 1240
1240 
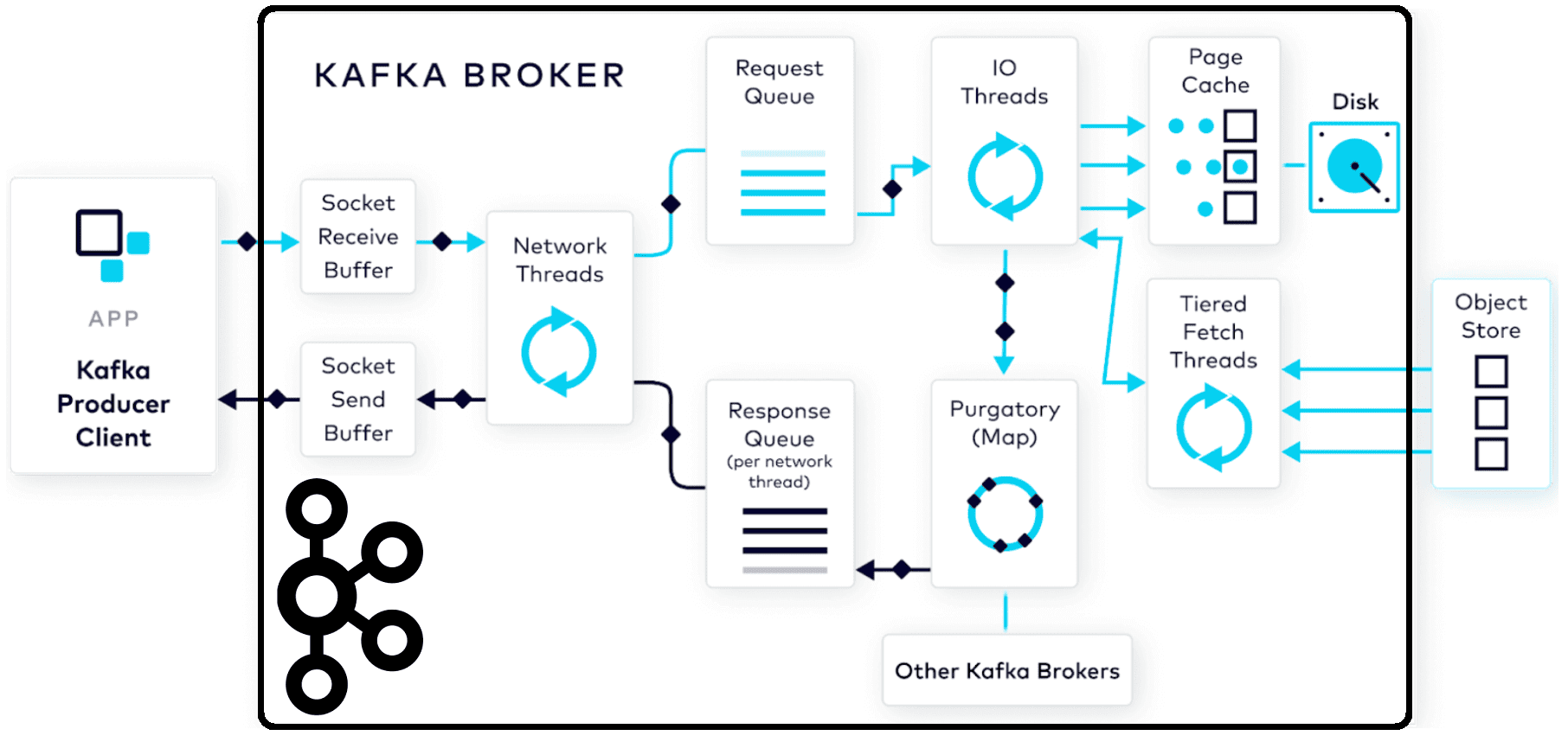
Как данные попадают в топик Kafka: полный путь пакета сообщений от буфера сокета приема до страничного кэша и отправки ответного подтверждения клиенту- продюсеру.
