
Чем похожи Apache Beam и Apache Wayang, чем они отличаются, что и когда выбирать для практического использования в аналитике и обработке больших данных: сравнительная таблица по 10 критериям. Сходства и отличия Apache Wayang и Apache Beam Недавно я писала про сходство и различие Apache Wayang и Trino, где упоминала, что...
Как эффективно распределять ресурсы ClickHouse между разными пользователями и запросами, настроив политику планирования рабочих нагрузок: примеры и рекомендации. Иерархия планирования рабочей нагрузки в Clickhouse Когда ClickHouse выполняет несколько запросов одновременно, они могут использовать общие ресурсы, например, диски, ЦП и память. Чтобы эффективно распределять ресурсы ClickHouse между разными пользователями и нагрузками,...

Почему провайдерам Kafka как сервиса недостаточно многоуровневого хранилища (KIP-405) и зачем они предложили новое улучшение KIP-1150, меняющее архитектуру хранения и репликации данных напрямую в объектные системы. Кому и зачем понадобилась бездисковая Kafka: что не так с KIP-405 Одной из наиболее интересных тем вокруг Apache Kafka в апреле 2025 года стало...
Зачем в ClickHouse 25.4 добавлена отложенная материализация и как ленивые вычисления позволяют ускорить работу аналитической СУБД благодаря сокращению объемов читаемых данных и снижению количества операций дискового ввода-вывода. Еще раз о пользе ленивых вычислений Отложенные или ленивые вычисления (lazy evaluation), которые выполняются не сразу, а откладываются до момента, когда их результат...
Зачем нужен каталог метаданных и как он работает: построение платформы данных и управление метаданными по DAMA DMBOK. Unity Catalog и другие решения для учета источников данных и непрерывного обеспечения их актуальности. Управление метаданными по DMBOK Методологически создание и внедрение платформ данных основано на положениях DAMA DMBOK – своде знаний по...
Как устроена оптимизация PREWHERE для сокращения объема сканируемых данных в ClickHouse: разбираемся с деталями реализации и смотрим планы выполнения SQL-запросов. Как устроена оптимизация PREWHERE в ClickHouse Недавно мы писали, как оптимизация PREWHERE позволяет сократить объем сканируемых данных и повысить скорость выполнения SQL-запроса в ClickHouse. Сегодня рассмотрим техническую реализацию этого оператора...
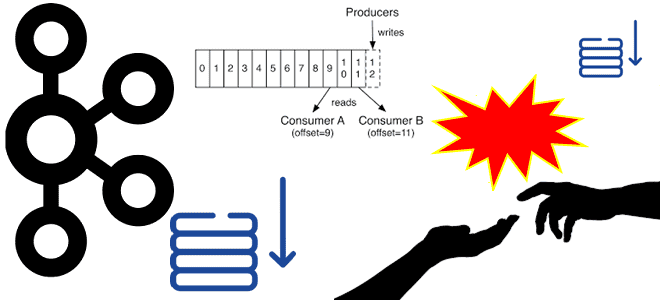
Когда и зачем фиксировать смещение потребителей Kafka вручную, с какими проблемами можно при этом столкнуться и как улучшение KIP-1094 обеспечивает целостность потоков данных в распределенных средах. Когда и зачем фиксировать смещения потребителей в Kafka вручную Недавно мы разбирали, как выполняется автоматическая фиксация смещений потребителей в Apache Kafka. Она выполняется периодически....
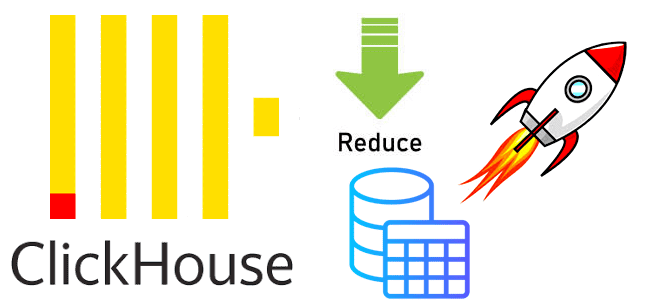
Как ускорить выполнение SQL-запроса в ClickHouse, сократив объем сканируемых данных с помощью оператора PREWHERE: практический пример простой, но эффективной оптимизации. Как работает оператор PREWHERE в ClickHouse ClickHouse имеет ряд многоуровневых оптимизаций, благодаря которым позволяет анализировать огромные объемы данных почти в реальном времени. Одной из таких оптимизаций является PREWHERE, которая сокращает...
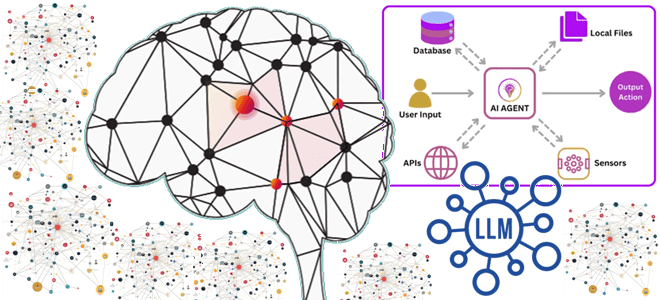
Что не так с векторным RAG: обогащение LLM данными из графовых баз с помощью MCP-протокола, вычислительных движков и коннекторов для построения ML-системы агентского ИИ. Что такое графовый RAG для LLM и ИИ-агентов Большие языковые модели (LLM, Large Language Model) и основанные на них системы агентского ИИ активно используют векторные базы...

Что общего у ClickHouse и StarRocks, чем они отличаются, и что выбирать для аналитики больших данных в реальном времени: сравнение колоночных OLAP-СУБД с векторным движком. Чем похожи ClickHouse и StarRocks: 7 главных сходств Хотя ClickHouse сегодня считается одной из наиболее популярных СУБД для аналитики больших данных в реальном времени с...