 1356
1356 
Содержание
Зачем нужен каталог метаданных и как он работает: построение платформы данных и управление метаданными по DAMA DMBOK. Unity Catalog и другие решения для учета источников данных и непрерывного обеспечения их актуальности.
Управление метаданными по DMBOK
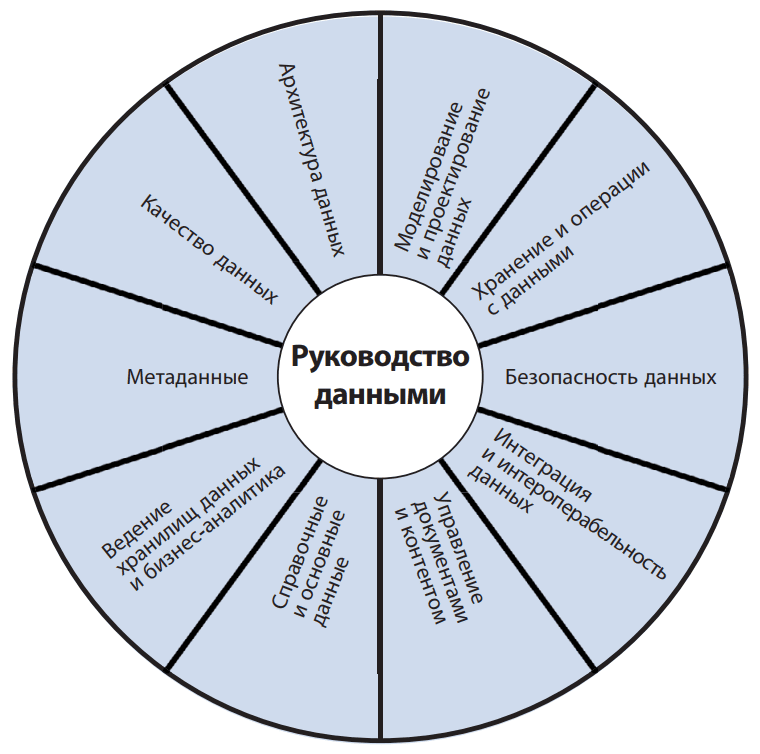
Методологически создание и внедрение платформ данных основано на положениях DAMA DMBOK – своде знаний по управлению данными, который определяет области знаний по управлению данными, а также подходы, лучшие практики и инструменты их реализации.
Одной из областей знаний в модели DAMA DMBOK является «Управление метаданными» (Metadata Management), которая подразумевает создание и ведение реестров, каталогов и словарей данных, необходимых для эффективного управления данными. Метаданные — это важная часть хранилища данных, они описывают фактические данные, включая определения полей в таблицах, описания преобразований из системы-источника в систему-приемник, информацию об обновлении и т.д. Метаданные хранятся в так называемом репозитории или каталоге метаданных (Data Catalog).
Управление метаданными означает упорядоченное хранение и систематическое обновление данными о данных, обеспечивающее их точность, единообразие форматирования и полноту, чтобы улучшить качество данных, обеспечить их целостность и конфиденциальность.
Unity Catalog и другие инструменты управления метаданными
Инструментально управление метаданными реализуется с помощью специальных решений, например, Unity Catalog, Apache Atlas, Hive Metastore, AWS Glue Data Catalog, Google Cloud Data Catalog, Microsoft Purview, Alation, Collibra Data Intelligence Cloud, Informatica Enterprise Data Catalog и пр. Также можно реализовать собственный сервис каталогизации метаданных. Пример такого прототипа я сделала на Python и рассказала об этом в блоге нашей Школы прикладного бизнес-анализа и проектирования информационных систем.
