 1334
1334 
Содержание
- Место Scikit-learn в экосистеме Python
- Архитектура: Три кита API, на которых все держится
- Принцип работы Scikit learn: Магия Fit и Predict
- Сценарий 1: Ваша первая модель (Классификация)
- Сценарий 2: Подготовка "грязных" данных (Preprocessing)
- Продвинутый уровень использования библиотеки Scikit learn : Pipeline (Конвейер)
- Как выбрать правильный алгоритм в Scikit-Learn?
- Заключение
- Референсные источники
Scikit-learn (sklearn) — это библиотека для языка Python, предназначенная для машинного обучения, предоставляющая единый интерфейс для алгоритмов классификации, регрессии, кластеризации, снижения размерности и оценки моделей на основе данных. Библиотека, которая превращает сложную математику машинного обучения в понятные Python-команды. Если NumPy и Pandas — это «кирпичи» и «цемент» для работы с данными, то Scikit-learn — это готовые чертежи зданий.
Когда я только начинал путь в Data Science, меня пугали формулы градиентного спуска и матричных перемножений. Scikit-learn стал спасением — он прячет академическую сложность за простым и логичным интерфейсом. Это не просто библиотека, это «золотой стандарт» для классического ML (Machine Learning), на котором учатся и работают миллионы специалистов.
Для глубокого погружения в тему рекомендую параллельно смотреть наш бесплатный курс по основам Python для Data Mining и ML. Там мы на практике разбираем базу, без которой сложно понять, что происходит внутри алгоритмов sklearn.
Место Scikit-learn в экосистеме Python
Важно понимать: Scikit-learn не висит в вакууме. Он стоит на плечах гигантов. В серии наших статей мы разбираем весь стек, и sklearn — это, пожалуй, самый захватывающий этап.
Вот как это работает в связке:
- NumPy: Отвечает за быструю математику и работу с массивами (матрицами). Sklearn внутри себя «думает» на языке NumPy.
- Pandas: Нужен, чтобы загрузить Excel или CSV файл и привести его в табличный вид. Мы скармливаем данные из Pandas в Sklearn.
- Matplotlib / Seaborn: Помогают нарисовать графики, чтобы понять, насколько хорошо наша модель обучилась.
- Scikit-learn: Берет подготовленные цифры и находит в них скрытые закономерности.
Если вы пропустили основы NumPy или Pandas, вернитесь к соответствующим статьям нашей Wiki или загляните в курс. Без понимания того, что такое «массив» или «датафрейм», магия sklearn может показаться черной магией.
Архитектура: Три кита API, на которых все держится
Главная «фишка» библиотеки — ее унифицированный дизайн (API). Создатели договорились: неважно, используете вы простую Линейную Регрессию или сложный Случайный Лес, команды будут одними и теми же. Это гениально, потому что вам не нужно учить новый синтаксис для каждого алгоритма.
Вся библиотека строится на трех понятиях. Если вы поймете их суть, вы поймете 90% библиотеки.
Estimator (Оценщик) — «Мозг»
Это любой объект, который может учиться на данных. Представьте его как студента перед экзаменом.
- Главный метод: .fit(X, y). Вы передаете ему учебник (данные X) и правильные ответы (y). Он читает, находит закономерности и сохраняет их в своей «памяти» (внутренних параметрах).
Transformer (Трансформер) — «Фильтр»
Данные в реальном мире грязные. Модели не понимают текст, они не любят пропуски. Трансформеры приводят данные в порядок.
- Главный метод: .transform(X). Берет «сырые» данные и возвращает «чистые», готовые к употреблению моделью.
Predictor (Предиктор) — «Оракул»
Это обученный Оценщик, который готов работать.
- Главный метод: .predict(X_new). Вы даете ему новые данные (без ответов), и он, основываясь на прошлом опыте (после .fit), выдает прогноз.
