 1012
1012 
Содержание
Почему провайдерам Kafka как сервиса недостаточно многоуровневого хранилища (KIP-405) и зачем они предложили новое улучшение KIP-1150, меняющее архитектуру хранения и репликации данных напрямую в объектные системы.
Кому и зачем понадобилась бездисковая Kafka: что не так с KIP-405
Одной из наиболее интересных тем вокруг Apache Kafka в апреле 2025 года стало улучшение KIP-1150 – так называемый Diskless Topics. Это изменение направлено на сокращение стоимости владения потоковой платформой благодаря репликации данных в объектные хранилища вместо жестких дисков на брокерах. Сегодня KIP-1150 еще находится в стадии обсуждения и пока не реализован ни в одном выпуске. Однако, эта идея в корне меняет ключевые преимущества Apache Kafka: надежность и скорость.
Изначально Kafka была разработана для относительно долговременного хранения данных на жестких дисках с согласованной репликацией на нескольких узлах кластера. Пакет отправленных продюсером сообщений Kafka записывает в память или страничный кэш операционной системы, используя репликацию с брокера-лидера на брокеров-подписчиков для обеспечения долговечности вместо сброса данных на диск через fsync. Каждый брокер Kafka управляет собственным локальным хранилищем, создавая сильную связь между вычислениями и хранением данных. Масштабирование кластера, т.е. добавление брокеров или перебалансировка разделов считаются довольно ресурсоемкими операциями, которые могут снизить доступность и производительность потоковой системы.
Кроме того, в связи с повсеместным использованием масштабируемых гибких сред и облачных объектных хранилищ инфраструктурные решения Kafka кажутся несколько старомодными. Поэтому еще 2 года назад, в 2023 году, в Kafka было реализовано многоуровневое хранилище: KIP-405, о котором мы писали здесь. Эта функция расширяет возможности Kafka, позволяя публиковать больше данных и хранить неактивные сегменты в облачном объектном хранилище.
Однако, многоуровневое хранение не устраняет необходимость репликации активных сегментов, что является наиболее значимой статьей расходов на инфраструктуру Kafka. Напомним, именно дисковое пространство и сетевая передача данных считаются основным источником затрат в Kafka. Поэтому для снижения стоимости эксплуатации следует сделать хранение и репликацию данных более дешевыми. Само по себе многоуровневое хранение увеличивает сложность потоковой системы, добавляя новые потенциальные точки отказа.
Кроме того, хотя многоуровневое хранилище может сократить некоторые расходы на хранение за счет выгрузки холодных данных неактивных сегментов в объектное хранилище, пользователям по-прежнему необходимо выделять значительное локальное дисковое пространство для горячих данных и обработки пиковых нагрузок. Это означает, что высокие затраты на облачные диски сохраняются, а плата за сетевой трафик (особенно в зонах доступности) остается основной статьей расходов.
Получается, что архитектура Kafka, даже с многоуровневым хранилищем, остается тесно связанной между брокерами и локальными дисками. Это делает быстрое масштабирование сложным и рискованным, поскольку переназначение разделов все еще медленное и ресурсоемкое. Отсутствие эластичности приводит к избыточному выделению ресурсов и напрасным затратам. Наконец, многоуровневое хранилище не поддерживает сжатые топики, и после включения его нельзя отключить. Миграция сервисов с включенным многоуровневым хранилищем между регионами или облаками ограничена.
Поэтому в 2025 году компания Aiven, которая является провайдером Kafka как сервиса, а также предоставляет еще множество других систем, предложила KIP-1150, чтобы записывать данные непосредственно в недорогое объектное хранилище вместо репликации от брокера к брокеру и асинхронной записи на локальные диски.
Архитектура KIP-1150, риски и возможности Diskless Topics
Термин «без диска» означает, что диск брокера не будет использоваться для хранения пользовательских данных. Однако, Diskless Topics все равно потребляют дисковое пространство брокера для хранения метаданных KRaft и пакета сообщений. Кроме того, брокеру может потребоваться дисковое пространство для выполнения определенных операций, таких как сжатие объектов и кэширование в пути чтения вместо потребления памяти.
