 1394
1394 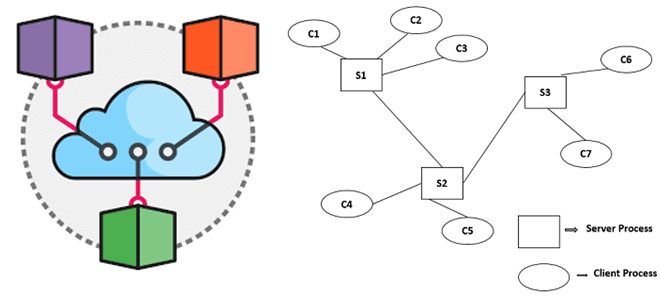
Содержание
Недавно мы писали про архитектурный шаблон CQRS и его реализацию на базе Apache Kafka. В продолжение этой темы для обучения ИТ-архитекторов и разработчиков Big Data приложений, сегодня рассмотрим еще несколько популярных шаблонов проектирования распределенных систем: достоинства, недостатки, примеры реализации и способы их использования.
Шаблоны проектирования распределенных систем: что это и зачем нужно
Шаблоны проектирования в разработке ПО – это проверенные способы построения систем, каждый из которых подходит для конкретного варианта использования. Это не конкретные реализации, а абстрактные способы структурирования системы, своего рода строительные блоки, которые позволяют программистам опираться на существующие знания, а не начинать проектирования с нуля каждый раз. Они включают набор стандартных моделей для проектирования систем, которые помогают понять, как разрабатываемый проект будет взаимодействовать с внешним окружением и обрабатывать данные. Порождающие шаблоны проектирования обеспечивают основу при создании новых объектов. Структурные шаблоны определяют общую структуру решения. Поведенческие паттерны описывают объекты и то, как они взаимодействуют друг с другом.
Для распределенных систем шаблоны проектирования представляются в парадигме использования набора вычислительных узлов и центров обработки данных как одного компьютер для конечного пользователя. Эти шаблоны распределенного проектирования описывают программную архитектуру взаимодействия между разными узлами, особенностей обработки отдельных задач и потока процессов для разных задач. Такие паттерны применяются для проектирования распределенной системной архитектуры крупномасштабных облачных вычислений и масштабируемых микросервисов.
В зависимости от прикладного назначения, все шаблоны проектирования можно разделить на несколько категорий:
- связь с объектом, который описывает протоколы обмена сообщениями и разрешения для обмена данными между различными компонентами системы;
- безопасность, что решает вопросы конфиденциальности, целостности и доступности для защиты системы от несанкционированного доступа;
- управляемые событиями – описание процессов генерации, обнаружения, потребления и реакции на системные события.
Как это описано в паттернах CQRS, 2PC, Saga, RLBS и общей шины, рассмотрим далее.
Разделение ответственности команд и запросов (CQRS)
Паттерн CQRS (Command Query Responsibility Segregation) фокусируется на разделении операций чтения и записи распределенной системы для повышения масштабируемости и безопасности. В этой модели используются команды для записи данных в постоянное хранилище и запросы для поиска и извлечения данных. Они обрабатываются командным центром, который получает запросы от пользователей, извлекает данные и вносит необходимые изменения, затем сохраняет данные и уведомляет сервис чтения. Сервис чтения обновляет модель чтения, чтобы показать изменение пользователю.
Основными преимуществами CQRS являются следующие:
- снижение сложности системы за счет делегирования задач;
- четкое разделение между бизнес-логикой и валидацией;
- легкая классификация процессов по принципу работы;
- сокращение количества неожиданных изменений в общих данных;
- уменьшение количества сущностей, которые имеют доступ к изменению данных.
Обратной стороной этих достоинств являются следующие недостатки:
- необходимость поддерживать постоянную обратную связь между командами и моделями чтения;
- увеличение задержки при отправке запросов с высокой пропускной способностью;
- отсутствие средств для связи между сервисными процессами.
