 839
839 
Как устроена оптимизация PREWHERE для сокращения объема сканируемых данных в ClickHouse: разбираемся с деталями реализации и смотрим планы выполнения SQL-запросов.
Как устроена оптимизация PREWHERE в ClickHouse
Недавно мы писали, как оптимизация PREWHERE позволяет сократить объем сканируемых данных и повысить скорость выполнения SQL-запроса в ClickHouse. Сегодня рассмотрим техническую реализацию этого оператора и сравним планы выполнения SQL-запросов с ним и без него. В SQL-запросе с WHERE-условием ClickHouse сначала читает все столбцы таблицы, а затем применяет фильтр по условию. При использовании оператора PREWHERE сперва будут прочтены только те столбцы, которые упомянуты в этом условии, отфильтрованы и только после этого ClickHouse прочитает строки из остальных столбцов. Причем этих строк будет значительно меньше. Поэтому образом, оптимизация PREWHERE особенно эффективна для широких таблиц со множеством столбцов, когда условие фильтрации отсекает большую часть данных или использует столбцы с низкой кардинальностью, где данные в которых повторяются часто.
Оптимизация PREWHERE в ClickHouse реализована на нескольких уровнях архитектуры системы, начиная от парсинга SQL-запроса и заканчивая низкоуровневыми механизмами работы с данными. Сперва на уровне синтаксического анализа и планирования запросов ClickHouse создает исполняемый план, где выражения PREWHERE обрабатываются отдельно от WHERE. Система анализирует синтаксическое дерево запроса и преобразует его в план выполнения, где PREWHERE выделяется в отдельный этап. Даже если PREWHERE не указан в запросе явно, оптимизатор ClickHouse анализирует условия WHERE и автоматически переносит подходящие условия в PREWHERE, которые отсекают много строк, используют столбцы с малым потреблением памяти и с индексами. Это выполняется на этапе оптимизации запроса в классе PrewhereExpressionOptimizer.
Далее, на уровне табличного движка семейства MergeTree класс MergeTreeBaseSelectBlockInputStream и его наследники отвечают за формирование логики чтения данных с учетом PREWHERE.
PREWHERE реализует механизм двухфазного чтения:
- ClickHouse читает только те столбцы, которые указаны в условии PREWHERE, и фильтрует строки на их основе;
- После фильтрации ClickHouse читает оставшиеся столбцы только для тех строк, которые прошли фильтр PREWHERE.
Технически это реализуется через специальные потоки данных BlockInputStream, которые обеспечивают поэтапную обработку. При этом используются следующие компоненты:
- PrewhereExpression отвечает за вычисление выражения PREWHERE и определение, какие строки должны быть сохранены. Это выражение преобразует условия в исполняемый код для быстрой фильтрации;
- MergeTreeRangeReader обеспечивает чтение определенных диапазонов данных из хранилища, чтобы читаеть только необходимые столбцы для предварительной фильтрации;
- PrewhereBlockInputStream — специализированный поток, который реализует двухфазное чтение и управляет последовательностью операций при обработке PREWHERE.
Этапы обработки данных через потоки BlockInputStream выглядят так:
- Предварительная фильтрация:
- Базовый класс для всех потоков чтения данных из MergeTree-таблиц MergeTreeBaseSelectBlockInputStream инициирует первую фазу чтения;
- читаются только столбцы, упомянутые в PREWHERE-условии;
- специализированный класс потока данных PrewhereBlockInputStream применяет условие фильтрации к прочитанным данным;
- формируется битовая маска строк, прошедших фильтрацию
- Чтение основных данных
- специализированный класс потока данных MergeTreeReaderStreamполучает битовую маску отфильтрованных строк;
- читаются только нужные столбцы только для прошедших фильтрацию строк;
- специализированный класс потока данных JoiningBlockInputStream объединяет данные из обеих фаз чтения
- Финальная обработка
- Применяются условия WHERE к полученному набору данных
- Выполняются оставшиеся операции запроса (JOIN, GROUP BY и т.д.)