Интересно что объектное хранилище объектов – не просто место хранения данных, а эластичное средство балансировки нагрузки и надежно реплицируемая система, объединенная в единый API. Поэтому KIP-1150 предлагает использовать объектное хранилище в качестве основного механизма репликации Kafka, исключая самую дорогую часть накладных расходов на повторяющуюся репликацию блоков между зонами доступности. Тестирование этой гипотезы, проведенной разработчиками Aiven, показало, как размер пакета влияет на соотношение стоимости и задержки. Небольшие сообщения около 100 КБ обрабатываются быстро, но требуют тысячи операций PUT для сохранения объектов, большие пакеты порядка 10 МБ сокращают затраты на вызовы к хранилищу, но замедляют чтение отдельных сообщений. Впрочем, для большинства рабочих нагрузок достаточно пакета размером 1 МБ, что и рекомендуется для Kafka, который будет обрабатываться около 200–400 мс, сокращая расходы на облако примерно на 80% по сравнению с классической репликацией.
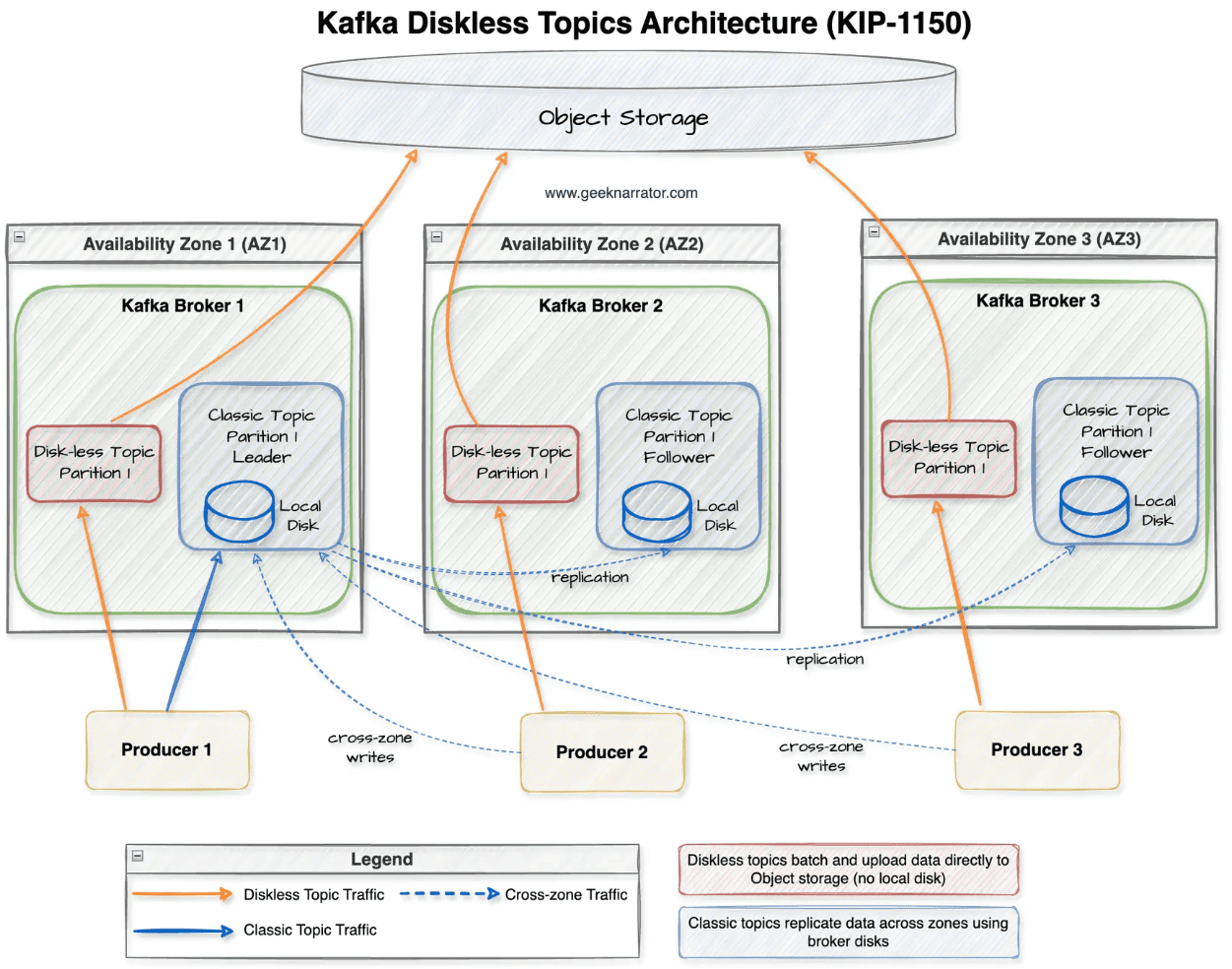
Важно отметить, что бездисковые топике предлагается реализовать как дополнительную опцию, а не замену классических топиков Kafka. Чтобы сохранить полную обратную совместимость, для за включение новой возможности будет отвечать конфигурация топика, например, topic.type=diskless. Протокол Kafka не изменится, поэтому не придется менять код клиентов, т.е. продюсеров и потребителей. Благодаря этому попробовать новинку можно будет на некритичных для бизнеса приложениях, например, мониторинг логов.
