 628
628 
Как ускорить выполнение SQL-запроса в ClickHouse, сократив объем сканируемых данных с помощью оператора PREWHERE: практический пример простой, но эффективной оптимизации.
Как работает оператор PREWHERE в ClickHouse
ClickHouse имеет ряд многоуровневых оптимизаций, благодаря которым позволяет анализировать огромные объемы данных почти в реальном времени. Одной из таких оптимизаций является PREWHERE, которая сокращает объем сканируемых данных и повышает скорость выполнения запроса. Эта оптимизация входит в ClickHouse с самого первого выпуска и считается уникальной, по крайней мере, по названию. Именно само ключевое слово PREWHERE встречается только в ClickHouse, хотя концептуально похожие оптимизации есть и в других СУБД, например, Vertica, Oracle, Apache Impala, Greenplum и PostgreSQL поддерживают Predicate Pushdown — механизм, который позволяет применять фильтры до чтения всех данных. В MySQL и MariaDB есть Condition Pushdown для работы с подзапросами и внешними таблицами, в Apache Druid и Snowflake существуют похожие внутренние оптимизации для раннего применения фильтров.
Однако, использование PREWHERE в ClickHouse требует явного указания этого в синтаксисе и предоставляет дата-инженеру прямой контроль над этой оптимизацией. Можно комбинировать PREWHERE и WHERE в одном запросе, чтобы повысить его гибкость. Также можно сочетать PREWHERE с другими оптимизациями, такими как разреженные индексы и отложенная материализация, усиливая их эффект.
В обычном SQL-запросе с условием WHERE сначала читаются все столбцы таблицы, а затем применяется фильтрация. Особенность PREWHERE в том, что ClickHouse сначала читает только те столбцы, которые упомянуты в этом условии, отфильтровывает подходящие данные и только после этого читает значительно меньше строк из остальных столбцов.
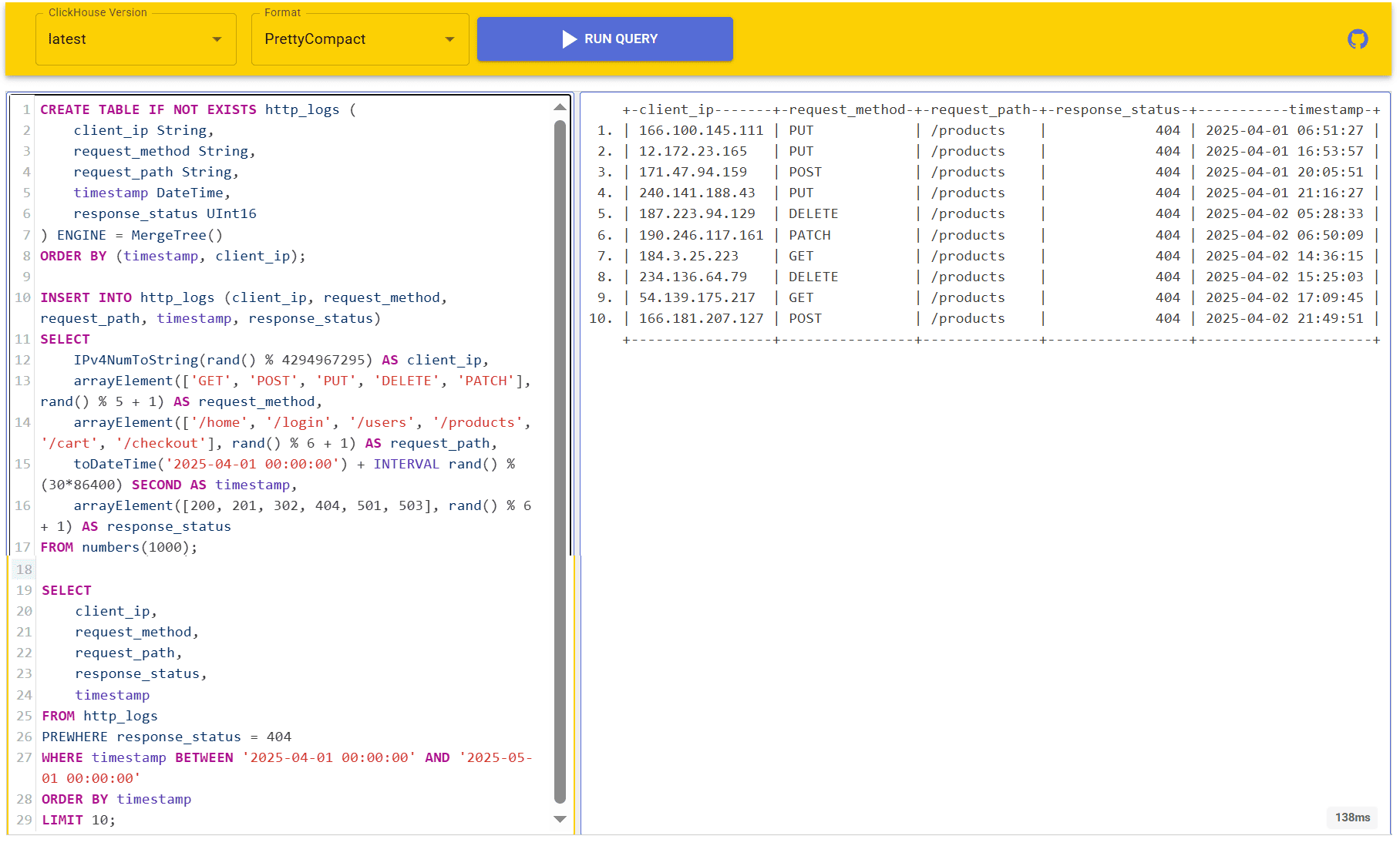
Это особенно эффективно для широких таблиц со множеством столбцов, когда условие фильтрации отсекает большую часть данных или использует столбцы с низкой кардинальностью, т.е. данные в которых повторяются часто. Например, создадим таблицу логов веб-сервера.
