 1868
1868 
Что не так с векторным RAG: обогащение LLM данными из графовых баз с помощью MCP-протокола, вычислительных движков и коннекторов для построения ML-системы агентского ИИ.
Что такое графовый RAG для LLM и ИИ-агентов
Большие языковые модели (LLM, Large Language Model) и основанные на них системы агентского ИИ активно используют векторные базы данных, которые специально оптимизированы для хранения векторных встраиваний и запросов к ним. В частности, большинство RAG-инструментов (Retrieval Augmented Generation), использующих поиск информации на основе запроса пользователя и предоставления результатов в качестве справочного материала для генерации ответа ИИ, применяют векторное сходство в качестве основного метода поиска. Векторные встраивания (embeddings) – это математическое представление текстов, слов, фраз или документов в виде многомерных числовых векторов. Они получаются путем обработки исходного текста через нейросеть. Семантически похожие тексты имеют близкие векторные представления, т.е. их векторная близость, например, косинусное сходство или евклидово расстояние, отражает реальное смысловое сходство текстов, даже если они выражены разными словами. Подробно об этом мы писали здесь.
Однако, базовые методы RAG, основанные на векторном сходстве, и, соответственно, векторных или колоночных хранилищах данных, рассматривают точки данных как изолированные сущности, помещая их в табличные структуры. При этом теряются тонкие контекстные связи, когда нужно обеспечить целостное понимание обобщенных семантических концепций в больших массивах данных или даже в отдельных больших документах. Это снижает обучаемость и точность LLM. Поэтому еще год назад в Microsoft Research возникла идея GraphRAG, когда LLM для создания графа знаний на основе закрытого набора данных. Затем этот граф используется вместе с графовым машинным обучением для генерации ответов на промпты. Благодаря особым принципам хранения данных, графовые базы оптимизированы для нахождения связей, что позволяет ИИ понимать связи между, казалось бы, разрозненными элементами. Поэтому такой подход может пригодится и при построении платформы данных для управления метаданными, что мы разбираем здесь.
Рассмотрим в качестве примера систему обнаружения мошенничества по банковским счетам и картам. Вместо того чтобы рассматривать каждую транзакцию как изолированную точку данных, ИИ на основе графа может просматривать всю сеть транзакций, учитывая их частоту, отношения между владельцами счетов, местоположения и любые выбросы, которые указывают на что-то подозрительное. Именно это сетевое понимание позволяет принимать решения в режиме реального времени, останавливая мошенничество по мере его возникновения, а не анализируя его после того, как ущерб нанесен.
Подход GraphRAG состоит из следующих шагов:
- LLM обрабатывает весь закрытый набор данных, создавая ссылки на все сущности и связи в исходных данных, которые затем используются для создания графа знаний, сгенерированного самой LLM;
- сгенерированный граф знаний используется для кластеризации снизу вверх, которая иерархически организует данные в семантические кластеры. Такое разбиение позволяет предварительно резюмировать семантические концепции и темы, что способствует целостному пониманию набора данных.
- Во время запроса обе структуры используются для предоставления материалов для контекстного окна LLM при ответе на вопрос. При этом выполняются разные режимы поиска: глобальный для обоснования целостных вопросов о корпусе текста с использованием полученных резюме, локальный для рассуждений о конкретных сущностях путем распространения на их соседей и связанные с ними концепции, а также плавающий поиск с добавлением контекстной информации сообщества.
Таким образом, графовые хранилища позволяют системам ИИ динамически исследовать и связывать различные фрагменты данных, увеличивая глубину и точность предоставляемых ответов.