Хотя технический дизайн KIP-1150 еще в стадии обсуждения, разработчики Aiven уже предложили некоторые идеи по реализации. В частности, ожидается, что классические и бездисковые топики Kafka будут отличаться способом группировки пакетов. В классических топиках Kafka каждый сегмент привязан к одному разделу, а в бездисковых сегменты являются общими, объединяя пакеты из нескольких disckless-топиков и разделов. Это позволит уменьшить количество отдельных файлов и загрузок объектов, чтобы снизить число вызовов с облачному объектному хранилищу и сократить расходы. Внутри каждого сегмента общего журнала пакеты по-прежнему сохранят локальный порядок на основе физического размещения, но без внутреннего порядка между сегментами, пока смещения и временные метки не будут официально назначены.
Поскольку в объектных хранилищах по умолчанию включено версионирование, сегменты лога после загрузки становятся неизменяемыми, подобно неактивным сегментам в многоуровневом хранилище KIP-405. Это поведение соответствует типичному объектному хранилищу, где нельзя выполнять случайные записи. Каждый сегмент получает глобально уникальный UUID для удобства ссылки. Такой подход оптимизирует публикацию, но имеет следующие недостатки:
- множество мелких объектов затрудняет последовательное чтение, увеличивает потребность в параллельных операциях, затраты на GET-запросы к объектному хранилищу и задержки;
- накладные расходы на метаданные для хранения множества небольших пакетов.
Для устранения этих недостатков KIP-1150 предлагает ввести в брокеры агенты сжатия, которые будут изменять порядок пакетов по смещению, группировать их по разделу топика и обеспечивать потоковую передачу в объектное хранилище. После реорганизации данных агент сжатия будет уведомлять координатора пакетов об обновленной структуре данных, обеспечивая их локальность, а также сокращая количество выборок объектов и затрат при потреблении.