CREATE TABLE IF NOT EXISTS http_logs (
client_ip String,
request_method String,
request_path String,
timestamp DateTime,
response_status UInt16
) ENGINE = MergeTree()
ORDER BY (timestamp, client_ip);
Наполним эту таблицу случайными данными:
INSERT INTO http_logs (client_ip, request_method, request_path, timestamp, response_status)
SELECT
IPv4NumToString(rand() % 4294967295) AS client_ip,
arrayElement(['GET', 'POST', 'PUT', 'DELETE', 'PATCH'], rand() % 5 + 1) AS request_method,
arrayElement(['/home', '/login', '/users', '/products', '/cart', '/checkout'], rand() % 6 + 1) AS request_path,
toDateTime('2025-04-01 00:00:00') + INTERVAL rand() % (30*86400) SECOND AS timestamp,
arrayElement([200, 201, 302, 404, 501, 503], rand() % 6 + 1) AS response_status
FROM numbers(1000);
Получим из этой таблицы первые 10 случаев HTTP-ответов со статусом 404, случившихся за период с 30 апреля по 1 мая 2025 года, с указанием IP-адреса клиента, метода запроса, запрашиваемого пути и момента времени появления ответа. Синтаксис SQL-запроса с условием PREWHERE для этого случая выглядит так:
SELECT
client_ip,
request_method,
request_path,
response_status,
timestamp
FROM http_logs
PREWHERE response_status = 404
WHERE timestamp BETWEEN '2025-04-01 00:00:00' AND '2025-05-01 00:00:00'
ORDER BY timestamp
LIMIT 10;
В этом запросе ClickHouse выполняет следующие шаги:
- сперва читает только поле response_status и отфильтрует только строки со статусом 404, т.к. это указано в условии PREWHERE. Нужный статус ответа указан в условии PREWHERE, т.к. статус HTTP-ответа имеет низкую кардинальность и занимает мало места, тогда как URL-пути и другие поля могут быть значительно больше по размеру. Кроме того, ошибки 404 обычно составляют лишь небольшой процент от всех HTTP-ответов, поэтому фильтрация по этому полю существенно сокращает объем данных для последующей обработки;
- затем применяет фильтр по timestamp из условия WHERE;
- после этого читает остальные запрошенные поля (client_ip, request_method, request_path) для отфильтрованных строк.