Архитектура внутренних потоков данных BlockInputStream позволяет ClickHouse достигать высокой производительности при работе с широкими таблицами, выполняя точечное чтение только необходимых данных на каждом этапе обработки запроса. Это достигается благодаря следующим оптимизациям:
- проекции столбцов для динамического определения, какие столбцы читать на каждой фазе. Подробнее про механизмы проекций в ClickHouse мы писали здесь.
- чтение гранул — блоков данных (обычно по 8192 строки), чтобы эффективнее использовать кэш процессора. Гранула в ClickHouse — это логическая организация значений столбцов для вычислений, наименьший неделимый набор данных, который передается в ClickHouse для обработки данных. Вместо чтения отдельных строк ClickHouse всегда потоково и параллельно читает целую группу строк, т.е. гранулу. Подробнее про это читайте здесь.
- динамическое перемещение условий между WHERE и PREWHERE с помощью ExpressionAnalyzer;
- параллельная обработка, т.к. потоки BlockInputStream могут выполняться параллельно на многоядерных системах;
- конвейерная обработка, когда одни стадии начинают работу до завершения предыдущих.
При использовании PREWHERE сначала читаются только гранулы столбцов из этого условия, для каждой гранулы создается битовая маска подходящих строк, которая затем используется для чтения только нужных строк из остальных столбцов. Таким образом, с PREWARE загружаются только гранулы, которые содержат хотя бы одну строку, которая совпала с предыдущим фильтром. В результате количество гранул для загрузки и оценки для каждого фильтра монотонно уменьшается.
Код обработки оператора PREWHERE в ClickHouse находится в следующих файлах:
- Interpreters/PrewhereInfo.h — структуры данных для PREWHERE;
- Storages/MergeTree/MergeTreeBaseSelectBlockInputStream.cpp — обработка PREWHERE;
- Interpreters/ExpressionAnalyzer.cpp — анализ и оптимизация
Изучив технические аспекты реализации PREWHERE, далее на практическом примере рассмотрим, какие преимущества в скорости выполнения запроса может дать эта оптимизация.
Практический пример
В качестве примера создадим таблицу логов веб-сервера.
CREATE TABLE IF NOT EXISTS http_logs (
client_ip String,
request_method String,
request_path String,
timestamp DateTime,
response_status UInt16
) ENGINE = MergeTree()
ORDER BY (timestamp, client_ip);
Наполним эту таблицу случайными данными, выполнив пакетную вставку сразу 100000 записей:
INSERT INTO http_logs (client_ip, request_method, request_path, timestamp, response_status)
SELECT
IPv4NumToString(rand() % 4294967295) AS client_ip,
arrayElement(['GET', 'POST', 'PUT', 'DELETE', 'PATCH'], rand() % 5 + 1) AS request_method,
arrayElement(['/home', '/login', '/users', '/products', '/cart', '/checkout'], rand() % 6 + 1) AS request_path,
toDateTime('2025-04-01 00:00:00') + INTERVAL rand() % (30*86400) SECOND AS timestamp,
arrayElement([200, 201, 302, 404, 501, 503], rand() % 6 + 1) AS response_status
FROM numbers(100000);
Чтобы понять, как будет выполняться запрос с оператором PREWHERE и без него, выведем план выборки из этой таблицы первых 10 случаев HTTP-ответов со статусом 404, случившихся за период с 30 апреля по 1 мая 2025 года, с указанием IP-адреса клиента, метода запроса, запрашиваемого пути и момента времени появления ответа. Синтаксис SQL-запроса с условием PREWHERE для этого случая выглядит так:
SELECT
client_ip,
request_method,
request_path,
response_status,
timestamp
FROM http_logs
PREWHERE response_status = 404
WHERE timestamp BETWEEN '2025-04-01 00:00:00' AND '2025-05-01 00:00:00'
ORDER BY timestamp
LIMIT 10;
Добавив к этому запросу EXPLAIN PIPELINE, можно увидеть план его выполнения в виде дерева потоков данных BlockInputStream. Это позволит понять, как именно выполняется запрос, какие этапы обработки данных применяются и как данные перемещаются между различными компонентами.
