 1326
1326 
Содержание
В рамках обучения ИТ-архитекторов и разработчиков распределенных приложений рассмотрим, что представляет собой Transactional Outbox и как этот паттерн проектирования микросервисной архитектуры можно реализовать с помощью Neo4j и Apache Kafka, чтобы создать масштабируемый, общий и абстрактный способ запроса информации независимо от типа объекта.
Постановка задачи: проблемы микросервисной архитектуры и способы их обхода c Neo4j
Рассмотрим пример проектирования микросервисной архитектуры ПО, один из вариантов использования которого позволяет актору узнать, на какие сущности (любого типа) ссылается другая сущность и какими отношениями они связаны. Это можно реализовать с помощью паттерна Database Per Service, который позволяет применять для каждого сервиса наиболее подходящую для его задач СУБД. Но это создает проблему объединения информации, сохраняемой в отдельных базах данных. Поэтому требуется масштабируемый, общий и абстрактный способ запроса информации независимо от типа объекта.
Для наглядности рассмотрим пример, используя простые сущности Person и Film, которые связаны следующими отношениями: фильм может быть снят одним или несколькими людьми, а один человек может сниматься в одном или нескольких фильмах. В качестве атрибутов сущности Film выделим название и дате выпуска, а для Person – имя и дата рождения.
Для каждой сущности есть свой сервис: people-api и Movies-API, доступные через шлюз API. Сервис people-api предоставляет CRUD-функции для объекта Person через REST API, а служба Movies-API – для объекта Film также через REST API.
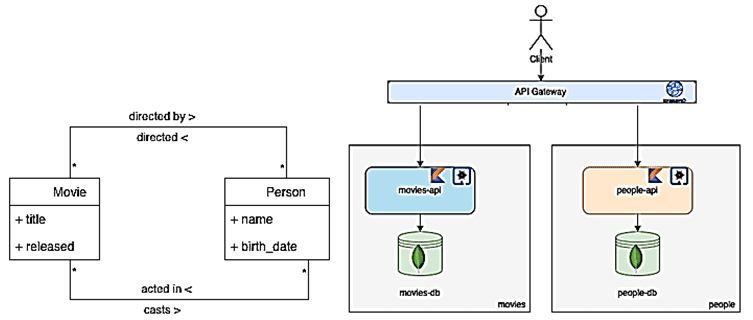
Предположим, необходимо узнать, какие фильмы были сняты конкретным человеком и с участием каких артистов, а также каковы их роли в этих фильмах. Это довольно сложный запрос, поскольку разные сущности хранятся в разных базах данных. Возможным решением будет синхронное межсервисное взаимодействие через шлюз API и агрегирование ответов, но сложно реализовать. Кроме того, такой подход увеличит связанность сервисов, что противоречит самой идее микросервисной архитектуры. Кроме того, подобное решение неприменимо в случае сотен или тысяч микросервисов, в случае множества бизнес-концепций с миллионами различных взаимосвязей.
Немного расширим исходную модель предметной области, добавив новую сущность Catalogue — каталог как именованная коллекция фильмов, у которой есть атрибут категория. Чтобы отразить эту модель предметной области, потребуется создать новый микросервис, отвечающий за работу с новой сущностью – catalogue-api.
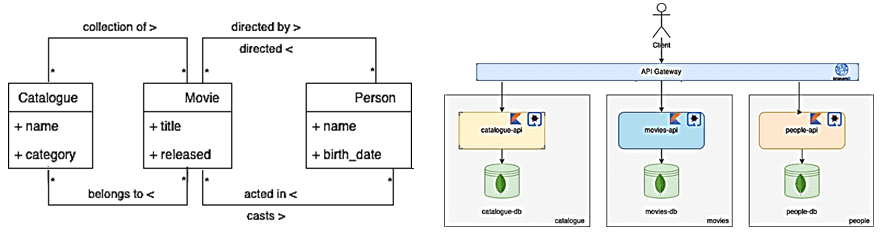
В этом случае у пользователя есть возможность узнать, какие каталоги ссылаются на конкретного человека, хотя в каталогах нет прямых ссылок – они ссылаются на фильмы, которые ссылаются на людей. Таким образом, модель предметной области можно представить как граф, где узлы отображают сущности, а ребра — их отношения.