Проверим результаты выполнения запросов в песочнице fiddle:
Если не использовать PREWHERE, т.е. оставить только оператор WHERE в SQL-запросе, ClickHouse прочитает все запрошенные столбцы, а затем применит фильтр. В этом случае объем сканируемых данных будет больше, а значит, запрос будет выполняться медленнее. При работе с вложенными JSON-структурами оптимизация PREWHERE позволяет читать только нужные части JSON, что значительно повышает производительность. Оператор PREWHERE наиболее эффективен для широких таблиц и больших сканирований с селективными фильтрами, т.к. ClickHouse фильтрует данные столбец за столбцом, загружая только то, что действительно необходимо. Это радикально снижает затраты на дисковый ввод-вывод, особенно для широких таблиц. Поэтому PREWHERE рекомендуется использовать в следующих случаях:
- запрос содержит фильтрацию по столбцам с небольшим объемом данных;
- запрос выбирает множество столбцов;
- условие фильтрации отсекает большое количество строк.
Во многих случаях ClickHouse автоматически преобразует подходящие условия из WHERE в PREWHERE, даже если этот оператор явно не указан в запросе, но настройка optimize_move_to_prewhere включена, т.е. равно true. По умолчанию это так и есть, но ее можно отключить вручную. Оптимизатор анализирует условия и определяет, какие из них выгоднее использовать в качестве PREWHERE., чтобы сократить объем чтения данных. Меньшие столбцы сканируются быстрее, а к моменту обработки больших столбцов большинство гранул уже отфильтрованы. Поскольку все столбцы имеют одинаковое количество строк, размер столбца в первую очередь определяется его типом данных, например, столбец, UInt16 обычно намного меньше столбца со строковыми данными. ClickHouse следует этой стратегии по умолчанию, начиная с версии 23.2 , сортируя столбцы фильтра PREWHERE для многошаговой обработки в порядке возрастания несжатого размера. Начиная с версии 23.11 , дополнительная статистика столбцов может дополнительно улучшить ситуацию, выбирая порядок обработки фильтров на основе фактической селективности данных, а не только размера столбца.
Чтобы убедиться, что PREWHERE помогает запросам, можно сравнить производительность их выполнения с включенной функцией optimize_move_to_prewhere setting и без нее, добавив соответствующую настройку в SQL-запрос. Например, следующий запрос выключает PREWHERE:
SELECT
client_ip,
request_method,
request_path,
response_status,
timestamp
FROM http_logs
WHERE response_status = 404 AND timestamp BETWEEN '2025-04-01 00:00:00' AND '2025-05-01 00:00:00'
ORDER BY timestamp
LIMIT 10
SETTINGS optimize_move_to_prewhere = false;
Важно, что PREWHERE сокращает количество считываемых данных, а не обрабатываемых строк: ClickHouse обрабатывает одинаковое количество строк в обеих версиях запроса: с оператором PREWHERE и без него. Однако при использовании PREWHERE не все значения столбцов нужно загружать для каждой обработанной строки.
В заключение отметим, что PREWHERE работает только с табличными движками семейства MergeTree. В запросе может быть только одно условие PREWHERE. Кроме того, иногда применение PREWHERE к столбцу с большим объемом данных может снизить производительность запроса.
Разобравшись с тем, как работает эта оптимизация, в следующей статье рассмотрим ее техническую реализацию, проанализировав планы выполнения запросов.
Освойте ClickHouse на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