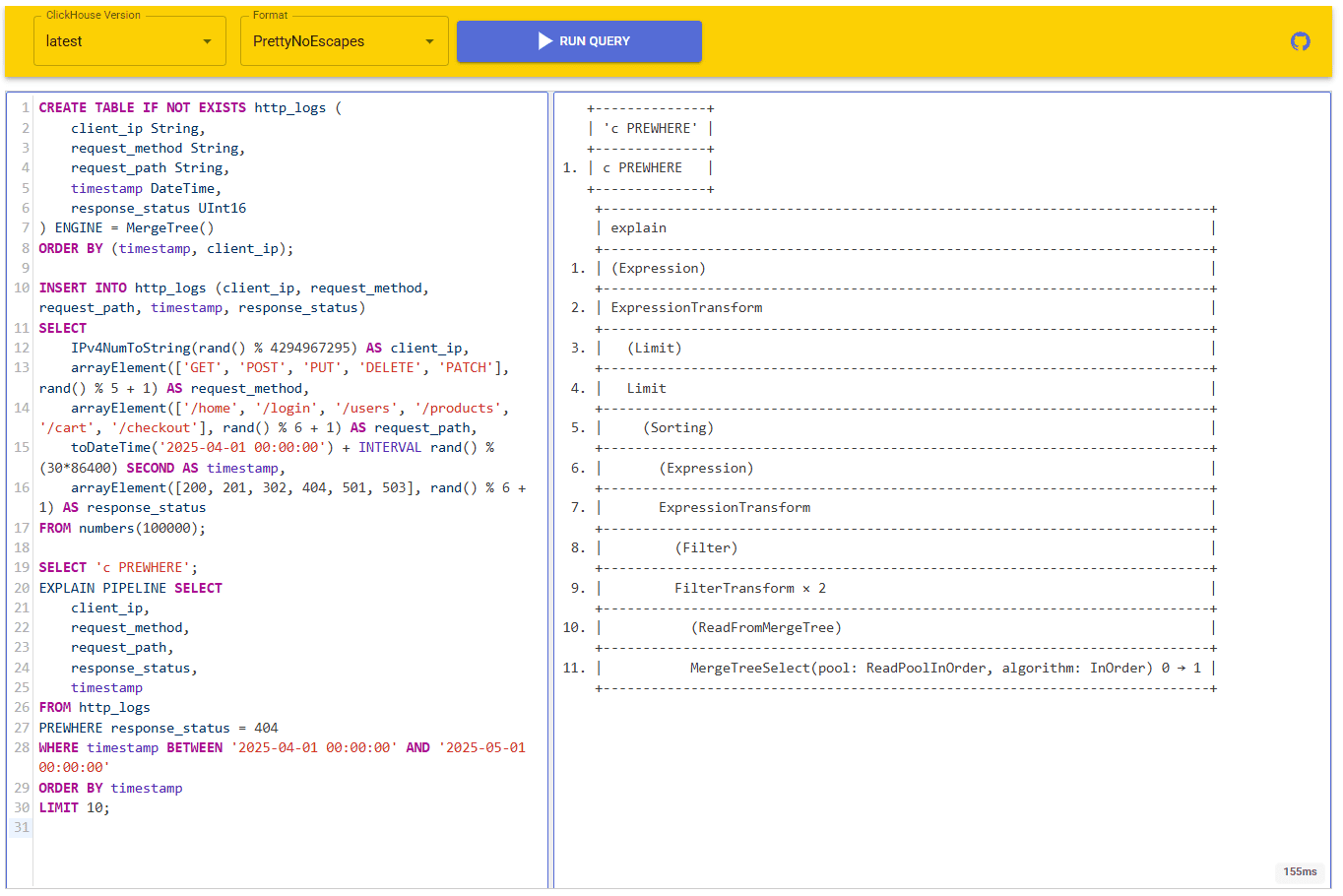
План выполнения читается снизу вверх, так как данные проходят по конвейеру обработки именно в этом направлении:
- сперва на строках 11-10 выполняется чтение данных из таблицы семейства MergeTree с использованием алгоритма последовательного чтения InOrder и пула ReadPoolInOrder;
- на строках 9-8 выполняется двойная фильтрация данных FilterTransform × 2 и Filter для отдельной обработки условий PREWHERE и WHERE. Данные читаются в две фазы, где первая фильтрация определяет, какие строки читать дальше.