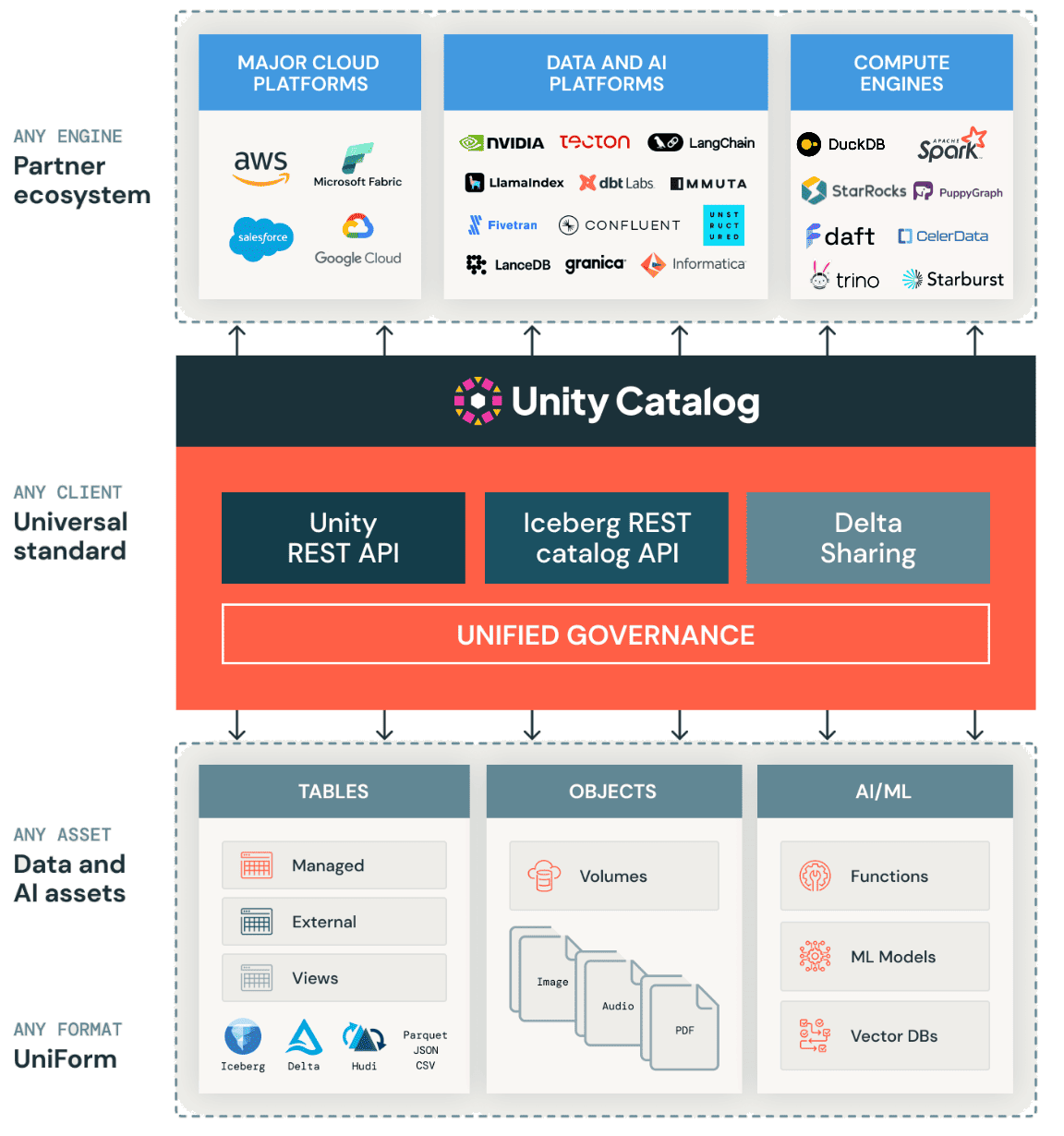
На практике из всех наиболее известных инструментов каталогизации метаданных Unity Catalog становится все более популярным благодаря следующим факторам:
- открытый исходный код;
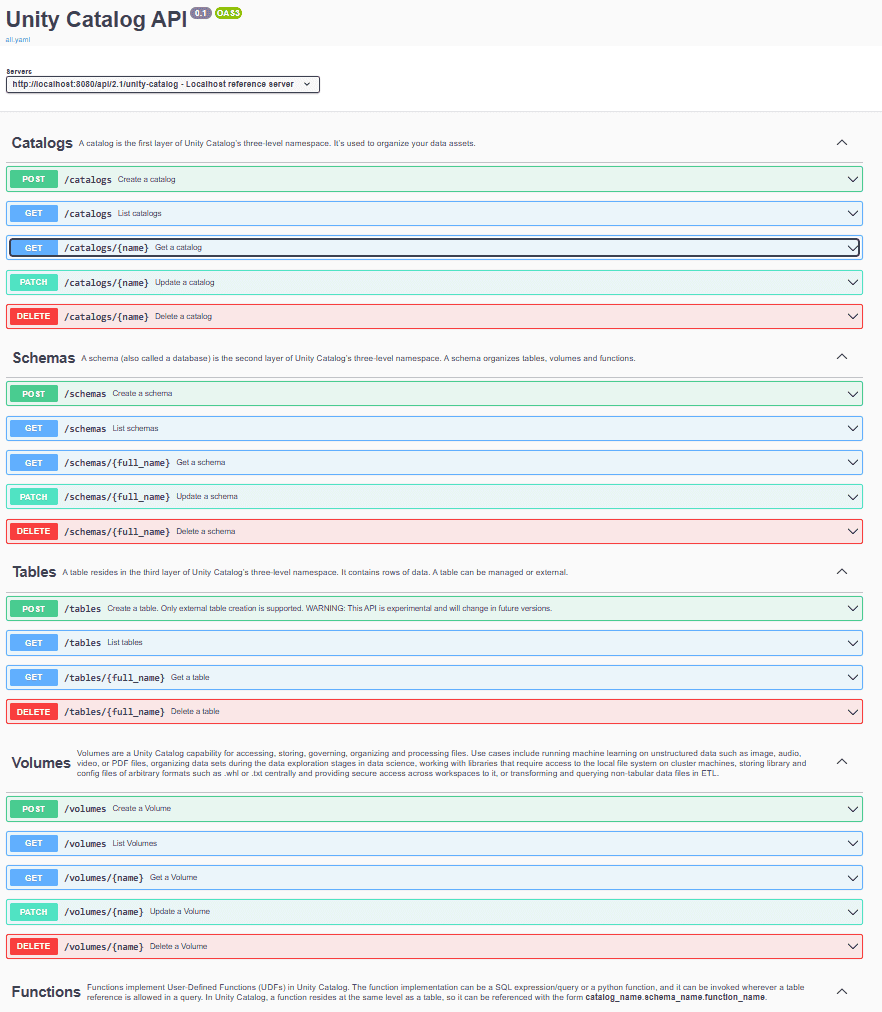
- наглядная спецификация OpenAPI;
- интеграция со множеством технологий, включая поддержку различных форматов данных (Delta Lake, Apache Iceberg и Hudi через UniForm, Parquet, JSON, CSV и пр.), а также вычислительных движков и хранилищ данных;
- мультимодальная поддержка данных для ИИ, включая таблицы, файлы, инструменты и функции, фичи и сами ML-модели.
Исторически Unity Catalog был разработан корпорацией Databricks для централизованного управления метаданными и активами на платформе данных. Решение позволяет централизованно каталогизировать, управлять и контролировать доступ к данным, обеспечивая прозрачность, безопасность и соответствие корпоративным требованиям.
Unity Catalog напрямую реализует концепцию управления метаданными из DAMA DMBOK, обеспечивая:
- централизованную регистрацию и каталогизацию метаданных, соответствующую требованиям из области знаний Metadata Management;
- поддержку управления данными и метаданными как корпоративными активами, как того требует DAMA DMBOK;
- прозрачность и доступность информации о данных для всех заинтересованных лиц, в том числе аналитиков, разработчиков, бизнес-пользователей и руководителей организации;
- техническую поддержку документа «Каталог данных» — одного из ключевых артефактов DAMA DMBOK, который описывает активы данных организации, их происхождение, владельцев, назначение, правила доступа и другую важную информацию.
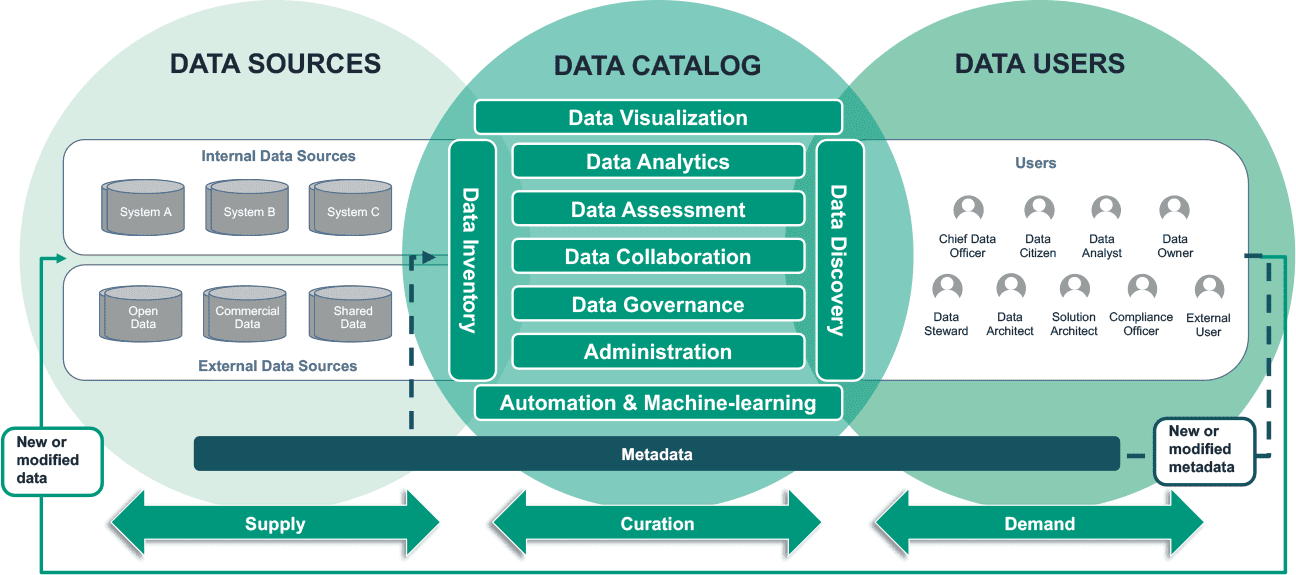
Работа с данными в инструментальном каталоге метаданных