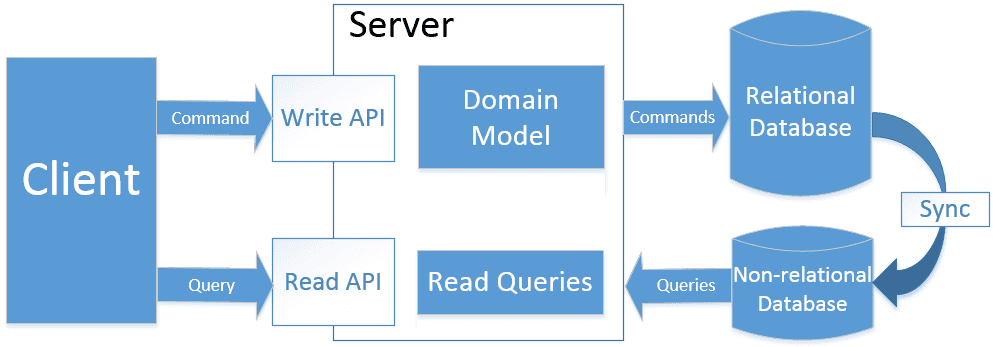
CQRS отлично подходит для приложений с интенсивным использованием данных, таких как реляционные или NoSQL-СУБД, а также микросервисные архитектуры крупных Big Data систем. Благодаря разделению чтения и записи, CQRS применим для stateful-приложений. Сегодня популярной технологией реализации паттерна CQRS для микросервисной архитектуры является платформа Apache Kafka, которая обеспечивает согласованность и полноту данных, гарантируя, что потоковое stateful-приложение сможет восстановиться после сбоя без дублей и потери записей. Подробнее об этом мы писали здесь.
Двухфазная фиксация (2PC)
Two-Phase Commit или 2PC похож на CQRS своим транзакционным подходом и зависимостью от центральной команды, но разделы обрабатываются в зависимости от их типа и стадии завершения, на которой они находятся. В фазе подготовки центральный элемент управления сообщает службам о необходимости подготовить данные, а фаза фиксации сигнализирует службе отправить подготовленные данные.
Все сервисы в системе 2PC по умолчанию заблокированы, то есть они не могут отправлять данные. Пока сервисы заблокированы, они завершают этап подготовки, чтобы быть готовыми к отправке после разблокировки. Координатор разблокирует сервисы один за другим и запрашивает их данные. Если сервис не готов предоставить свои данные, координатор переходит к другому сервису. После отправки всех подготовленных данных все сервисы разблокируются в ожидании новых задач от координатора. 2PC гарантирует, что одновременно может работать только одна служба, что делает процесс более устойчивым и последовательным, чем CQRS.
Паттерн Two-Phase Commit обладает следующими преимуществами:
- устойчивость к ошибкам из-за отсутствия одновременных запросов;
- отличная масштабируемость — возможность обрабатывать огромные объемы данных;
- изоляция и обмен данными одновременно.
Из недостатков стоит отметить подверженность узким местам и блокировкам из-за синхронности, а также потребность в большем количестве ресурсов, чем другие шаблоны проектирования. 2PC подходит для распределенных транзакционных систем (OLTP), где точность важнее эффективной утилизации ресурсов. Почему вместо этого паттерна лучше использовать шаблон Transactional Outbox, читайте в нашей новой статье.
Saga
Saga — это асинхронный шаблон, который не использует центральный контроллер, а обеспечивает взаимодействие между сервисами. Это устраняет некоторые недостатки рассмотренных ранее синхронных шаблонов. Saga использует шину событий для взаимодействия разных служб в микросервисной системе. Шина отправляет и получает запросы между сервисами, и каждый сервис создает локальную транзакцию, генерируя событие для получения другими службами. Все остальные службы прослушивают события. Первая служба, получившая событие, выполнит требуемое действие. Если этой службе не удается выполнить действие, оно отправляется другим службам.
Этот шаблон похож на 2PC тем, что службы зацикливаются, если невозможно выполнить задачу. Но Saga удаляет центральный элемент управления, чтобы лучше управлять потоком и уменьшить объем необходимой обратной связи. Это дает следующие преимущества:
- отдельные сервисы могут обрабатывать гораздо более длительные транзакции;
- подходит для распределенной системы из-за децентрализации;
- устраняет узкие места благодаря одноранговой связи между службами.
Но асинхронная автономия затрудняет отслеживание того, какие службы выполняют отдельные задачи. Оркестровка становится сложнее, а отдельные сервисы менее изолированы друг от друга.
Тем не менее, децентрализованный подход Saga отлично подходит для масштабируемых бессерверных функций, которые обрабатывают множество параллельных запросов одновременно.