- На строках 7-6 выполняется вычисление выражений и преобразование данных, вычисляются выражения в SELECT, агрегатные функции или другие вычисления, необходимые перед сортировкой;
- На строке 5 происходит сортировка промежуточных результатов, которая требует памяти для хранения всех сортируемых строк;
- Строки 4-3 ограничивают количество возвращаемых строк и могут останавливать выполнение предыдущих этапов, когда достигнут указанный лимит;
- На строках 2-1 выполняется финальная обработка, окончательное вычисление выражений и форматирование данных для вывода.
Выполнение запроса заняло 155 миллисекунд.
Теперь явно уберем PREWHERE, чтобы ClickHouse прочитал все запрошенные столбцы, а затем применил фильтр. Для этого установим настройку optimize_move_to_prewhere в значение false. По умолчанию она включена: оптимизатор сам анализирует условия и определяет, какие из них выгоднее использовать в качестве PREWHERE., чтобы сократить объем чтения данных. Меньшие столбцы сканируются быстрее, а к моменту обработки больших столбцов большинство гранул уже отфильтрованы. Поскольку все столбцы имеют одинаковое количество строк, размер столбца в первую очередь определяется его типом данных, например, столбец, UInt8 обычно намного меньше столбца со строковыми данными. ClickHouse следует этой стратегии по умолчанию, начиная с версии 23.2 , сортируя столбцы фильтра PREWHERE для многошаговой обработки в порядке возрастания несжатого размера. Начиная с версии 23.11 , дополнительная статистика столбцов может дополнительно улучшить ситуацию, выбирая порядок обработки фильтров на основе фактической селективности данных, а не только размера столбца.
Решение о том, какие условия перенести из WHERE в PREWHERE на основе, ClickHouse принимает на основе следующих факторов:
- Оценки количества строк, которые будут отфильтрованы (чем больше, тем лучше);
- Оценки стоимости чтения столбцов в PREWHERE-условии (чем меньше, тем лучше);
- Наличия индексов на столбцах PREWHERE (индексированные столбцы предпочтительнее);
- Типа условий (предпочтительнее простые условия равенства или IN).