Все шаги публикации данных в Apache Kafka
Когда разработчик пишет код приложения-продюсера, публикующего данные в Apache Kafka, он использует существующие методы для отправки сообщений, которые есть в выбранной библиотеке. Например, в kafka-python это метод send() у объекта класса KafkaProducer, а в confluent-kafka – метод produce() у объекта класса Producer. Однако, за визуальной простотой вызова этих методов скрывается целая последовательность шагов передачи данных из одной системы в другую. На UML-диаграмме sequence мы ее показывали здесь.
Первым этапом для входящих запросов на брокере является буфер сокета приема. Это своего рода зона приземления входящих данных; здесь запрос ожидает, когда его подхватят сетевые потоки для обработки. Потенциально можно задать параметры конфигурации для настройки производительности этого буфера, такие как размер общего буфера socket.receive.buffer.bytes и максимальный размер входящего запроса socket.request.max.bytes. Однако, вручную это делается довольно редко, поскольку значения по умолчанию подходят для абсолютного большинства сценариев.
После короткого пребывания в буфере сокета приема запрос подхватывается доступным сетевым потоком из пула. Сетевой поток, который подхватывает входящий запрос, будет обрабатывать его в течение всего его жизненного цикла. Сперва сетевой поток должен прочитать запрос из буфера сокета приема, сформировать его в объект запроса produce и добавить его в очередь запросов. Конфигурация num.network.threads определяет, сколько сетевых потоков будет работать в этот момент. По умолчанию она равна 3, а верхняя граница обычно соответствует количеству ядер, доступных на сервере. Отслеживать эти потоки поможет метрика NetworkProcessorAvgIdlePercent, значения которой варьируются от 0, когда потоки полностью загружены до 1, т.е. потоки не заняты. Желательно, чтобы значение метрики NetworkProcessorAvgIdlePercent было ближе к 1, когда потоки не слишком загружены.
Далее запрос ожидает дальнейшей обработки потоками ввода-вывода сервера в очереди запросов. На этом этапе можно контролировать количество запросов через конфигурацию queued.max.requests и максимальный размер запросов queued.max.request.bytes. Можно ограничить queued.max.requests количеством активных клиентов, которые есть, чтобы обеспечить строгий порядок сообщений. Чтобы контролировать размер очереди запросов, а также количество времени, в течение которого запрос находится в очереди, используются метрики RequestQueueSize и RequestQueueTimeMs соответственно. Эти метрики позволяют отследить, как работают потоки ввода-вывода, а также перегружен ли брокер Kafka. Рекомендуется следить за этими двумя метриками, поскольку заполненная очередь запросов заблокируется, и не позволит сетевым потокам добавлять в нее новые запросы.
Запрос извлекается из очереди запросов доступным потоком ввода-вывода, т.е. потоком обработчика запросов. Когда этот поток обращается к запросу, его первой задачей является проверка данных, содержащихся в нем, с помощью циклической проверки избыточности. Это дополнительный механизм, гарантирующий, что целостность данных не была случайно нарушена во время передачи байтов.
Потоки ввода-вывода выполняют довольно много работы по обработке данных и записи их на диск. Их количество можно настроить с помощью конфигурации num.io.threads, по умолчанию равной 8. Отслеживать работу потоков можно с помощью метрики RequestHandlerAvgIdlePercent. По аналогии с NetworkProcessorAvgIdlePercent, значение RequestHandlerAvgIdlePercent должно быть ближе к 1, когда потоки не чрезмерно загружены. Значение около 0 означает, что потоки редко простаивают и работают усердно.
Наконец, данные могут быть записаны на диск, что также выполняют потоки ввода-вывода. Напомним, данные в Kafka хранятся в логах, которые состоят из сегментов. Каждый сегмент состоит из пары файлов:
- файл .log, который содержит фактические данные о событиях, необработанные байты, которые надо сохранить;
- файл .index, где хранится структура индекса, которая сопоставляет смещение записи с позицией этой записи в соответствующем файле .log;
- файл .timeindex нужен для доступа к записям с использованием смещений на основе времени, что используется в сценариях аварийного восстановления для потребителей.
- файл .snapshot хранит порядковые номера продюсеров, что позволяет организовать идемпотентность.
