Что общего у ClickHouse и StarRocks, чем они отличаются, и что выбирать для аналитики больших данных в реальном времени: сравнение колоночных OLAP-СУБД с векторным движком.
Чем похожи ClickHouse и StarRocks: 7 главных сходств
Хотя ClickHouse сегодня считается одной из наиболее популярных СУБД для аналитики больших данных в реальном времени с помощью SQL-запросов. Однако, это далеко не единственное решение в своем классе. Альтернативой может стать колоночная аналитическая СУБД StarRocks, о которой мы недавно рассказывали здесь. Обе системы написаны на С++, что дополнительно повышает их производительность. Также как и ClickHouse, StarRocks имеет массово-параллельную архитектуру (MPP, Massive Parallel Processing), колоночные механизм хранения и векторизованный движок обработки данных.
Благодаря MPP-подходу ClickHouse и StarRocks эффективно утилизируют вычислительные ресурсы каждого узла кластера, разделяя запрос на множество логических и физических исполнительных блоков, которые выполняются одновременно на нескольких машинах. Векторизованные инструкции SIMD обеспечивают операции с блоками данных (обычно 65 505 строк по умолчанию) вместо построчной обработки. Каждый столбец в блоке хранится как вектор примитивных типов данных, позволяя использовать инструкции SIMD (Single Instruction, Multiple Data), которые работают с несколькими элементами данных одновременно в одном регистре. SIMD-процессоры обеспечивают параллелизм на уровне данных, реализуя множественный поток данных на одиночный поток команд. Это позволяет ЦП выполнять одну и ту же операцию одновременно на множестве элементов, например, вместо последовательного сложения каждого элемента при вычислении агрегатных функций, можно работать с несколькими числами одновременно. В частности, 256-битный SIMD регистр ЦП позволяет сложить восемь 32-битных целых чисел за одну операцию. Это очень ускоряет выполнение запросов, особенно если данные хранятся в векторизированной форме. Также SIMD-инструкции обеспечивают более быстрое сжатие и декомпрессию данных, чтобы хранить больше данных в памяти и быстрее извлекать их. Подробнее о том, как это применяется в ClickHouse, мы писали здесь.
ClickHouse и StarRocks используют стоимостной оптимизатор запросов (CBO, Cost-Based Optimizer), который адаптивно вычисляет стоимость выполнения разных планов запросов на основе статистики таблиц. Для выполнения запросов обе системы используют фреймворк конвейерного исполнения, который автоматически настраивает параллелизм выполнения запросов для повышения эффективности использования многоядерных ресурсов на одной машине.
Таким образом, ClickHouse и StarRocks имеют следующие общие характеристики:
- категория – колоночные СУБД;
- назначение — аналитика данных в реальном времени;
- поддержка SQL и материализованных представлений;
- MPP-архитектура;
- колоночный механизм хранения данных;
- векторизованный механизм обработки данных;
- CBO-оптимизатор выполнения запросов.
Несмотря на эти сходства, ClickHouse и StarRocks имеют ряд отличий, которые обусловливают их специфические варианты использования. Об этом мы поговорим далее.
Отличия ClickHouse и StarRocks
Хотя ClickHouse поддерживает соединения таблиц, это не рекомендуется, поскольку одна из таблиц загружается в память, которая всегда ограниченного размера. Поэтому перед загрузкой данных в ClickHouse их желательно сперва денормализовать, чтобы избежать многотабличных запросов. StarRocks же довольно эффективно справляется с JOIN-операциями, позволяя работать с классическими звездными схемами типа «звезда» или «снежинка» для размерных данных.
StarRocks поддерживает три различных типа соединений:
- широковещательное (Broadcast join) для связывания большой таблицы с небольшой, которая загружается в память узла посредством широковещательной передачи.
- Случайное (shuffle join), когда связываются две плоские таблицы, и данные с одинаковыми значениями в двух таблицах будут перемешаны на одну и ту же машину;
- соединение с размещением (colocation join), когда хранятся в той же группе размещения, чтобы избежать накладных расходов на сетевую передачу и ввод-вывод, вызванных перемешиванием.
Еще одним отличием является транзакционность выполнения операций. Изначально ClickHouse не поддерживает транзакции в строгом понимании этого термина, о чем мы писали здесь. В ClickHouse нет полноценных транзакций, т.к. эта СУБД ориентирована на аналитические запросы, т.е. чтение большого объема данных и приблизительные вычисления в реальном времени. Это скорее соответствует BASE-подходу (Basically Available, Soft State, Eventually consistent) к реализации транзакционности, чем ACID (Atomicity, Consistency, Isolation, Durability). В частности, процесс дедупликации данных выполняется в таблицах ClickHouse во время фонового слияния блоков данных, которое запускается автоматически в случайные моменты времени, независимо от дата-инженера. Как сделать это более управляемым, мы рассматривали здесь и здесь.
С блочным принципом хранения данных связано другое ограничение ClickHouse – ориентация на пакетные вставки большими порциями данных вместо точечных обновлений. StarRocks вполне успешно справляется с такими сценариями. ClickHouse использует блочно-колоночную структуру хранения с неизменяемыми (immutable) блоками данных, а обновление реализуется через асинхронное слияние и перезапись больших сегментов данных. Поэтому точечные обновления в ClickHouse дороги и неэффективны – они приводят к переписыванию больших объёмов данных. В StarRocks есть различные типы таблиц (Primary Key, Duplicate Key, Aggregate и Unique Key), которые отличаются ограничениями уникальности ключевых столбцов. В частности, таблица типа Primary Key отлично реализует обновления данных в реальном времени, сохраняя высокую производительность для сложных ad-hoc запросов. Данные при вставках и точечных обновлениях не переписываются полностью крупными блоками, а временно записываются в память, после чего постепенно и асинхронно сливаются на диск. Это позволяет выполнять точечные обновления эффективно, сокращая объем перезаписи данных. Чтобы быстро находить и обновлять конкретные строки для точечных обновлений, StarRocks использует первичные ключи и эффективные индексы. В ClickHouse же индексация менее эффективна для случайных одиночных изменений, так как структура данных не оптимизирована под этот сценарий.