Отключим автоматическое использование PREWHERE, задав настройку optimize_move_to_prewhere setting равной false:
SELECT
client_ip,
request_method,
request_path,
response_status,
timestamp
FROM http_logs
WHERE response_status = 404 AND timestamp BETWEEN '2025-04-01 00:00:00' AND '2025-05-01 00:00:00'
ORDER BY timestamp
LIMIT 10
SETTINGS optimize_move_to_prewhere = false;
Посмотрим план выполнения запроса:
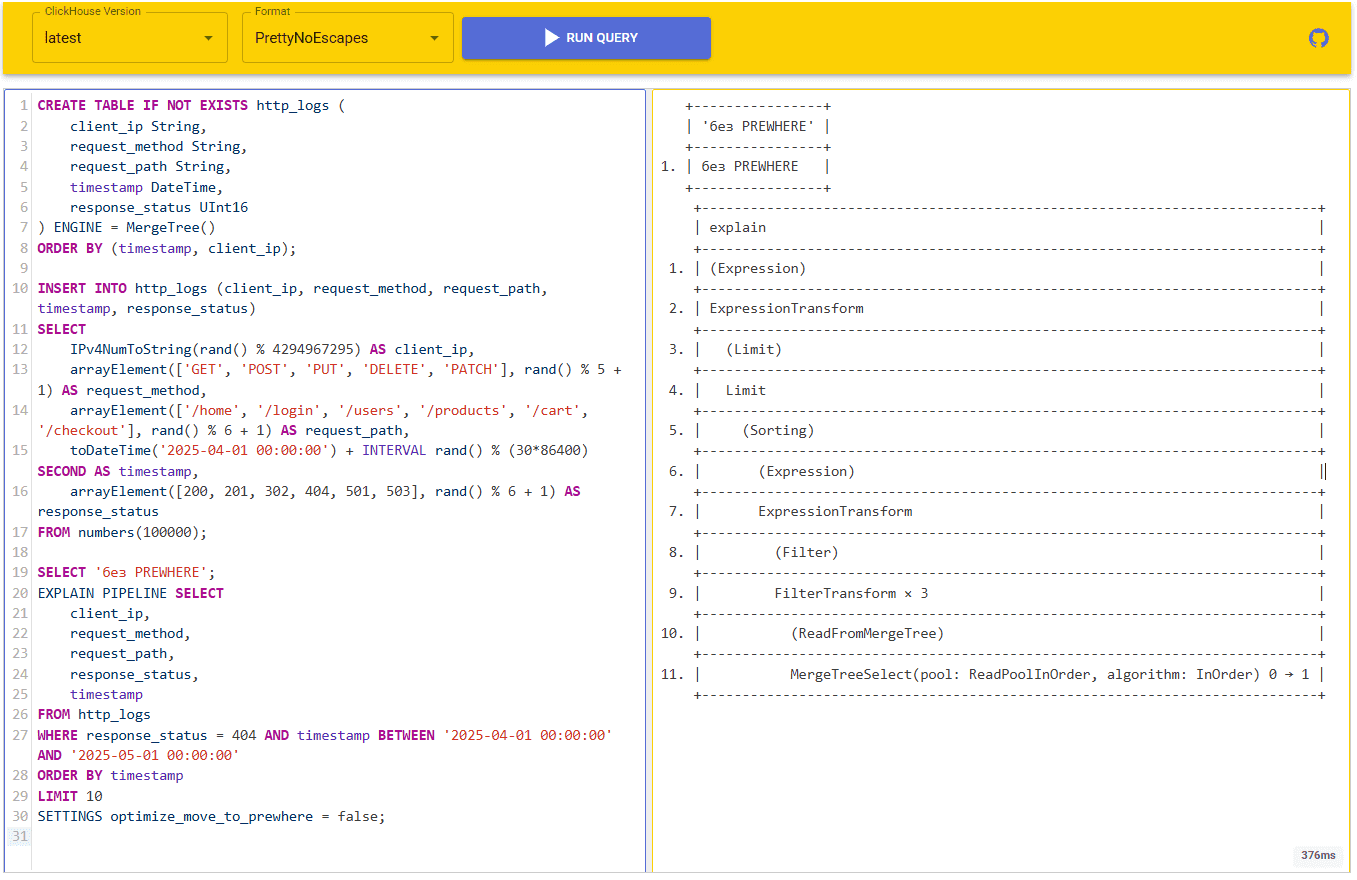
Выполнение запроса заняло 376 милисекунд.
Помимо более чем двукратного отличия во времени выполнения, полученные планы выглядят почти идентично, кроме строки 9.
