в StreamSets Data Collector выделяют 4 типа процессоров (приемник, преобразователь, обработчик и передатчик во внешнюю систему) [1].
- Локализация данных – использование нужных кодировок. На практике при использовании в SDC могут возникнуть проблемы с кириллицей. Это может быть критично в случае применения StreamSets Data Collector в русскоязычном сегменте, например, при разработке собственной BI-системы. В ANF подобная проблема с кодировками не отмечалась [4].
Аргументы в пользу Apache NiFi
Итак, основными достоинствами Apache NiFi можно назвать следующие возможности [1]:
- многоразовое использование JDBC-конфигураций для обработчиков, тогда как в SDC требуется каждый раз задавать нужные настройки вручную.
- избирательный останов отдельных процессоров из всего запущенного конвейера, а не всего потока данных, как в SDC;
- поддержка локальных данных – отсутствие проблем с кириллицей и другими кодировками [4].
Когда выбирать StreamSets Data Collector вместо NiFi
Справедливости ради стоит отметить, что SDC также обладает некоторыми конкурентными преимуществами относительно Apache NiFi. В частности, это:
- мощный графический интерфейс, включающий оперативный мониторинг процесса отладки и обработки каждой записи для каждого процессора [1];
- повышенная (по сравнению с Apache NiFi) эффективность работы с линейными форматами данных (AVRO, Sequence) т.к. идет работа с непрерывным потоком линейных записей и не требуется преобразование форматов при обмене данными между разными обработчиками [3].
Подробнее о том, как устроен StreamSets, каким образом он связан с Apache Spark и что позволяет запускать на этой платформе ETL-конвейеры обработки и маршрутизации больших данных, мы рассказываем в этой статье.
Подводя итог описанию сходств и различий Apache NiFi и StreamSets Data Collector, уникальным преимуществам этих ETL-платформ, а также особенностям их применения в Big Data и IoT/IIoT-проектах, можно сделать вывод, что, несмотря на некоторую специфику, обе эти системы могут успешно использоваться на практике для загрузки и маршрутизации множества потоковых и пакетных данных из различных источников.
Все особенности практического использования, установки, администрирования и настройки ETL-инструментов в Big Data и IoT/IIoT разбираются на нашем практическом курсе Кластер Apache NiFi в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве.
Источники
- https://statsbot.co/blog/open-source-etl/
- https://github.com/streamsets/datacollector
- http://qaru.site/questions/265108/difference-between-apache-nifi-and-streamsets
- https://axmor.ru/blog/kak-primieniat-apache-nifi-v-bi-proiektakh/