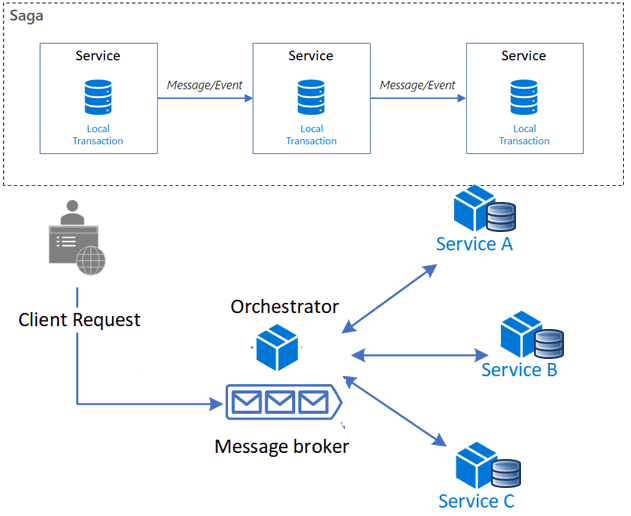
В частности, AWS использует дизайн на основе Saga в лямбда-функциях. Например, AWS Lambda позволяет запускать программный код без выделения серверов и управления ими – пользователь платит только за фактическое время вычисления. Lambda позволяет выполнять код практически любого приложения или серверного сервиса без администрирования: достаточно загрузить программный код, и Lambda обеспечит все ресурсы, необходимые для его исполнения, масштабирования и обеспечения высокой доступности. Можно настроить автоматический запуск программного кода из других сервисов AWS или вызывать его непосредственно из любого приложения. Подробнее про бессерверный подход и его применение к приложениям и кластерам Kafka читайте в нашей новой статье.
Реплицированные службы с балансировкой нагрузки (RLBS)
Replicated Load-Balanced Services (RLBS) является самым простым и наиболее часто используемым шаблоном проектирования. Он состоит из нескольких идентичных служб, которые отчитываются перед центральным балансировщиком нагрузки. Каждая служба способна обрабатывать задачи и может реплицироваться в случае сбоя. Балансировщик нагрузки получает запросы от конечного пользователя и распределяет их по службам циклически или иногда с использованием более сложного алгоритма маршрутизации.
Дублирование сервисов гарантирует, что приложение поддерживает высокую доступность для пользовательских запросов и может перераспределить работу в случае сбоя одного экземпляра службы. RLBS часто используется с Kubernetes — технологией оркестрации контейнеров с открытым исходным кодом, которая предлагает автоматическое масштабирование службы на основе рабочего процесса. Главными плюсам RLBS являются следующие:
- стабильная производительность с точки зрения конечного пользователя;
- быстрое восстановление сервиса после отказа;
- высокая масштабируемость с большим количеством сервисов;
- высокий уровень параллелизма.
Однако, RLBS недостаточно производителен из-за алгоритма балансировки нагрузки и требует много ресурсов для управления сервисами. Этот паттерн подходит для систем, которые имеют непостоянную рабочую нагрузку в течение дня, но должны поддерживать низкую задержку, например, онлайн-кинотеатр.
Сегментированные сервисы (sharded services)
Вместо реплицирования сервисов можно распределить их по наборам, каждый из которых выполняет только определенный тип запроса. Это называется сегментированием (sharding), т.к. поток запросов разделяется на несколько неравных частей. Например, один у вас может быть одна служба сегментов, которая принимает все запросы на кэширование, а другая — только запросы с высоким приоритетом. Балансировщик нагрузки оценивает каждый поступающий запрос и распределяет его по соответствующему сегменту для выполнения.
Этот шаблон проектирования обычно применяется для stateful-сервисов, где размер состояния слишком велик для одного контейнера. Шардирование позволяет масштабировать отдельный сегмент в соответствии с размером состояния.
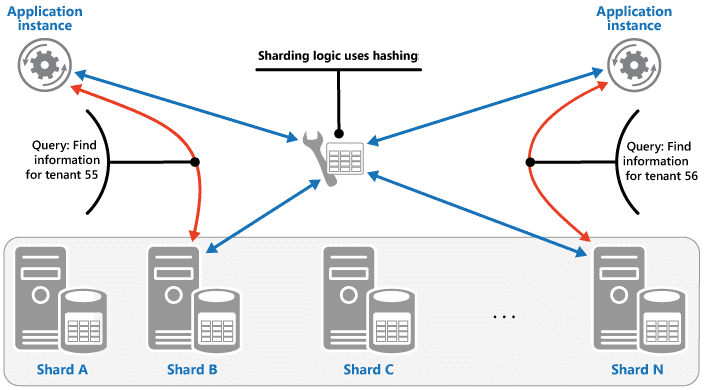
Сегментированные сервисы также позволяют быстрее обрабатывать высокоприоритетные запросы, т.к. они всегда доступны для обработки в момент их поступления запросов, а не для их помещения в очередь. Sharded services хорошо масштабируются и приоритизируют запросы, а также легко отлаживаются благодаря естественной сортировке. Однако, сегментированные сервисы могут потреблять много ресурсов для обслуживания множества осколков и склонны к потере производительности при непропорциональном использовании шардов. Этот паттерн подходит для систем с предсказуемым дисбалансом запросов разных типов и различным приоритетом.
Узнайте все про проектирование архитектуры, разработку и реализацию распределенных приложений с Apache Hadoop, Kafka, Spark и AirFlow для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники

