 1174
1174 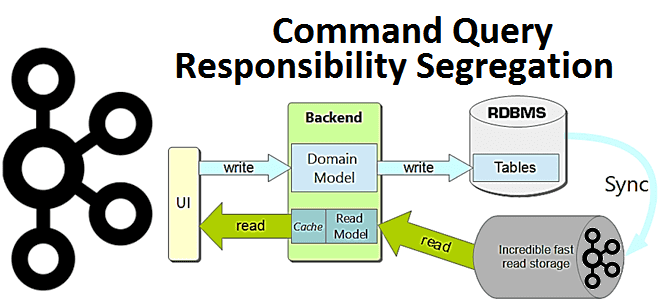
Содержание
В этой статье для разработчиков распределенных приложений и ИТ-архитекторов разберем достоинства и недостатки паттерна проектирования CQRS, а также рассмотрим пример его реализации на Apache Kafka, Spring Cloud Stream и MongoDB.
Что такое CQRS: основы проектирования архитектуры приложений
Спрос на приложения, управляемые событиями, постоянно растет как для решения новых бизнес-задач, так и для развития существующих, которые ранее решались с помощью монолитных информационных систем. При этом новые сервисы должны без проблем взаимодействовать даже устаревшими архитектурами. Реализовать это можно с помощью шаблона разделения ответственности за запросы команд под названием CQRS. Паттерн CQRS (Command Query Responsibility Segregation) основан на идее того, что модели обновления и чтения информации могут различаться. Это отличается от распространенного подхода проектирования информационных систем в разрезе CRUD-операций (Create, Read, Update, Delete): все взаимодействия пользователя или внешних сервисов с данными связаны с хранением и извлечением записей из хранилища.
Но современная информационная система – это не просто хранилище записей и интерфейс доступа к ним. По мере развития бизнес-логики и роста данных появляются более сложные варианты использования. Например, объединение несколько записей в одну или формирование виртуальных записей на основе информации для разных мест. При обновлении могут быть правила проверки, которые позволяют сохранять только определенные комбинации данных или предполагать сохранение данных, отличных от предоставленных пользователем. Таким образом, появляются множественные представления информации, с которыми взаимодействуют разные пользователи. При этом используются элементы концептуальной модели данных, которая состоит из ключевых в данном контексте сущностей предметной области и связей между ними. Чаще всего подобную концептуальную модель представляют в виде ER-диаграммы или диаграммы классов UML.
CQRS предлагает разделить эту концептуальную модель на отдельные модели для обновления (Command) и отображения (Query). Под отдельными моделями понимаются разные объектные модели, которые могут работать в разных логических процессах и даже на разных аппаратных средствах. Например, пользователь просматривает веб-страницу, отображаемую с использованием модели запроса. Если пользователь инициируют изменение, оно направляется в отдельную модель команд для обработки, а результирующее изменение передается в модель запроса для отображения обновленного состояния.
При этом разные модели могут совместно использовать одну и ту же базу данных, которая в этом случае будет средством связи между ними. Также разные модели могут использовать отдельные базы данных, что дает преимущество обработки на стороне запроса в реальном времени. Но в этом случае нужен механизм связи между двумя моделями или их базами данных. Впрочем, модели Command и Query могут не быть отдельными объектными моделями: одни и те же объекты будут иметь разные интерфейсы подобно представлениям в реляционных базах данных. Но чаще всего CQRS реализуется разделением моделей и сочетается с некоторыми другими архитектурными шаблонами. Как команда облачного ETL-оркестратора Dagster Cloud Решила реализовать CQRS-паттерн, используя объектно-реляционную базу данных PostgreSQL вместо очереди сообщений на Apache Kafka, и что из этого вышло, читайте в нашей новой статье.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
12 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Таким образом, отход от единого представления с CRUD-взаимодействием пользователя с данными позволяет перейти к моделям программирования на основе событий. Чаще всего система CQRS разделена на отдельные сервисы, взаимодействующие с хранилищем событий. Разумеется, при этом следует поддерживать согласованность разных моделей, что обычно предполагает согласованности в конечном счете (eventual consistency). О сложностях обеспечения конечной согласованности в распределенных системах мы писали здесь и здесь. Для большинства систем CQRS добавляет рискованную сложность, но может быть полезен в следующих случаях:
- подходит для сложных доменов, которые выигрывают от доменно-ориентированного проектирования (Domain-Driven Design) с перекрытием зон ответственности между командами разработки и клиентов, от которых поступают запросы. CQRS упрощает совместное использование модели информационной системы.