Принцип работы Scikit learn: Магия Fit и Predict
Давайте разберем механику на атомарном уровне. Новички часто пишут model.fit(), не задумываясь, что происходит «под капотом». Когда вы инициализируете модель, например, Линейную Регрессию, она пуста.Она знает общую формулу уравнения y = ax + b, но не знает значений коэффициентов a и b. Процесс изменения состояния выглядит так:
import numpy as np
from sklearn.linear_model import LinearRegression
# --- ШАГ 1: Создаем игрушечные данные ---
# Представим простую закономерность: y = 2 * x + 10
# Если x=1, то y=12. Если x=2, то y=14.
X_train = np.array([[1], [2], [3], [4], [5]]) # Признаки (обязательно 2D массив!)
y_train = np.array([12, 14, 16, 18, 20]) # Ответы
# --- ШАГ 2: Инициализация (Рождение модели) ---
model = LinearRegression()
print("--- ДО ОБУЧЕНИЯ ---")
# Проверяем, есть ли у модели "знания" (коэффициенты)
# В sklearn обученные параметры всегда заканчиваются на нижнее подчеркивание (_)
has_weights = hasattr(model, 'coef_')
has_bias = hasattr(model, 'intercept_')
print(f"Модель знает коэффициент наклона (a)? -> {has_weights}")
print(f"Модель знает сдвиг (b)? -> {has_bias}")
# Если мы попытаемся сделать predict сейчас, получим ошибку (в старых версиях)
# или предупреждение, что модель не обучена.
Когда вы вызываете .fit(X, y), запускается математический алгоритм оптимизации. Модель смотрит на ваши данные и подбирает такие внутренние коэффициенты, чтобы ошибка была минимальной. Scikit-learn взял ваши точки, применил метод наименьших квадратов и вычислил, что идеальная линия проходит через уравнение y = 2x + 10.
# --- ШАГ 3: Обучение (.fit) ---
print("\n...Запускаем process model.fit(X, y)...")
model.fit(X_train, y_train)
# --- ШАГ 4: Результат (Модель обучена) ---
print("\n--- ПОСЛЕ ОБУЧЕНИЯ ---")
# Теперь атрибуты появились
print(f"Найденный наклон (coef_): {model.coef_[0]:.1f}") # Ожидаем 2.0
print(f"Найденный сдвиг (intercept_): {model.intercept_:.1f}") # Ожидаем 10.0
Теперь модель не пуста! Внутри неё появились числа (веса 2 и 10), которые описывают ваши данные. Это и есть «обучение» и теперь модель готова к работе.
Когда вы вызываете .predict(X_test), модель просто подставляет новые иксы в формулу с уже найденными коэффициентами.
Важное правило: Мы всегда обучаем (fit) модель только на тренировочных данных. Если вы покажете модели тестовые данные на этапе обучения, это будет жульничеством (data leakage). Модель просто «выучит» ответы, а не найдет закономерности.
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Сценарий 1: Ваша первая модель (Классификация)
