 716
716 
Содержание
Как эффективно распределять ресурсы ClickHouse между разными пользователями и запросами, настроив политику планирования рабочих нагрузок: примеры и рекомендации.
Иерархия планирования рабочей нагрузки в Clickhouse
Когда ClickHouse выполняет несколько запросов одновременно, они могут использовать общие ресурсы, например, диски, ЦП и память. Чтобы эффективно распределять ресурсы ClickHouse между разными пользователями и нагрузками, в этой колоночной СУБД есть специальные механизмы планирования рабочей нагрузки (workload management). К ним относятся следующие инструменты:
- система очередей запросов — позволяет контролировать количество одновременно выполняемых запросов;
- приоритизация запросов — дает возможность важным запросам получать ресурсы в первую очередь;
- ограничение ресурсов — устанавливает лимиты на память, ЦП и операции ввода-вывода для отдельных пользователей или групп.
Ограничения и политики планирования могут применяться для регулирования того, как ресурсы используются и распределяются между различными рабочими нагрузками. Иерархию планирования нагрузки можно настроить для каждого ресурса. Корень этой иерархии представляет собой ресурс, а листья — это очереди, содержащие запросы, которые превышают емкость ресурса.
Поскольку планирование нагрузки определяется типом запросов, в самом запросе можно указать, какой тип рабочей нагрузки использовать для более выгодной утилизации ресурсов. Это делается с помощью настройки workload в самом запросе. Также можно назначить workload-настройку для фоновых действий, например, процессов фонового слияния данных.
Рассмотрим пример системы с двумя различными рабочими нагрузками: производство (prod) и разработка (dev).
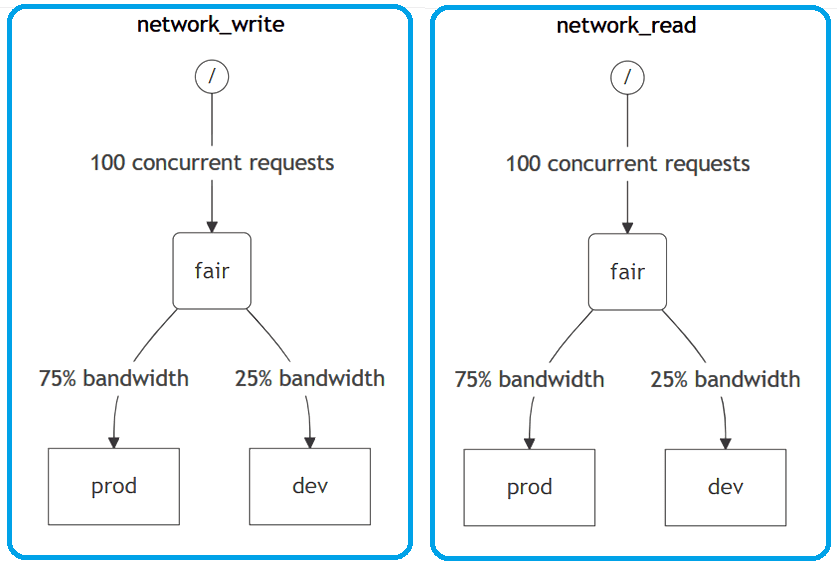
В иерархии планирования нагрузки ClickHouse возможны следующие типы узлов:
- inflight_limit (ограничение) — блокируется, если количество одновременных запросов в процессе выполнения превышает max_requests, или их общая стоимость превышает max_cost. Этот узел должен иметь один дочерний объект.
- bandwidth_limit (ограничение) — блокируется, если текущая пропускная способность превышает max_speed или превышает пик max_burst, по умолчанию равный Этот узел должен иметь один дочерний объект.
- fair (политика) — выбирает следующий запрос для обслуживания из одного из своих дочерних узлов в соответствии с принципом максимальной и минимальной справедливости. Дочерние узлы этого узла могут указать вес – weight, по умолчанию = 1.
- priority (политика) — выбирает следующий запрос для обслуживания из одного из своих дочерних узлов в соответствии со статическими приоритетами. Меньшее значение означает более высокий приоритет. Дочерние узлы этого узла могут указывать своб политику priority, по умолчанию = 0.