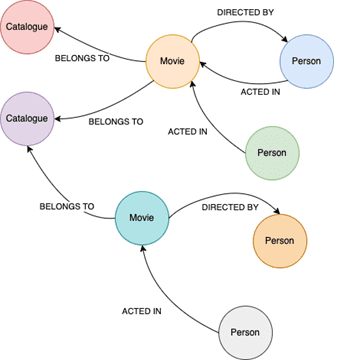
Реализовать эту идею можно, создав новый сервис с графовой СУБД Neo4j, где будут храниться все объекты и их отношения. Этот сервис сможет выполнять все сложные запросы более удобным и простым способом, используя язык запросов Cypher для обхода графа с любой длиной взаимосвязи. Однако, как объединить все данные, хранящиеся в разных базах, и сохранить их в одну, обеспечивая согласованность? Ответом на этот вопрос может стать другой паттерн проектирования микросервисной архитектуры, который мы рассмотрим далее.
Сбор измененных данных с паттерном Outbox на Apache Kafka
Решить вышеотмеченную проблему поможет механизм асинхронной репликации измененных данных (CDC-подход, Change Data Capture) с паттерном Outbox. Реализация представляет собой добавление нового оператора ко всем транзакциям записи, который отвечает за создание исходящего события, перехватываемое source-коннектором Kafka. Сообщение помещается в топик и используется теми потребителями, которым нужно знать, что состояние изменились. Чтобы понять, как это работает, рассмотрим подробнее шаблон транзакционный исходящий ящик (Transactional Outbox), также известный как события приложений.
Он применяется, когда команде сервиса требуется обновить базу данных и отправить сообщения или события. Например, сервис, участвующий в паттерне Sage, должен автоматически обновлять базу данных и отправлять сообщения/события. А сервис, который публикует событие предметной области, должен атомарно обновлять все данные и публиковать событие.
Чтобы избежать несоответствий данных и ошибок, сервис должен автоматически обновлять базу данных и отправлять сообщения. Однако, нецелесообразно использовать традиционную распределенную транзакцию (2PC), которая охватывает базу данных и брокер сообщений для атомарного обновления базы данных и публикации сообщений/событий. Брокер сообщений может не поддерживать 2PC. Кроме того, не рекомендуется связывать сервис с СУБД и с сообщением.
Но без использования 2PC отправка сообщения в середине транзакции ненадежна из-за отсутствия гарантии, что транзакция будет зафиксирована. Аналогично, если служба отправляет сообщение после фиксации транзакции, нет гарантии, что она не выйдет из строя до отправки сообщения.
Кроме того, сообщения должны отправляться брокеру в том порядке, в котором они были отправлены сервисом и доставляться каждому потребителю в одном и том же порядке. Это уже выходит за рамки данного шаблона. Например, агрегат обновляется серией транзакций T1, T2 и пр., которые могут выполняться одним и тем же экземпляром сервиса или разными экземплярами. Каждая транзакция публикует соответствующее событие: T1 -> E1, T2 -> E2 и т. д. Поскольку T1 предшествует T2, событие E1 должно быть опубликовано до E2.
Возникает проблема надежного атомарного обновления базы данных и отправки сообщения/события. Паттерн 2PC не поможет, т.к. если транзакция базы данных фиксируется, сообщения должны быть отправлены. И наоборот, если база данных откатывается, сообщения не должны отправляться. Сообщения должны отправляться брокеру в том порядке, в котором они были отправлены сервисом. Этот порядок должен сохраняться для нескольких экземпляров сервиса, которые обновляют один и тот же агрегат.