Разберем классическую задачу ML «Hello World«: классификацию сортов ирисов по размеру лепестков. Мы будем использовать алгоритм KNN (K-Nearest Neighbors), который работает по принципу «скажи мне, кто твои соседи, и я скажу, кто ты«.
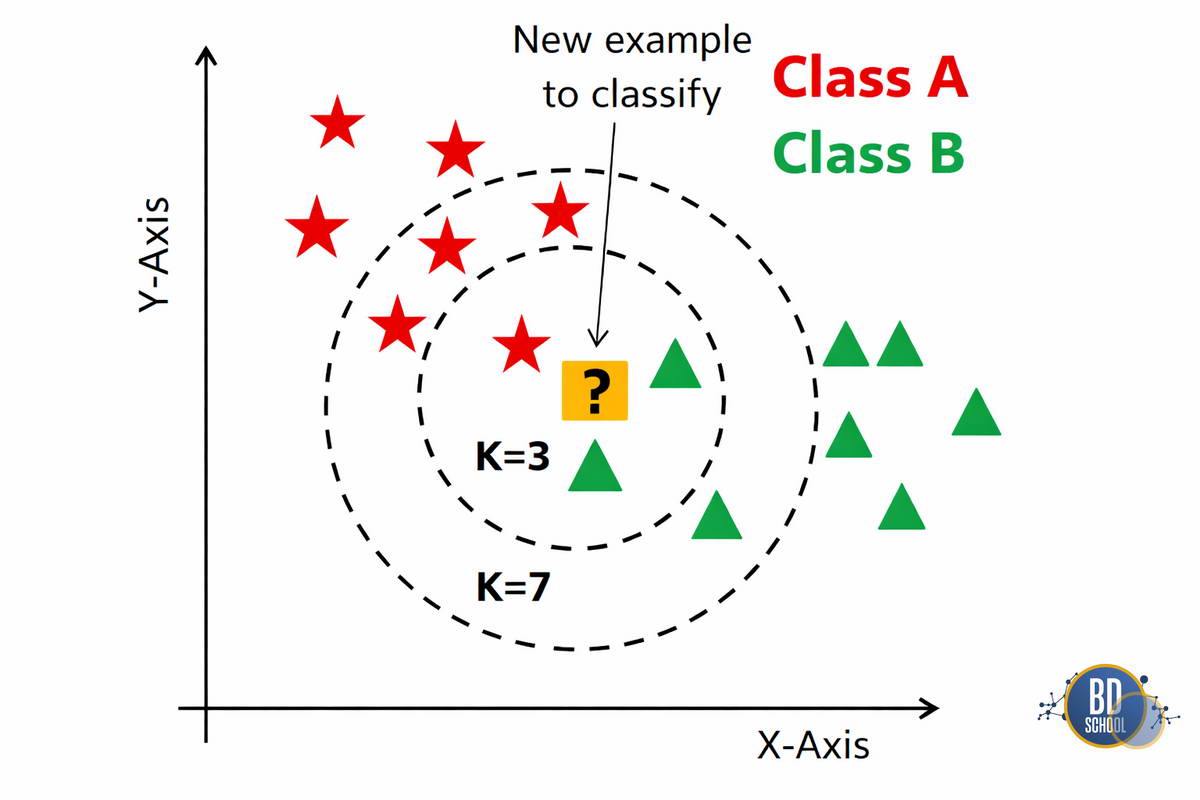
Код ниже показывает полный цикл от загрузки до оценки:
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 1. Загрузка данных
iris = datasets.load_iris()
X = iris.data # Признаки (размеры лепестков)
y = iris.target # Ответы (сорта 0, 1, 2)
# 2. Разделение выборки (Критический шаг!)
# Мы прячем 20% данных для честного экзамена [cite: 55]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 3. Инициализация модели
# n_neighbors=3 означает, что смотрим на 3 ближайших соседей
model = KNeighborsClassifier(n_neighbors=3)
# 4. Обучение (Fit)
model.fit(X_train, y_train)
# 5. Предсказание (Predict)
predictions = model.predict(X_test)
# 6. Оценка точность
accuracy = accuracy_score(y_test, predictions)
print(f"Точность модели: {accuracy*100:.1f}%")
В этом примере мы использовали алгоритм KNN (K-Nearest Neighbors). Он интуитивно понятен: «скажи мне, кто твои друзья, и я скажу, кто ты». Если точка данных окружена «синими» точками, она, скорее всего, тоже «синяя».
Сценарий 2: Подготовка «грязных» данных (Preprocessing)
В учебниках данные идеальны. В жизни — никогда. Представьте, что вы загрузили таблицу из Excel, а там:
- В колонке «Возраст» есть пустые ячейки.
- Колонка «Зарплата» в рублях (числа огромные), а «Стаж» в годах (числа маленькие).
- Есть колонка «Пол» со значениями «М» и «Ж».
Модель не поймет текст и сломается на пустотах. А разница в масштабах чисел заставит некоторые алгоритмы (например, тот же KNN) думать, что «Зарплата» в миллион раз важнее «Стажа«. Здесь на сцену выходят Трансформеры.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
import pandas as pd
import numpy as np
# Сырые данные с проблемами
data = pd.DataFrame({
'age': [25, np.nan, 30], # Пропуск
'salary': [50000, 60000, 55000], # Большой масштаб
'gender': ['M', 'F', 'M'] # Текст
})
# 1. Лечение пропусков (Imputation)
# Заменяем пустоту на среднее значение
imputer = SimpleImputer(strategy='mean')
data['age'] = imputer.fit_transform(data[['age']])
# 2. Масштабирование (Scaling)
# Приводим зарплату к стандартному нормальному распределению
scaler = StandardScaler()
data['salary'] = scaler.fit_transform(data[['salary']])
# 3. Кодирование текста (Encoding)
# Превращаем буквы в векторы [1, 0] и [0, 1]
encoder = OneHotEncoder(sparse_output=False)
gender_encoded = encoder.fit_transform(data[['gender']])
print("Обработанные данные готовы к ML!")