- fifo (очередь) — лист иерархии, способный удерживать запросы, превышающие емкость ресурсов.
Низкое значение max_requests или max_cost может привести к неполному использованию ресурса, в то время как слишком большое число может привести к пустым очередям внутри планировщика. Это приведет к игнорированию политик в поддереве. Чтобы защитить ресурсы от слишком высокой загрузки, следует задать ограничение bandwidth_limit, которое сработает, когда объем потребляемого ресурса в секундах превышает значение, равное max_burst + max_speed * duration. На одном и том же ресурсе можно определить несколько ограничений bandwidth_limit, например, для ограничения пиковой пропускной способности в течение коротких интервалов и средней пропускной способности в течение более длинных.
Как настроить планирование рабочей нагрузки: примеры
Определить ограничения, правила и политики планирования рабочей нагрузки ClickHouse можно в конфигурационном XML-файле или с помощью SQL-инструкций. Второй способ сегодня считается предпочтительным. Например, для вышеприведенного рисунка с деревом иерархии планирования оно создается следующими SQL-командами:
CREATE RESOURCE network_write (WRITE DISK s3) CREATE RESOURCE network_read (READ DISK s3) CREATE WORKLOAD all SETTINGS max_io_requests = 100 CREATE WORKLOAD dev IN all CREATE WORKLOAD prod IN all SETTINGS weight = 3
SQL-команды автоматически создают все необходимые узлы планирования, а следующее описание узла планирования следует рассматривать как детали реализации более низкого уровня, доступные через системную таблицу system.scheduler.
Для настройки рабочей нагрузки можно использовать следующие параметры:
- priority — одноуровневые рабочие нагрузки обслуживаются в соответствии со статическими значениями приоритета, причем более низкое значение означает более высокий приоритет;
- weight — одноранговые рабочие нагрузки, имеющие одинаковый статический приоритет, делят ресурсы в соответствии с весами;
- max_io_requests — ограничение на количество одновременных запросов ввода-вывода в данной рабочей нагрузке;
- max_bytes_inflight — ограничение на общее количество передаваемых байтов для одновременных запросов в этой рабочей нагрузке;
- max_bytes_per_second — ограничение скорости чтения или записи байтов для данной рабочей нагрузки;
- max_burst_bytes — максимальное количество байтов, которые может обработать рабочая нагрузка без ограничения (для каждого ресурса независимо);
- max_concurrent_threads — ограничение на количество потоков для запросов в данной рабочей нагрузке.
Все лимиты, указанные через настройки рабочей нагрузки, независимы для каждого ресурса. Например, рабочая нагрузка с max_bytes_per_second = 10485760 будет иметь ограничение пропускной способности 10 МБ/с для каждого ресурса чтения и записи независимо. Если требуется общий лимит для чтения и записи, следует использовать тот же ресурс с доступом READ и WRITE, определив для него общее значение max_bytes_per_second.
Чтобы включить планирование ввода-вывода для определенного диска, необходимо указать read_resource и/или write_resource. Это укажет ClickHouse, какой ресурс следует использовать для каждого запроса на чтение и запись с данным диском. Ресурс чтения и записи может ссылаться на одно и то же имя ресурса, что полезно для локальных SSD или HDD. Несколько разных дисков также могут ссылаться на один и тот же ресурс, что полезно для удаленных дисков, когда нужно разделять пропускную способность сети между, например, производственными и исследовательскими рабочими нагрузками. Для локальных SSD или HDD часто имеет смысл использовать один и тот же ресурс для чтения и записи, поскольку они разделяют физический диск. Для удаленных хранилищ (S3, HDFS и т.д.) часто важно делить сетевую пропускную способность.