- независимое масштабирование операций чтения и записи в высокопроизводительных приложениях, т.к. их можно отделить друг от друга и применить разные стратегии оптимизации. Например, использование различных методов доступа к базе данных для чтения и обновления.
Идеи паттерна CQRS и микросервисной архитектуры сегодня часто реализуются на платформе Apache Kafka, которая обеспечивает согласованность и полноту данных, гарантируя, что потоковое stateful-приложение сможет восстановиться после сбоя без дублей и потери записей. Как это может выглядеть на практике, мы рассмотрим далее.
Пример реализации на Apache Kafka
Чтобы показать некоторые особенности реализации паттерна CQRS для модели чтения, рассмотрим следующую архитектуру системы:
- Spring Cloud Stream для обработки событий. Эта часть группы проектов Spring Cloud основана на фреймворке Spring Boot и использует Spring Integration для легкой интеграции с разными брокерами сообщений (RabbitMQ, Kafka, Amazon Kinesis, PubSub, RocketMQ и пр.). Spring Cloud Stream помогает в обмене сообщениями между двумя приложениями или микросервисами, требуя минимальной настройки конфигурации. По сути, Spring Cloud Stream предлагает интерфейс для разработчиков, абстрагируясь от особенностей базового брокера. Связь с брокером и обратно от брокера осуществляется также через библиотеку Stream, причем все брокеры обрабатываются одинаково: Spring Cloud Stream нормализует их поведение.
- MongoDB — документо-ориентированная NoSQL-СУБД, не требующая описания схемы таблиц, которая использует JSON-подобные документы и схему базы данных для хранения моделей чтения;
- Apache Kafka в качестве распределенной платформы потоковой передачи событий и брокера сообщений.
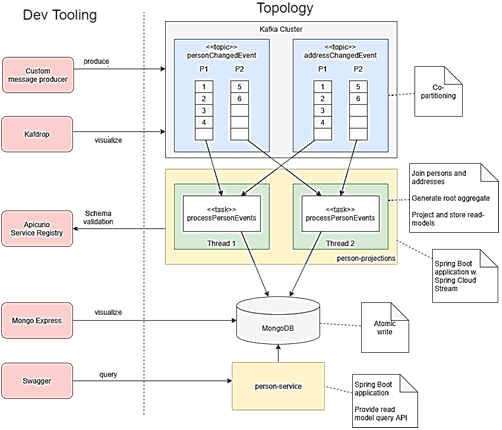
Топик Kafka получает события изменений, как только запись о человеке (person) меняется в базовой системе-источнике, где конкретное событие генерируется с помощью CDC-технологии (Change Data Capture), т.е. через захват измененных данных. Подробнее о CDC-подходе мы писали здесь, здесь и здесь. Например, базовая система-источник хранит один или несколько адресов (address) человека отдельно, причем нет гарантии, что хотя бы один из них является актуальным. Необходимо объединить людей и их адреса, создав корневой агрегат для дальнейшего прогнозирования модели чтения. Причем каждое событие должно содержать не только изменение состояния, но и полную историю предыдущих изменений. Код приложения-потребителя Kafka Streams с методом соединения данных может выглядеть следующим образом:
@Bean
public BiConsumer<KTable<String, PersonChangedEvent>, KTable<String, AddressChangedEvent>> processPersonEvents(
ProjectorService projectorService,
MappingContext mappingContext) {
return (personChangedEvents, addressChangedEvents) -> {
personChangedEvents
.mapValues(personChangedEvent -> PersonAggregateRoot.empty().apply(personChangedEvent, mappingContext))
.join(addressChangedEvents, ((root, addressChangedEvent) -> root.apply(addressChangedEvent, mappingContext)))
.mapValues(projectorService::project)
.mapValues(PersonAggregateRoot::getPersonId)
.toStream()
.foreach((k, v) -> log.info("Read model updated for key '{}' and personId '{}'", k, v));
};
}
Создать топик Kafka поможет следующая команда:
#!make