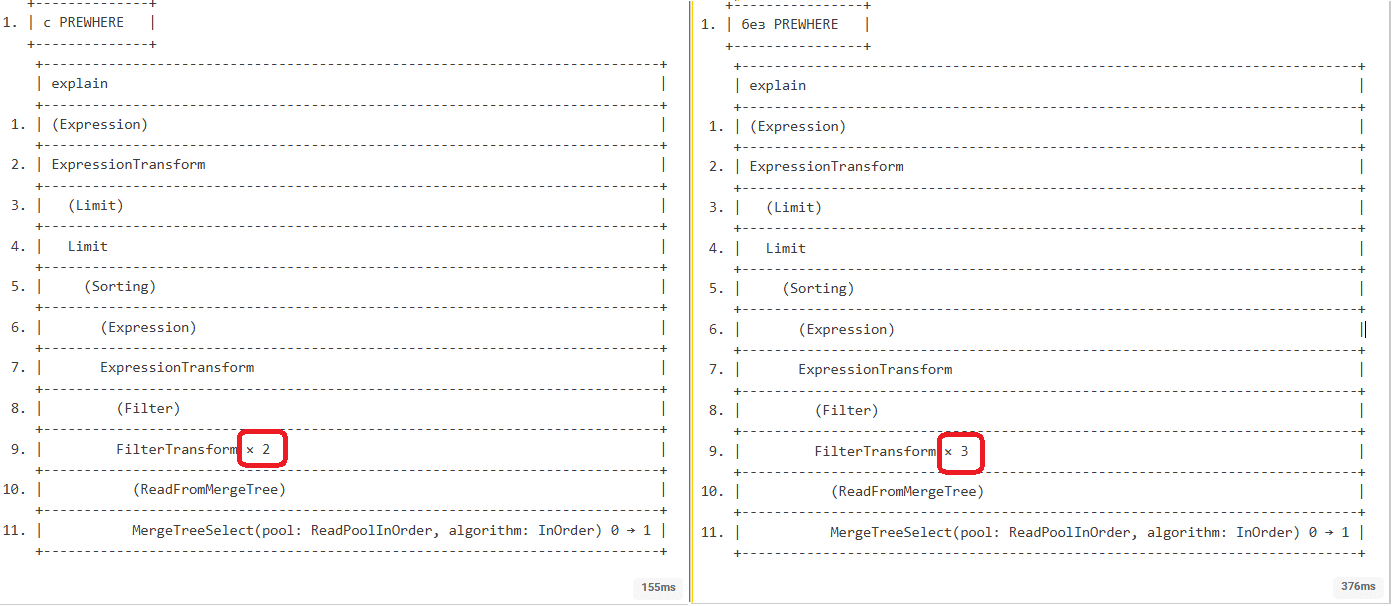
Меньшее количество операций FilterTransform при использовании PREWHERE указывает на более эффективный план выполнения, сниженную нагрузку на процессор и потенциально более высокую производительность запроса. Двухфазное чтение позволяет объединить операции фильтрации с чтением данных Без PREWHERE оптимизатор вынужден разбивать фильтрацию на больше этапов для достижения эффективности. PREWHERE отсекает ненужные данные до полного чтения, что упрощает последующую обработку, сокращая количество необходимых операций трансформации. Это подтверждает, что PREWHERE действительно оптимизирует обработку запросов, не только уменьшая объем читаемых данных, но и упрощая сам конвейер обработки данных.
В заключение еще раз подчеркнем, что PREWHERE даёт максимальное преимущество в следующих случаях:
- запрос выбирает много столбцов с большим объёмом данных;
- условие PREWHERE использует столбцы с малым объёмом данных;
- условие PREWHERE фильтрует большую часть строк (>90%).
Если условие PREWHERE фильтрует мало строк или использует столбцы с большим объёмом данных, дополнительные операции чтения могут снизить производительность по сравнению с обычным WHERE. Иногда явное указание PREWHERE может быть менее эффективным, чем автоматическое решение оптимизатора насчет применения этой оптимизации. Поэтому отключать ее не рекомендуется, т.е. желательно оставить значение по умолчанию, когда optimize_move_to_prewhere = true. Наибольший эффект дает сочетание PREWHERE с отложенной материализацией, о которой мы рассказываем в новой статье.
Освойте ClickHouse на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