Работа с данными и метаданными в каталоге метаданных устроена следующим образом:
- Регистрация источников данных и каталогов. Прежде всего, администраторы платформы данных или владельцы данных регистрируют существующие источники (файловые и объектные хранилища, базы данных, API) в каталоге метаданных. Например, в Unity Catalog это делается через GUI, REST- или CLI-интерфейсы.
- Настройка безопасного доступа. После регистрации источников и каталогов данных надо настроить политики безопасности и управления доступом к данным. Эти правила доступа становятся частью метаданных в каталоге.
- Автоматическое извлечение и синхронизация метаданных. После регистрации источника данных каталог автоматически извлекает и регистрирует метаданные о таблицах, схемах и форматах данных, а также расположении файлов. Метаданные включают в себя сведения о структуре и типах данных, таблицах и их столбцах, схемах, партициях и местоположении файлов. На этом этапе современные каталоги метаданных включают ИИ-инструменты, например, большие языковые модели (LLM, Large Language Model) или ИИ-агенты для генерации описания данных по заданному шаблону. Например, LLM анализирует структуру метаданных зарегистрированного источника или набора данных, создавая контекстно-зависимые названия и глоссарий для каждого поля. Также благодаря векторному или графовому RAG происходит обогащение контекста, что мы недавно разбирали здесь.
- Ручная регистрация метаданных. Метаданные можно также создавать вручную. Например, в Unity Catalog это возможно с помощью SQL-команд CREATE TABLE и CREATE SCHEMA. Это полезно, когда надо явно определить структуру данных для новых наборов данных или внешних таблиц, которые нельзя автоматически просканировать и зарегистрировать.