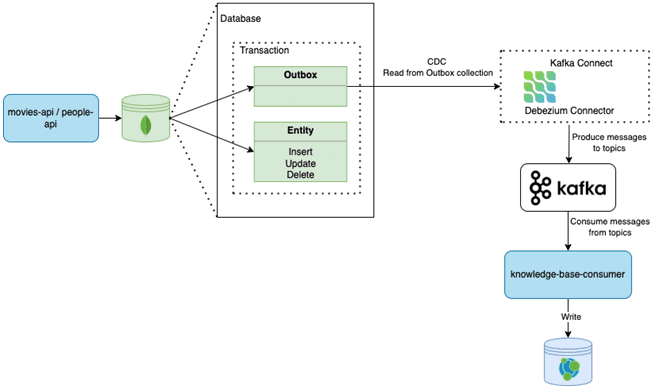
Решение сводится к следующей идее: сервис, использующий реляционную СУБД, вставляет сообщения/события в таблицу исходящих сообщений, например, MESSAGE как часть локальной транзакции. Сервис, использующий NoSQL-СУБД, добавляет сообщения/события к атрибуту обновляемой записи, например, документа или элемента. Отдельный процесс ретрансляции сообщений публикует события, вставленные в базу данных, в брокер сообщений.
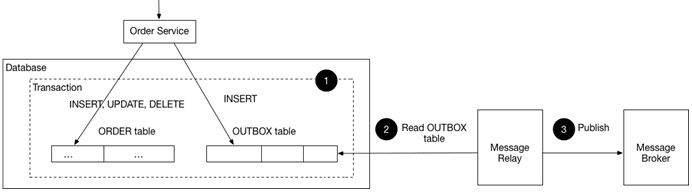
Этот шаблон имеет следующие преимущества:
- 2PC не используется;
- сообщения гарантированно отправляются тогда и только тогда, когда транзакция базы данных фиксируется;
- сообщения отправляются брокеру сообщений в том порядке, в котором они были отправлены приложением.
Однако, Outbox-паттерн потенциально подвержен ошибкам, поскольку разработчик может забыть опубликовать сообщение/событие после обновления базы данных. Кроме того, ретранслятор сообщений может публиковать сообщения более одного раза. Например, аварийно завершать работу после публикации сообщения, но до того, как это будет зафиксировано. После перезапуска ретранслятор снова опубликует сообщение. Поэтому потребитель сообщений должен быть идемпотентным, возможно, путем отслеживания идентификаторов сообщений, которые он уже обработал. Впрочем, потребители сообщений обычно идемпотентны, т.к. брокер может доставлять сообщения более одного раза. Как реализовать паттерн Idempotent Consumer, читайте в нашей новой статье.
Возвращаясь к рассматриваемому примеру, добавим брокер сообщений Kafka и новый сервис в систему. Этот сервис под названием knowledge-base будет иметь два приложения: потребитель для обработки исходящих событий и REST API для запроса сущностей и их взаимосвязей. При реализации в качестве шлюза API можно использовать KrakenD, а все сервисы написать на Kotlin с использованием фреймворка Quarkus. People-api и Movies-API имеют базу данных MongoDB, а knowledge-base – графовую СУБД Neo4j.
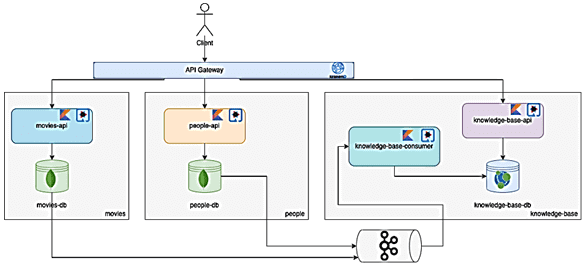
Каждый раз, когда movie-api или people-api выполняют операцию записи в своей базе данных, они также генерируют исходящее событие с соответствующим изменением, которое затем будет помещено в соответствующий топик Kafka, используемую потребителем knowledge-base. Такой подход гарантирует, что все операции записи в исходную базу данных в конечном итоге будут реплицированы в целевую базу данных. Так обеспечивается согласованность в конечном счете (eventual consistency).
Если Kafka не работает, изменения по-прежнему сохраняются в журнале транзакций исходной базы данных, а после восстановления Kafka коннектор прочитает журнал транзакций и заполнит разделы последними потерянными событиями. Если потребитель не работает, события все равно будут поступать в Kafka и как только приложение-потребитель снова заработает, он будет потреблять эти события, делая общее решение отказоустойчивым и отказоустойчивым.
Читайте в нашей новой статье, как медиакомпания Storyblocks перешла от монолитной архитектуры системы поставки контента к распределенным микросервисам с Apache Kafka в Confluent Cloud. А больше деталей про архитектуры распределенных систем, а также использование Apache Kafka и Neo4j для потоковой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники

