 1227
1227 Содержание
SEMMA (аббревиатура от английских слов Sample, Explore, Modify, Model и Assess) – общая методология и последовательность шагов интеллектуального анализа данных (Data Mining), предложенная американской компанией SAS, одним из крупнейших производителей программного обеспечения для статистики и бизнес-аналитики, для своих продуктов [1].
Зачем нужен стандарт SEMMA
В отличие от другого широко используемого стандарта Data Mining, CRISP-DM, SEMMA фокусируется на задачах моделирования, не затрагивая бизнес-аспекты. Тем не менее, этот стандарт позиционируется как унифицированный межотраслевой подход к итеративному процессу интеллектуального анализа данных [1]. Эта методология не навязывает каких-либо жестких правил, однако, используя ее разработчик располагает научными методами построения концепции проекта, его реализации и оценки результатов проектирования [2].Подход SEMMA сочетает структурированность процесса Data Mining и логическую организацию инструментальных средств для поддержки каждой операции обработки и анализу данных. SEMMA включает диаграммы процессов обработки данных, что упрощает применение методов статистического исследования и визуализации, а также позволяет выбирать и преобразовывать наиболее значимые переменные, чтобы создавать с ними модели. Это улучшает предсказание результатов, помогает подтвердить точность модели и подготовить ее к развертыванию [2].
Из чего состоит SEMMA: этапы процесса Data Mining
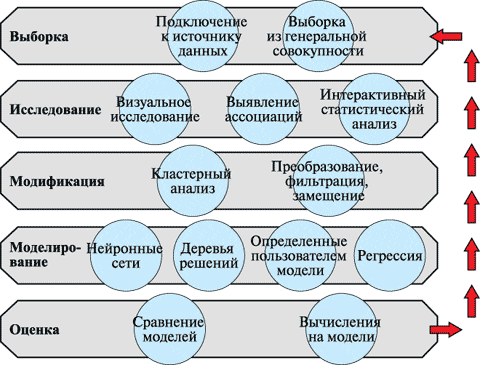
- Выборка данных – формирование начального набора данных для моделирования (dataset), который должен быть достаточно большим, чтобы содержать достаточную информацию для извлечения, и в то же время ограниченным, чтобы его можно было эффективно использовать.
- Исследование – выявление ассоциаций, визуальный и интерактивный статистический анализ, понимание данных путем обнаружения ожидаемых и непредвиденных связей между переменными, а также отклонений с помощью визуализации данных.
- Модификация – применение методов выбора, создания и преобразования переменных при подготовке к моделированию: кластерный анализ, преобразование, фильтрация и замещение информации.
- Моделирование — применение методов построения и обработки моделей интеллектуального анализа данных: искусственные нейронные сети, деревья принятия решений, регрессионный анализ и т.д.
- Оценка – сравнение результатов моделирования между собой и с планируемыми показателями, анализ надежности и полезности созданных моделей.
Области применения стандарта Data Mining: где он используется
На практике эта методология реализована в среде SAS Data Mining Solution – программном пакете американского разработчика программного обеспечения для статистики и бизнес-аналитики SAS. Таким образом, CRISP-DM является наиболее полной и детальной методологией интеллектуального анализа данных, а SEMMA – это структура целевых функций в инструменте SAS Enterprise Miner, которая затрагивает исключительно технические аспекты моделирования, не касаясь бизнес-постановки задачи [3]. Поэтому на практике в большинстве случаев используется именно подход CRISP-DM. Однако, даже этот проработанный стандарт не спасет неопытного аналитика данных от популярных ошибок и проблем.
Источники
- https://en.wikipedia.org/wiki/SEMMA
- https://www.intuit.ru/studies/courses/6/6/lecture/198?page=4
- https://habr.com/ru/company/lanit/blog/328858/