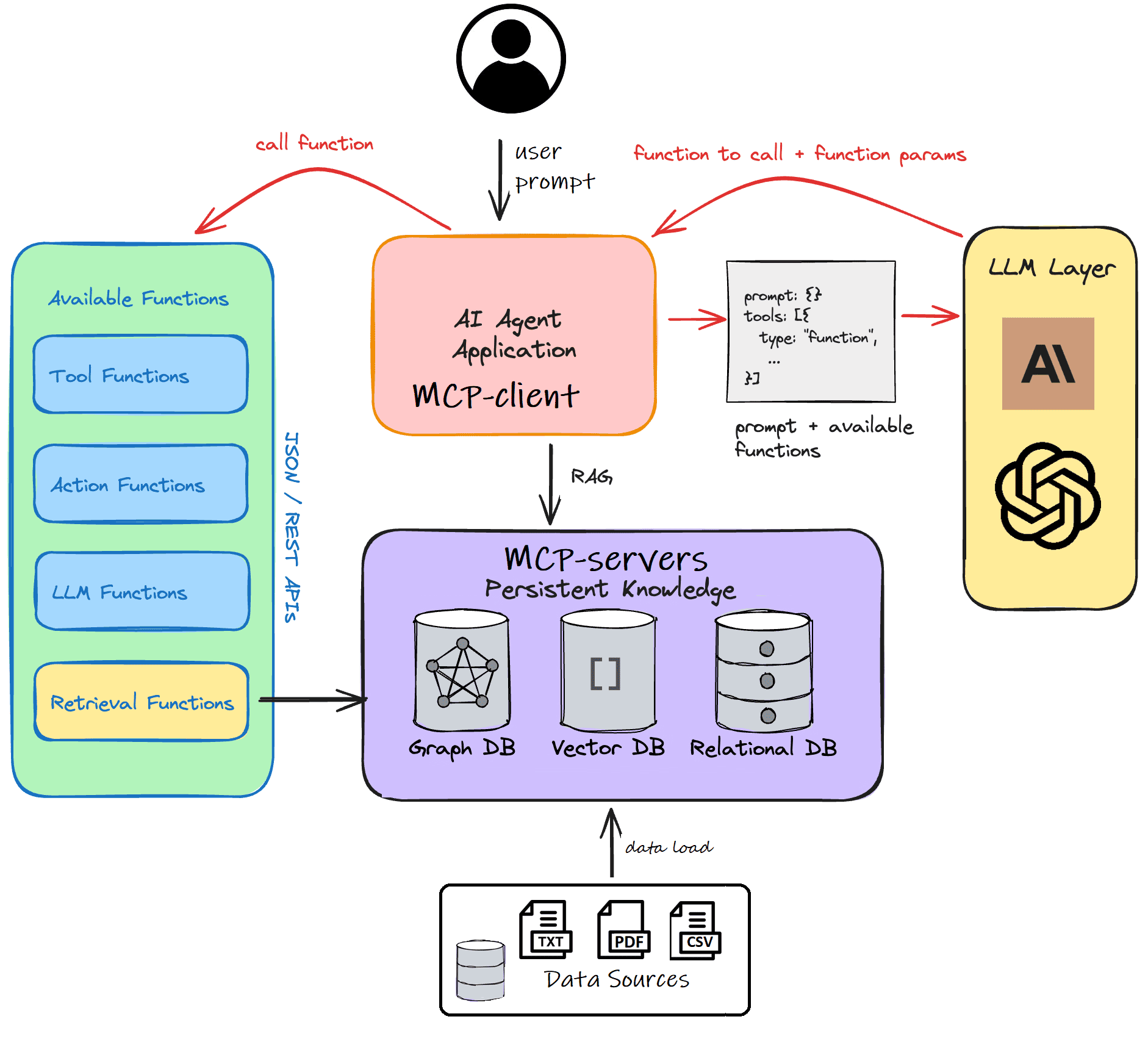
Чтобы использовать графовые базы данных в LLM и системах агентского ИИ, их необходимо интегрировать между собой. Для этого можно использовать текстовый MCP-протокол (Model Context Protocol), взяв готовый или реализовав собственный MCP-сервер. Это позволит ML-моделям запрашивать графы, обогащая свой контекст для генерации более точных ответов. А благодаря тому, что большинство графовых БД имеет специальные графовые операторы, например, для поиска путей или выявления сообществ, процесс обогащения новыми знаниями выполняется быстрее. Поэтому многие разработчики графовых БД активно выпускают MCP-серверы для своих систем. В частности, в марте 2025 года опубликован исходный код MCP-сервера для NebulaGraph 3.x. А MCP-серверы для Neo4j вышли еще в декабре 2024 года.
Однако, построение системы агентского ИИ с GraphRAG не ограничивается только взаимодействием LLM с графовой БД по MCP-протоколу. Необходимо также обеспечить наполнение графового хранилища данными. Поскольку объемы таких данных обычно очень большие и могут обновляться в реальном времени, для заливки используются соответствующие инструменты. Например, для NebulaGraph это могут быть коннекторы Flink или Spark, которые позволяют записывать крупные датафреймы в графы знаний построчно или пакетным импортом, добавляя новые или обновляя существующие данные.
Узнайте больше про машинное обучение и ИИ на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://microsoft.github.io/graphrag/
- https://www.nebula-graph.io/posts/nebulagraph_essential_for_the_next_generation_of_ai_and_llms
- https://vectorize.io/how-i-finally-got-agentic-rag-to-work-right/
- https://www.nebula-graph.io/posts/Announcing_the_Open_Source_Release_of_NebulaGraph_MCP_Server
- https://neo4j.com/blog/genai/graphrag-manifesto/