KAFKA_BOOTSTRAP_SERVER=localhost:9092
KAFKA_TOPICS_FILE=./config/kafka/topics.txt
kafka-topics-create:
awk -F':' '{ system("kafka-topics.sh --create --bootstrap-server ${KAFKA_BOOTSTRAP_SERVER} --topic="$$1" --partitions="$$2" --replication-factor="$$3" --config="$$4) }' \
${KAFKA_TOPICS_FILE}
.PHONY: kafka-topics-create
Поскольку каждое событие также содержит историю, можно настроить и сжать вовлеченные топики Kafka (источник событий не требуется), чтобы переключаться с таблиц KTables на потоки KStreams в методе соединения. При этом в памяти будет выполняться преобразование во внутренние KTables, где уже не придется создавать физически вспомогательные топики и дублировать данные с помощью Spring Cloud Streams.
Для сжатия топиков можно использовать простой текстовый файл, содержащий необходимые конфигурации:
# Explanation: topic name, partition count to be a multiple of the number of stream threads, replication count, policy person-changed-events:10:1:cleanup.policy=compact address-changed-events:10:1:cleanup.policy=compact
Чтобы повысить производительность за счет облегченного масштабирования и снизить задержку при проверке схемы сообщений в реестре и записи моделей в MongoDB в рамках отдельного рабочего потока, используется функция совместного разделения для нескольких потоков, которые обрабатывают соединения person-address. Конфигурация Spring может выглядеть при этом так:
spring:
cloud:
stream:
bindings:
processPersonEvents-in-0:
destination: person-changed-events
processPersonEvents-in-1:
destination: address-changed-events
default:
resetOffsets: true
startOffsets: earliest
kafka:
streams:
binder:
configuration:
num.stream.threads: 2
Чтобы оптимизировать конфигурации локальной настройки рассматриваемой архитектуры, можно реализовать настраиваемый инструмент создания сообщений. С использованием реестра схем Kafka и клиентской библиотеки AVRO можно создавать новые события локально, а также гибко тестировать изменения в схемах событий, которые нельзя сразу публиковать в реальном реестре. Для быстрого и простого обнаружения топиков Kafka без необходимости запрашивать их через CLI-интерфейс пригодится Kafdrop — пользовательский интерфейс с открытым исходным кодом для мониторинга Кафка-кластеров, который отображает информацию о брокерах, топиках, разделах и позволяет просматривать сообщения. Это легкое приложение на Spring Boot легко настраивается и предоставляет полезную информацию о тематических разделах, смещениях, событиях и многом другом. Об этом и других средствах мониторинга кластеров Apache Kafka мы писали здесь.
Для проверки моделей чтения, проецируемых и хранящихся в MongoDB подойдет официальный инструмент Mongo Express, предлагающий статистику документов и запросов, а также другие полезные функции, которые упрощают анализ и отладку хранимых данных. Еще один подобный пример смотрите в нашем новом материале. А про другие паттерны проектирования распределенных систем читайте в этой статье.
В заключение отметим, что JMS-брокеры сообщений, с которыми часто сравнивают Apache Kafka не поддерживают паттерн проектирования CQRS, о чем мы подробно рассказываем здесь.
Узнайте все про архитектуры распределенных приложений, администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
[elementor-template id=»13619″]
Источники

