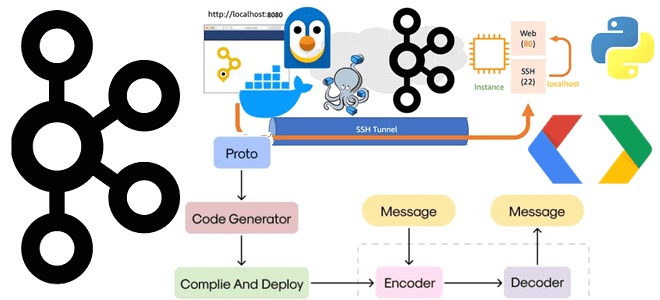
Как публиковать в топик Kafka сообщения в формате Protobuf, используя реестр схем и библиотеку confluent-kafka. Пример Python-продюсера, конфигурационного YAML-файла для Docker-развертывания Kafka Confluent и тунелирование портов локального компьютера. Подготовка инфраструктуры и определение схемы данных Чтобы публиковать в свое Docker-развертывание Kafka Confluent данные, используя реестр схем, нужно сперва внести изменения в...
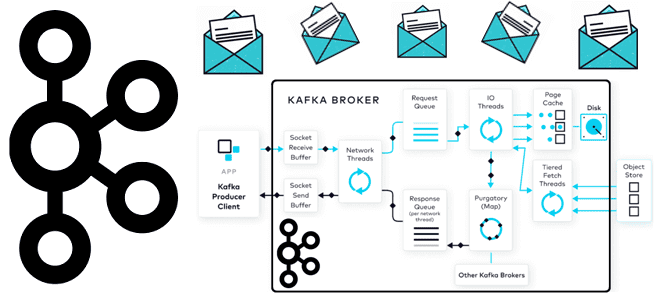
Как данные попадают в топик Kafka: полный путь пакета сообщений от буфера сокета приема до страничного кэша и отправки ответного подтверждения клиенту- продюсеру. Все шаги публикации данных в Apache Kafka Когда разработчик пишет код приложения-продюсера, публикующего данные в Apache Kafka, он использует существующие методы для отправки сообщений, которые есть в...

24 сентября вышел очередной релиз Apache Spark. Он не содержит новых фичей, но зато в нем есть несколько полезных оптимизаций и исправлений безопасности. Читайте далее о самом главном из них, связанном с утечкой токена делегирования Hadoop. Зачем нужны токены делегирования Hadoop в Spark и как они работают В выпуске Apache...

Как устроен планировщик заданий Apache AirFlow, от чего зависит его производительность и какие конфигурации помогут ее улучшить: настройки, приемы, рекомендуемые значения и лучшие практики. Как работает планировщик Apache AirFlow Apache AirFlow как фреймворк оркестрации пакетных процессов включает несколько компонентов. Одним из них является планировщик (scheduler), который отслеживает все задачи и...
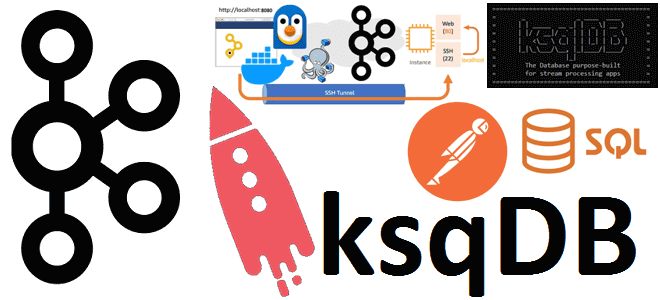
Аналитика данных из топиков Kafka с помощью SQL-запросов: обращение к ksqlDB в Docker через CLI-интерфейс и REST API в Postman с SSH-тунелированием сервера потоковой базы данных. Практическое руководство с примерами и иллюстрациями. CLI-интерфейс ksqldb Docker-образ Confluent Kafka включает дополнительные компоненты этой платформы: ksqlDB, Kafka Connect, REST Proxy, Schema Registry). Сегодня...
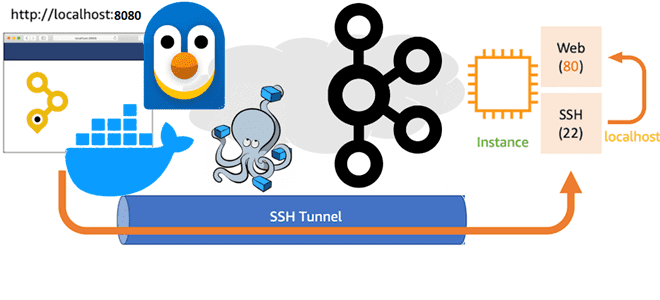
Как туннелировать порты Docker-контейнеров для доступа к Kafka на WSL в Windows с внешнего клиента: переадресация HTTP- и TCP-соединений с помощью SSH-сервера serveo. Поиск средства тунелирования и настройка портов Собственное развертывание платформы Kafka от Confluent в виде набора связанных Docker-контейнеров в WSL на Windows с GUI-интерфейсом AKHQ, о чем я...
Как настроить YAML-файл Docker Compose для доступа к Kafka на WSL в Windows: открытие портов в конфигурации развертывания с примерами (продолжение). Настройка конфигурационного YAML-файла для запуска Docker-контейнеров с компонентами Kafka на Windows в WSL Как я рассказывала вчера, для работы с компонентами платформы Kafka от Confluent, развернутой как набор связанных...

WSL и Docker для локального развертывания Apache Kafka с GUI и всеми компонентами в контейнере: моя реальная история поиска веб-интерфейса и настройки портов (начало). Развертывание Kafka на Windows с Docker в WSL В конце августа 2024 года команда serverless-платформы Upstash, на которой у меня есть рабочий инстанс Apache Kafka, разослала...
Зачем нужна автоматическая очистка таблиц системного каталога Greenplum, почему команда AUTOVACUUM выполняется локально на каждом сегменте и как ее настроить для максимальной эффективности старых кортежей в распределенной базе данных с массовой-параллельной обработкой. Параметры автоматической очистки в Greenplum О том, зачем нужна команда автоочистки в Greenplum и как она работает, мы...
Чем планирование запуска DAG в Apache AirFlow с объектом timedelta отличается от использования cron-выражений, в чем разница CronTriggerTimetable и CronDataIntervalTimetable, а также как создать собственный класс расписания. Объект timedelta vs cron-выражение: задание расписания запуска DAG в Apache AirFlow Apache AirFlow идеально подходит для классических пакетных ETL-сценариев, например, когда надо извлечь...