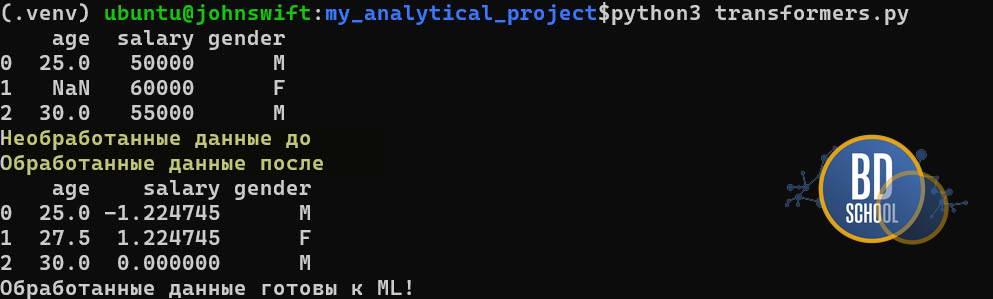
Этот процесс называется Feature Engineering. Опытный дата-сайентист тратит на него 70-80% времени. Scikit-learn предоставляет для этого десятки инструментов в модуле sklearn.preprocessing.
Продвинутый уровень использования библиотеки Scikit learn : Pipeline (Конвейер)
Когда шагов обработки становится много, код превращается в «лапшу». Вы забудете применить скейлер к тестовой выборке, и модель выдаст бред. Чтобы этого не случилось, в Scikit-learn придумали Pipeline. Главная фишка пайплайна — он позволяет скармливать модели «сырые» данные. Тебе не нужно вручную заполнять пропуски или масштабировать числа для каждого нового примера — пайплайн сделает это сам по заранее утвержденному чертежу.
Допустим мы хотим предсказать, купит ли клиент подписку (0 или 1). У нас есть два признака:
-
Возраст: (маленькие числа, но есть пропуски/NaN).
-
Зарплата: (огромные числа, нужен скейлинг).
Пример профессионального кода c интерактивным вводом новых данных для предсказания:
import numpy as np
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
# --- ЧАСТЬ 1: Обучение (То же, что и раньше) ---
print("⚙️ Обучаем модель...")
X_train = np.array([
[25, 50000], [np.nan, 60000], [35, 90000], [20, 30000], [40, 85000],
[55, 120000], [22, 40000], [30, 70000], [45, 100000], [18, 25000]
])
# 0 - не купил, 1 - купил
y_train = np.array([0, 0, 1, 0, 1, 1, 0, 1, 1, 0])
my_pipeline = Pipeline([
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler()),
('model', SVC())
])
my_pipeline.fit(X_train, y_train)
print("✅ Модель готова к работе!\n")
# --- ЧАСТЬ 2: Интерактивный ввод данных ---
def get_user_input():
print("--- Введите данные нового клиента ---")
print("(Если данные неизвестны, просто нажмите Enter)")
# 1. Спрашиваем Возраст
age_input = input("Введите Возраст: ")
if age_input.strip() == "":
age = np.nan
print(" -> Принято: Возраст неизвестен (будет заполнено средним)")
else:
age = float(age_input)
# 2. Спрашиваем Зарплату
salary_input = input("Введите Зарплату: ")
if salary_input.strip() == "":
salary = np.nan # Да, скейлер сработает, но лучше иметь данные
else:
salary = float(salary_input)
return [[age, salary]] # Возвращаем 2D массив
# Бесконечный цикл опроса
while True:
try:
# Получаем данные от пользователя
user_data = get_user_input()
# Делаем прогноз
prediction = my_pipeline.predict(user_data)
# Красивый вывод
result = "КУПИТ подписку (1)" if prediction[0] == 1 else "НЕ КУПИТ (0)"
print(f"\n🔮 Прогноз модели: Клиент {result}")
print("-" * 30)
if input("Проверить еще одного? (y/n): ").lower() != 'y':
break
except ValueError:
print("❌ Ошибка: Пожалуйста, вводите только числа!")