- Интеграция с ETL-инструментами и другими средствами дата-инженерии (Airflow, Databricks Jobs, Delta Live Tables и пр.). Когда эти инструменты создают или обновляют таблицы, каталог данных автоматически регистрирует изменения в метаданных, отражая обновлённую структуру и содержимое данных. При изменении данных или схемы таблиц (добавлении новых столбцов, изменении типов данных, добавлении или удалении партиций) каталог данных автоматически фиксирует эти изменения и обновляет метаданные, чтобы они всегда были актуальными. На низком уровне такая интеграция реализуется через триггеры на таблицах, коннекторы и другие возможности репликации изменений согласно CDC-подходу (Change Data Capture).
Таким образом, каталог метаданных служит единой точкой централизованного управления и хранения метаданных, обеспечивая их автоматическое извлечение, регистрацию и актуализацию и контролируемый доступ к данным во всей корпоративной платформе данных.
В заключение еще раз отмечу удобство работы с Unity Catalog, который можно развернуть как отдельный сервер и интегрировать в свою платформу данных, настроив периодическую и событийную интеграцию с источниками данных посредством HTTP-вызовов. Это достигается благодаря REST API и подробной документации на него в виде спецификации OpenAPI.
Узнайте, как построить согласованную и эффективную архитектуру данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://www.dama.org/cpages/body-of-knowledge
- https://github.com/unitycatalog/unitycatalog
- https://www.starrocks.io/blog/build-a-more-open-lakehouse-with-unity-catalog
- https://docs.unitycatalog.io/swagger-docs/
- https://www.getrightdata.com/blog/unleashing-data-potential-a-journey-through-large-language-models-and-gen-ai-in-data-management
- https://www.cdq.com/events-insights/research/data-catalog