Например, определим рабочие нагрузки для быстрых SSD и более медленных HDD-дисков:
-- Рабочая нагрузка для SSD
CREATE OR REPLACE WORKLOAD ssd_workload
SETTINGS
max_io_requests = 200, -- Максимальное количество параллельных I/O запросов
max_bytes_per_second = 100000000 FOR ssd_io; -- 100 МБ/с для общего ресурса чтения/записи
-- Рабочая нагрузка для HDD (более низкие лимиты)
CREATE OR REPLACE WORKLOAD hdd_workload
SETTINGS
max_io_requests = 50, -- Меньше параллелизма для HDD
max_bytes_per_second = 20000000 FOR hdd_io; -- 20 МБ/с для общего ресурса чтения/записи
А также для удаленных хранилищ:
-- Общая рабочая нагрузка для сетевых операций
CREATE OR REPLACE WORKLOAD network_workload
SETTINGS
max_bytes_per_second = 50000000 FOR network_read, -- 50 МБ/с для чтения
max_bytes_per_second = 30000000 FOR network_write; -- 30 МБ/с для записи
Распределим рабочие нагрузки по приоритетам:
-- Высокоприоритетная рабочая нагрузка
CREATE OR REPLACE WORKLOAD high_priority
SETTINGS
max_io_requests = 150,
max_bytes_per_second = 80000000 FOR fast_read,
max_bytes_per_second = 60000000 FOR fast_write,
max_bytes_per_second = 40000000 FOR network_read,
max_bytes_per_second = 25000000 FOR network_write;
-- Низкоприоритетная рабочая нагрузка
CREATE OR REPLACE WORKLOAD low_priority
SETTINGS
max_io_requests = 50,
max_bytes_per_second = 20000000 FOR fast_read,
max_bytes_per_second = 15000000 FOR fast_write,
max_bytes_per_second = 10000000 FOR network_read,
max_bytes_per_second = 5000000 FOR network_write;
Задать, какую именно рабочую нагрузку использовать для выполнения SQL-запросов можно на уровне пользовательской сессии или отдельного запроса. Например, установив рабочую нагрузку для пользовательской сессии, все запросы, выполняемые в ней, будут использовать заданные ограничения ресурсов:
SET workload = 'high_priority';
Можно установить рабочую нагрузку только для одного запроса:
SELECT *
FROM
(
WITH workload = 'low_priority'
SELECT
date,
user_id,
SUM(revenue) AS total_revenue
FROM events
WHERE date BETWEEN '2025-01-01' AND '2025-05-01'
GROUP BY date, user_id
)
ORDER BY total_revenue DESC
LIMIT 10;
Или использовать разные рабочие нагрузки для разных частей запроса:
SELECT
a.user_id,
a.total_events,
b.total_revenue
FROM
(
-- низкоприоритетная рабочая нагрузка для тяжеловесного аналитического подсчета
WITH workload = 'low_priority'
SELECT
user_id,
COUNT(*) AS total_events
FROM events
WHERE date BETWEEN '2025-01-01' AND '2025-05-01'
GROUP BY user_id
) a
JOIN
(
-- Высокоприоритетная рабочая нагрузка для подсчета выручки
WITH workload = 'high_priority'
SELECT
user_id,
SUM(revenue) AS total_revenue
FROM transactions
WHERE date BETWEEN '2025-01-01' AND '2025-05-01'
GROUP BY user_id
) b
ON a.user_id = b.user_id
ORDER BY b.total_revenue DESC
LIMIT 100;
Таким образом, планирование рабочей нагрузки в Clickhouse – довольно полезная функция, которая пригодится в следующих случаях:
- в многопользовательской среде с разным приоритетом пользователей;
- при наличии смешанной нагрузки, например, тяжеловесные аналитические запросы и быстрые ad-hoc запросы;
- когда ресурсы ограничены, и их следует рационально использовать;
- есть критически важные запросы, которые не должны задерживаться;
- есть отдельные тяжеловесные запросы, которые могут блокировать всю систему.
Разумеется, планировать можно не только использование диска и пропускной способности сети, но и количество потоков ЦП. Например, в релизе 25.4, вышедшем в апреле 2025 года, добавлена возможность планирования слотов ЦП для рабочих нагрузок, чтобы ограничивать количество одновременных потоков для определенной рабочей нагрузки. Как это работает, рассмотрим в следующий раз.
Освойте ClickHouse на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