Поэтому ClickHouse не очень хорошо подходит для высококонкурентных запросов, которые выполняются одновременно большим количеством клиентов, требуя быстрого отклика и высокой пропускной способности. ClickHouse изначально был оптимизирован под высокую скорость выполнения отдельных тяжелых запросов на больших объёмах данных. При выполнении большого количества одновременных запросов ЦП, память и ресурсы ввода-вывода могут исчерпываться, что приводит к росту задержки и снижению производительности.
StarRocks же, наоборот, изначально разрабатывался для высококонкурентных аналитических запросов и интерактивных обновлений. На уровне хранения данных StarRocks сначала использует стратегию партиционирования, а затем бакетирования, чтобы сделать данные более видимыми. Префиксный индекс ускоряет фильтрацию и поиск данных, а также сокращает операции дискового ввода-вывода, повышая производительность запросов. Напомним, партиционирование (partitioning) — это разделение больших таблиц на более мелкие логические части (партиции) на основе определнного поля. Партиционирование упрощает поиск данных и значительно сокращает объем сканирования при выполнении запросов. Благодаря партиционированию StarRocks может быстро пропускать ненужные части данных во время выполнения запроса, тем самым повышая эффективность работы запросов и снижая нагрузку на дисковую подсистему.
Бакетирование (bucketing) применяется после того, как таблица разделена на разделы. Каждый раздел (партиция) дополнительно делится на более мелкие сегменты (бакеты) на основе хэш-функций по одному или нескольким полям. Бакетирование помогает обеспечить еще более мелкую детализацию структуры данных и улучшить производительность запроса за счет быстрого поиска и параллельной обработки. Таким образом, StarRocks сначала использует партиционирование, чтобы грубо структурировать и минимизировать просмотр несвязанных данных, а затем применяет бакетирование для более точного распределения и эффективного параллельного доступа к данным.
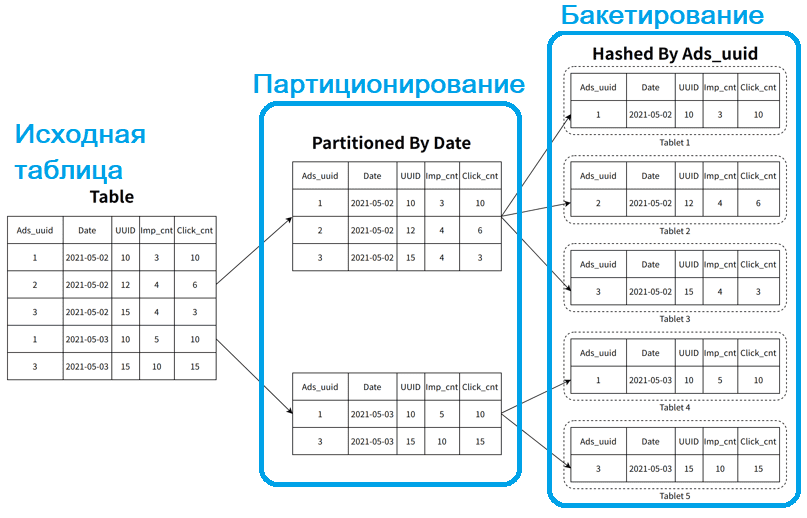
Бакетирование лежит в основе механизма репликации и эластичного масштабирования в StarRocks. После бакетирования данные с одинаковым хэшем сегмента делятся на тот же срез — планшет (tablet). Планшет — это наименьшая единица избыточности данных в StarRocks. Обычно по умолчанию хранится три копии данных, а узлы реплицируются через протокол кворума. Когда узел выходит из строя, недостающие планшеты автоматически заполняются на других доступных узлах для достижения незаметного аварийного переключения. При добавлении нового узла в кластер StarRocks распределение планшетов на него планируется и выполняется автоматически для равномерной балансировки нагрузки. Это обеспечивает эластичное масштабирование кластера.
В ClickHouse шардирование не выполняется автоматически, а требует работы с табличным движком Distributed, который не обеспечивает хранение данных, а маршрутизирует запросы на шардированные таблицы с последующей обработкой результатов. В отличие от StarRocks, в ClickHouse кластер является неэластичным: необходимо прописать его шарды и количество реплик в конфигурационный файл каждого сервера. Пример такой конфигурации смотрите в этой статье.
Таким образом, ClickHouse отлично подходит для сценариев с предсказуемой OLAP-нагрузкой по большим объемам данных, где важна высокая скорость вычисления агрегатов по широким плоским таблицам без соединений и точечных обновлений данных.
StarRocks будет хорошим выбором для сложных многотабличных запросов в ad-hoc аналитике реального времени и/или частых точечных обновлениях данных. Также StarRocks можно использовать как вычислительный SQL-движок к данным, хранящимся в озерах (HDFS и облачные объектные хранилища) без фактического импорта информации в саму БД. Это похоже на вариант использования Trino, о котором мы говорили вчера.
Освойте ClickHouse на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://celerdata.com/blog/clickhouse-vs.-starrocks-a-detailed-comparison
- https://www.starrocks.io/blog/starrocks-vs-clickhouse-the-quest-for-analytical-database-performance
- https://risingwave.com/blog/starrocks-vs-clickhouse-the-ultimate-database-showdown/
- https://www.starrocks.io/blog/benchmark-test