
Apache Samza (Самза) – это асинхронная вычислительная Big Data среда с открытым исходным кодом для распределенных потоковых вычислений практически в реальном времени, разработанная в 2013 году в соцсети LinkedIn на языках Scala и Java. Проектом верхнего уровня Apache Software Foundation Самза стала в 2014 году [1]. Samza vs Apache Kafka...
Scikit-learn (Sklearn) – это библиотека с реализацией целого ряда алгоритмов для обучения с учителем (Supervised Learning) и обучения без учителя (Unsupervised Learning) через интерфейс для языка программирования Python. Scikit-learn построена на основе SciPy (Scientific Python). Кроме того Sklearn имеет следующие зависимости: NumPy: расширение языка Python, добавляющее поддержку больших многомерных массивов и матриц,...
Segmentation image – технология, связанная с компьютерным зрением (computer vision) и обработкой изображений, заключающаяся в обнаружении объектов определенных классов на цифровых изображениях и видео. Причем, обнаружение объектов заключается в определении класса (раскраска) каждого пикселя на цифровом изображении или на каждом кадре видеопотока. Пример кода вы можете посмотреть на GitHub MachineLearningIsEasy...
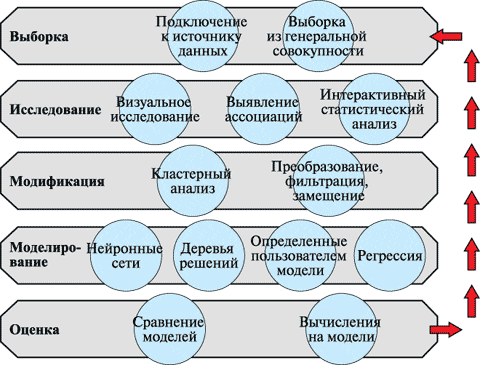
SEMMA (аббревиатура от английских слов Sample, Explore, Modify, Model и Assess) – общая методология и последовательность шагов интеллектуального анализа данных (Data Mining), предложенная американской компанией SAS, одним из крупнейших производителей программного обеспечения для статистики и бизнес-аналитики, для своих продуктов [1]. Зачем нужен стандарт SEMMA В отличие от другого широко используемого...
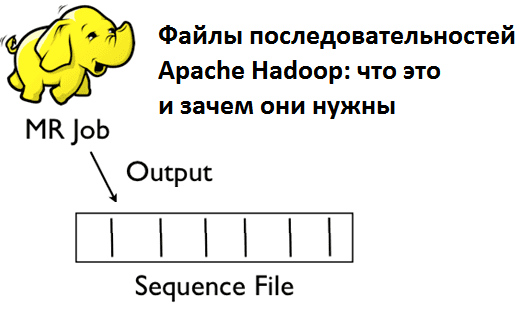
Sequence File (файл последовательностей) – это двоичный формат для хранения Big Data в виде сериализованных пар ключ/значение в экосистеме Apache Hadoop, позволяющий разбивать файл на участки (порции) при сжатии. Это обеспечивает параллелизм при выполнении задач MapReduce, т.к. разные порции одного файла могут быть распакованы и использованы независимо друг от друга...

Apache Spark – это Big Data фреймворк с открытым исходным кодом для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных, входящий в экосистему проектов Hadoop [1]. История появления Спарк и сравнение с Apache Hadoop Основным автором Apache Spark считается Матей Захария (Matei Zaharia), румынско-канадский учёный в области информатики. Он...
Spark SQL - это часть Spark Structured API, с помощью этого API Вы можете работать с данными так, как будто Вы работаете с SQL сервером. API работает в обе стороны: результат выполнения SQL запроса - dataframe, в обратном направлении - регистрация существующего dataframe, как таблицы (к которой можно выполнить SQL...

Spark Streaming – это библиотека фреймворка Apache Spark для обработки непрерывных потоковых данных, которая оперирует с дискретизированным потоком DStream, чей API базируется на отказоустойчивой структуре RDD (Resilient Distributed Dataset, надежная распределенная коллекция типа таблицы). Несмотря на позиционирование Spark Streaming в качестве средства потоковой обработки, на самом деле эта библиотека реализует микропакетный подход (micro-batch), интерпретируя поток...
Apache Storm (Сторм, Шторм) – это Big Data фреймворк с открытым исходным кодом для распределенных потоковых вычислений в реальном времени, разработанный на языке программирования Clojure. Изначально созданный Натаном Марцем и командой из BackType, этот проект был открыт с помощью исходного кода, приобретенного Twitter. Первый релиз состоялся 17 сентября 2011 года,...

Spark Structured Streaming – это библиотека фреймворка Apache Spark для обработки непрерывных потоковых данных, основанная на модуле Spark SQL и API его основных структур данных – Dataframe и Dataset, поддерживаемыми в языках Java, Scala, Python и R. Как устроен Apache Spark Structured Streaming: основные принципы работы Модуль Apache Spark Structured Streaming был впервые выпущен в версии фреймворка...