 878
878 
Содержание
Apache Samza (Самза) – это асинхронная вычислительная Big Data среда с открытым исходным кодом для распределенных потоковых вычислений практически в реальном времени, разработанная в 2013 году в соцсети LinkedIn на языках Scala и Java. Проектом верхнего уровня Apache Software Foundation Самза стала в 2014 году [1].
Samza vs Apache Kafka Streams: сходства и различия
Apache Samza часто сравнивают с Kafka Streams. На самом деле, эти продукты очень похожи между собой [2]:
- оба решения созданы одними и теми же разработчиками, которые внедрили Samza в LinkedIn, а затем основали компанию Confluent, где и была написана Kafka Streams;
- обе технологии тесно связаны с Kafka – они получают оттуда необработанные данные, производят вычисления и затем возвращают обработанные данные обратно;
- низкая задержка обработки данных (low latency) характерна для обоих решений;
- общие концептуальные понятия – примитивом потоковой обработки является сообщение (message), обращение к данным ведется по разделам топика (partition).
Таким образом, можно сказать, что Самза – это своего рода более масштабная версия Kafka Streams. Однако, Kafka Streams – это библиотека, предназначенная, в первую очередь, для микросервисов, работающих с кластером Кафка, тогда как Samza является полноценной распределенной средой потоковых вычислений под управлением YARN [2].
Как работает Apache Samza: архитектура и принцип действия
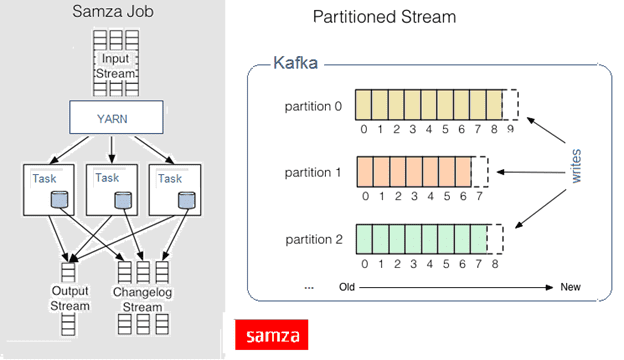
По аналогии с Apache Kafka Streams, Samza считывает данных из входных потоков (Input Stream), ассоциированных с топиками Кафка, и записывает их в логи изменений (Changelog Stream) и выходные потоки (Output Stream), также ассоциированные с соответствующими топиками.
Как мы уже упоминали, Самза часто сравнивается с другим распределённым фреймворком потоковой обработки, Apache Storm. В частности, они используют похожую модель параллелизма, разделяя работу на независимые задачи, которые могут выполняться параллельно. При этом распределение ресурсов не зависит от количества задач: небольшая работа может хранить все задачи в одном процессе на одном компьютере, а большая работа может распределить задачи по многим процессам на многих машинах [3].
Однако, Storm использует один поток на задачу по умолчанию, тогда как Samza использует однопоточные процессы (контейнеры). Контейнер Samza может содержать несколько задач, но есть только один поток, который вызывает каждую из задач по очереди. Это означает, что каждый контейнер сопоставлен ровно с одним ядром ЦП, что значительно упрощает модель распределения ресурсов и уменьшает помехи от других задач, выполняемых на той же машине. Преимущество многопоточной модели Storm в том, что она лучше использует избыточную емкость на простаивающей машине за счет менее предсказуемой модели ресурсов [3].
Преимущества и недостатки Самза
Среди ключевых достоинств Samza стоит отметить следующие [2]:
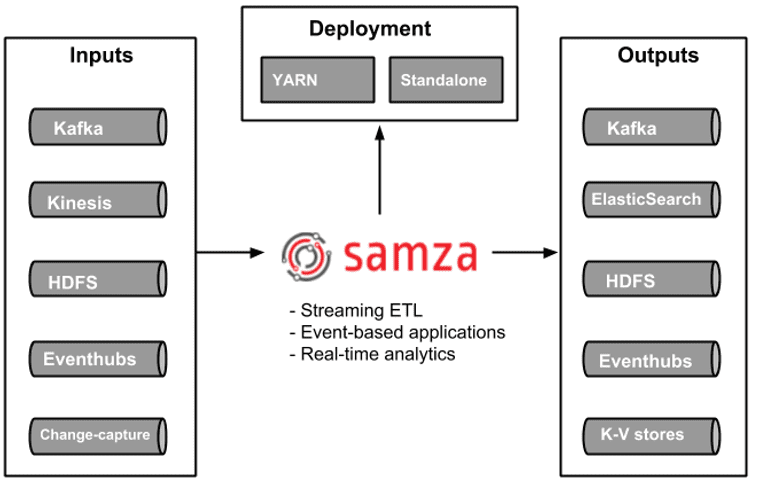
- интеграция с несколькими источниками данных – можно создавать потоковые приложения, которые обрабатывают данные в режиме реального времени из нескольких источников, включая Apache Kafka;
- наличие Beam-совместимого API-интерфейса, который позволяет переносить конвейеры обработки данных между Самза, Spark или Flink, а также обрабатывать данные на других, не только Java-подобных, языках программирования, включая Python [4].
- низкая задержка обработки данных (latency) — в отличие от пакетных Big Data систем (Apache Hadoop или Spark), Samza обеспечивает непрерывные вычисления и вывод, что приводит к времени отклика менее 1 секунды;
- реализация stateful-приложений — с сохранением состояния во встроенном хранилище пар ключ-значение;
- встроенная Big Data система управления ресурсами кластера – YARN;
- отказоустойчивость, масштабируемость и высокая производительность за счет свойств Kafka.
В тоже время, для Самза характерны следующие недостатки [2]:
- привязанность к Kafka и Yarn – если эти Big Data инструменты не используются в вашем конвейере потоковой обработки, придется самостоятельно настраивать интеграцию с другими средствами, что потребует времени и усилий;
- обеспечение семантики минимум однократной доставки сообщений (at least once). Отметим, что другие популярные Big Data фреймворки распределенных потоковых вычислений, в частности, Kafka Streams, Apache Spark, Flink и Storm (с помощью высокоуровневого API Trident) поддерживают строго однократную доставку (exactly once), которая позволяет избежать дублирования и пропусков сообщений;
- отсутствие возможностей гибкой потоковой обработки, например, временных и сеансовых окон, как в Kafka Streams.
А где используется Apache Samza на практике, мы рассказываем в отдельной статье.
Источники
- https://en.wikipedia.org/wiki/Apache_Samza
- https://medium.com/@chandanbaranwal/spark-streaming-vs-flink-vs-storm-vs-kafka-streams-vs-samza-choose-your-stream-processing-91ea3f04675b
- http://samza.apache.org/learn/documentation/0.7.0/comparisons/storm/
- https://www.zdnet.com/article/real-time-data-processing-just-got-more-options-linkedin-releases-apache-samza-1-0-streaming/