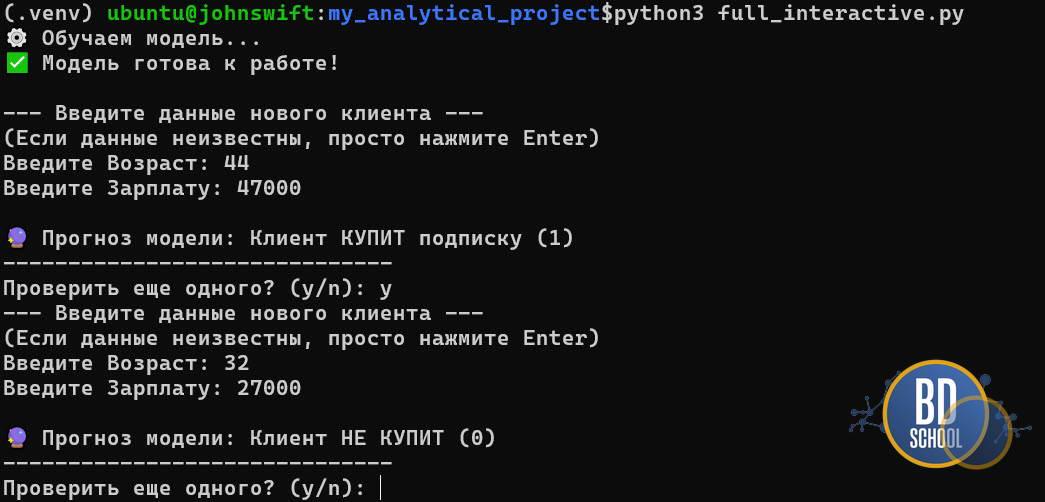
Почему это круто? Без пайплайна тебе пришлось бы хранить где-то отдельно значение среднего возраста, отдельно формулу скейлера и применять их вручную к каждой новой строчке данных. Пайплайн делает код чистым и защищает от ошибок.
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Как выбрать правильный алгоритм в Scikit-Learn?
Новичков часто парализует выбор: «У меня есть SVM, Random Forest, Gradient Boosting, Logistic Regression… Что брать?!».
В Scikit-learn есть знаменитая «шпаргалка» (Cheat Sheet). Но базовое правило большого пальца такое:
- Мало данных (< 100K строк)? Попробуйте SVM или K-Neighbors.
- Нужна интерпретируемость (объяснить боссу, почему отказ)? Берите Logistic Regression или Decision Tree (Дерево решений).
- Нужна максимальная точность на табличных данных? Ваш выбор — Ансамбли (Random Forest, Gradient Boosting).
- Данных ОЧЕНЬ много? Scikit-learn может начать тормозить. Тут стоит смотреть в сторону SGDClassifier (стохастический градиентный спуск) или переходить на специализированные библиотеки типа LightGBM.
Заключение
Scikit-learn — это идеальный тренажер для ума и мощный инструмент для работы. Он не требует от вас быть доктором математических наук, чтобы начать приносить пользу бизнесу.
Главные выводы:
- Данные готовьте заранее (Pandas + Preprocessing).
- Всегда делите выборку на train и test.
- Используйте Pipeline, чтобы не запутаться.
- Начинайте с простых моделей, прежде чем переходить к сложным.
Чтобы закрепить эти знания, очень советую пройти практические задания в нашем курсе Python для Data Mining и ML. Там вы своими руками напишете свой первый классификатор и увидите, как эти абстрактные классы работают с реальными данными.
В следующей статье цикла мы копнем глубже в визуализацию и посмотрим, как красиво представить результаты работы ваших моделей.
Референсные источники
- Scikit-learn: Machine Learning in Python (Official Docs) — библия для разработчика.
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow (Aurélien Géron) —, возможно, лучшая книга по теме.
- Python Data Science Handbook (Jake VanderPlas) — отличный бесплатный ресурс.