Разумеется, потоки ввода-вывода не могут сразу записать данные во все эти файлы, а записывают события в файлы .log и .index. Обновления происходят в страничном кэше операционной системы, а потом сбрасываются на диск в зависимости от настроенных параметров ядра vm.dirty_ratio, vm.dirty_background_ratio и vm.swappiness. Это называется Zero-copy когда ЦП не копирует данные из одной области памяти в другую, а работает с прямым доступом к памяти (DMA, direct memory access) и отображением в памяти (memory mapping), а также со страничным кэшем. Kafka использует эту технологию, чтобы обеспечить высокую скорость операций записи на диск и чтения данных. Подробнее об этом мы писали здесь.
Kafka не использует системный вызов fsync(), который копирует на диск все части файла, находящиеся в памяти и ожидает, пока устройство сообщит, что все эти части сохранены. Протокол репликации данных Kafka был разработан так, чтобы быть безопасным без системного вызова fsync, который синхронизирует файл с хранилищем. Отсутствие таких низкоуровневых функций позволяет контролировать периодичность сброса файлов на диск с помощью следующих конфигураций:
- flush.interval.ms – временной предел для того, как часто файл .log сбрасывается на диск;
- flush.interval.messages – количество сообщений, которые можно записать в файл .log, прежде чем файл будет сброшен на диск;
- segment.bytes – максимальный размер файла .log, прежде чем файлы перейдут в следующий сегмент.
Некоторые конфигурации можно переопределить на уровне топика, например, политика очистки cleanup.policy, которая может принимать значения delete и compact. Первое означает, что старые записи журнала будут удалены по истечении указанного времени или при превышении порогового значения размера файла. При сжатии сообщений по крайней мере одно значение для каждого ключа будет сохранено со старыми записями для удаляемого ключа. Подробно это мы разбирали здесь.
Отслеживать, как логи сбрасываются на диск, поможет метрика LogFlushRateAndTimeMs и метрика LocalTimeMs, которая представляет собой разницу времени между тем, когда потоки ввода-вывода получают запрос, и записью данных в страничный кэш.
Пока данные не будут реплицированы на все брокеры согласно заданному фактору репликации, запросы на публикацию хранятся в специальной структуре данных брокера. Каждый брокер-лидер, в котором висит запрос, ждет, пока брокеры-подписчики запросят данные и обновят свои копии. Каждый брокер знает, какие из его разделов являются репликами, и какие брокеры в кластере являются лидерами, т.е. владеют первичными данными для этих реплик. По умолчанию брокеры-подписчики извлекают эту информацию каждые 500 мс, но этот период можно настроить с помощью конфигурации replica.fetch.wait.max.ms. Также можно настроить, сколько потоков брокеры-подписчики выделяют на выборку данных, используя num.replica.fetchers. Отслеживать, сколько времени занимает процесс репликации поможет метрика RemoteTimeMs.
После того, как квота подтверждений публикации данных acks первоначального запроса будет выполнена, брокер выведет запрос из режима ожидания и начнет формировать ответ для отправки обратно клиенту-продюсеру. Напомним, если acks = all, ожидаются подтверждения об успешной публикации данных по всем брокерам-подписчикам. А при acks = 0 не ожидается ни одного подтверждения.
Отслеживать очередь ответов можно через метрику количества ответов в очереди ResponseQueueSize и время, проведенное в ней ResponseQueueTimeMS. Как только ответ готов к отправке, из очереди ответов он возвращается к сетевому потоку, тому же самому, который принял первоначальный запрос. Этот сетевой поток получает сгенерированный объекта ответа и отправляет его обратно клиенту-продюсеру. Исходящий ответ помещается в буфер сокета отправки для ожидания получения продюсером. Фактически, брокер будет ждать, пока весь ответ не будет получен продюсером. С помощью конфигурации socket.send.buffer.bytes можно контролировать общий размер этого буфера. Отслеживать, сколько времени занимает этот процесс отправки можно с помощью метрики ResponseSendTimeMs.
Получив ответ, продюсер закроет все таймеры и соберет метрики по запросу, например, TotalTimeMs поможет узнать, сколько времени заняла обработка всего запроса. Если данные были успешно опубликованы в Kafka, т.е. сохранены в нужном количестве реплик, клиент-продюсер выполнит очистит пакет, который временно хранился в его буферной памяти. Если данные не были успешно опубликованы, продюсер может отправить их повторно, согласно заданной конфигурации с количеством повторных попыток.
Научитесь администрированию и эксплуатации Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
Источники