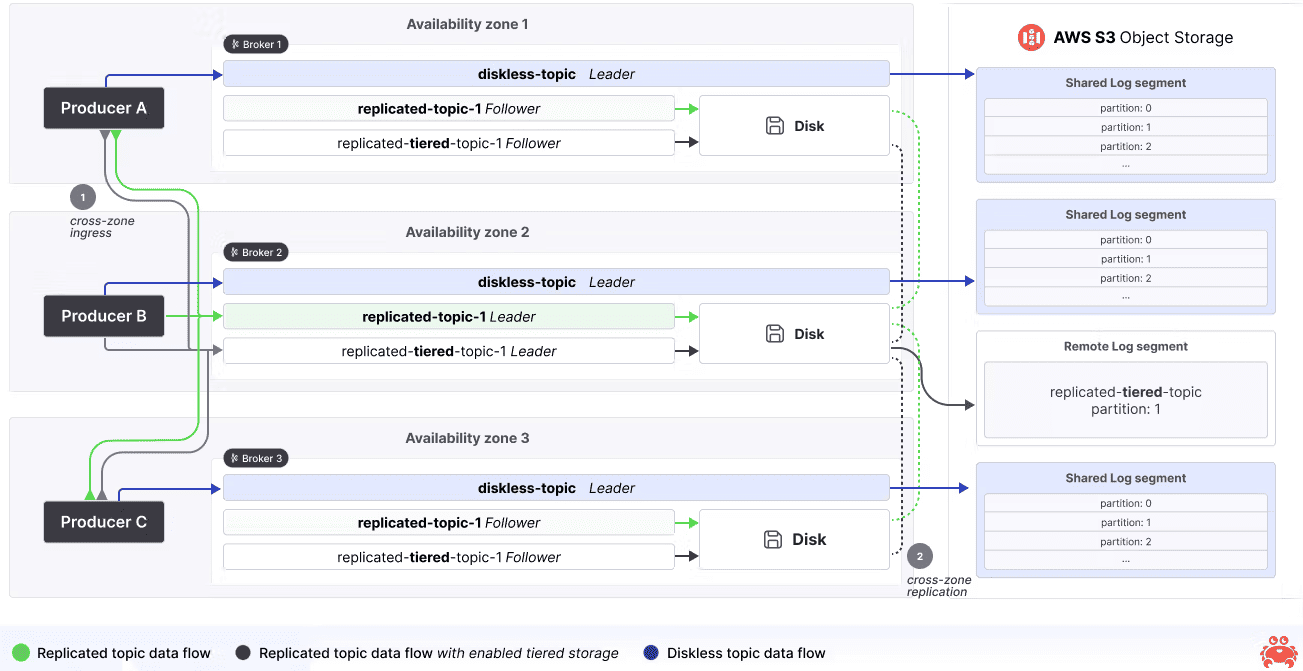
Таким образом, KIP-1150 меняет подход к работе Kafka, обеспечивая репликацию без брокеров-лидеров и подписчиков: любой узел кластера сможет писать данные в любой раздел, кэшируя сообщения на короткое время, чтобы потом сгруппировать в пакеты и сохранить в объектное хранилище. Это обеспечит автоматическое масштабирование и настоящую эластичность, исключая ограничения локального диска и операций ввода-вывода.
Однако, такая облачная потоковая архитектура с дешевым хранением множества данных и их быстрой обработкой подходит не для всех вариантов использования. Усложнение архитектуры с добавлением нового звена обязательно влечет к росту задержек. Поэтому бездисковые топики можно использовать там, где допустима задержка между публикацией и потреблением данных до 1 секунды, например, мониторинг логов, телеметрия, аналитика событий пользовательского поведения. Для сценариев, требующих обработки данных в реальном времени, например, реклама и рекомендательные системы, disckless-топики не подойдут.
Кроме того, стремление уйти от ограничений локальных дисков добавляет зависимость от облачного хранилища и провайдера, предоставляющего этот сервис. Это подходит не для всех компаний. Иногда для максимального контроля и соблюдений строгих требований к безопасности важно использовать собственные решения, а не стороннюю инфраструктуру.
В заключение хочется еще раз отметить, что до практической реализации KIP-1150 еще далеко, как минимум около 3-х лет по предварительным оценкам самих разработчиков. Тем не менее, это довольно интересная фича, которая точно найдет своих пользователей, при ее грамотной и эффективной реализации.
Научитесь администрированию и эксплуатации Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

