678
678 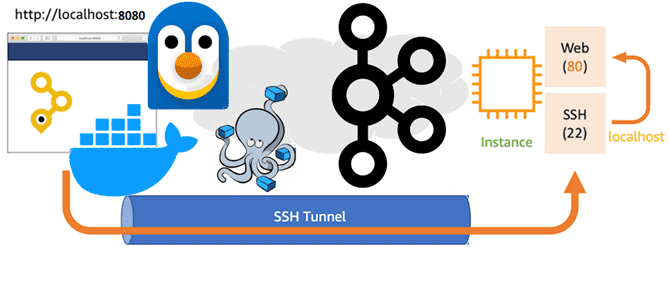
Как туннелировать порты Docker-контейнеров для доступа к Kafka на WSL в Windows с внешнего клиента: переадресация HTTP- и TCP-соединений с помощью SSH-сервера serveo.
Поиск средства тунелирования и настройка портов
Собственное развертывание платформы Kafka от Confluent в виде набора связанных Docker-контейнеров в WSL на Windows с GUI-интерфейсом AKHQ, о чем я писала здесь и здесь, нужно мне не только для исследовательских задач. Чтобы получить бесплатный и рабочий стенд для студентов моих курсов по архитектуре информационных систем в Школе прикладного бизнес-анализа и проектирования, нужно организовать доступ этому набору сервисов извне. Эта задача решается с помощью проброски SSH-тунеля. SSH-тунель позволяет обращаться к сервисам, запущенным на локальной машине, с внешних устройств. Таким образом, необходимо найти подходящий инструмент тунелирования, туннелировать localhost:8080, где развернуто веб-приложение AKHQ и localhost:29092 – сокет, по которому доступен брокер Kafka, развернутый в Docker-контейнере. На практике это оказалось не так просто.
Сперва пришлось потратить время на поиск подходящего инструмента тунелирования. Утилиту ngrok, которую я раньше использовала, в этот раз решила не брать, поскольку последнее время у новых пользователей из РФ с ней стали возникать трудности. Отечественный xTunnel, который отлично туннелирует HTTP-трафик для простых веб-приложений, не очень хорошо показал себя в работе с TCP, поэтому от него я тоже отказалась. Требований к утилите тунелирования у меня было немного:
- поддержка HTTP- и TCP-трафика;
- кроссплатформенность, чтобы запускать в Linux-подобной WSL, так и в Windows;
- возможность работы из РФ;
- наличие бесплатного тарифа;
- постоянный URL-адрес на открываемый порт;
- отсутствие ограничений на количество открытых портов и передаваемый трафик;
- простая процедуры регистрации или вообще ее полное отсутствия.
Все это позволяет сделать сервис Serveo — SSH-сервер для удаленной переадресации портов. Serveo генерирует публичный URL, который можно использовать для подключения к сервису, работающему на локальном хосте. Примечательно, что Serveo не требует установки и регистрации, а работает как утилита командной строки.
После запуска Docker-контейнеров c компонентами платформы Kafka согласно конфигурации, в YAML-файле docker-compose.yml, содержимое которого я приводила здесь, сперва туннелировала 80-тый порт, на котором запущен GUI-интерфейс AKHQ. Для удобства я решила сделать постоянный и красивый URL-адрес kafka.serveo.net, генерируемый Serveo. Для этого пришлось создать пару ключей SSH с помощью команды ssh-keygen и зарегистрировать их через аккаунт на Github.
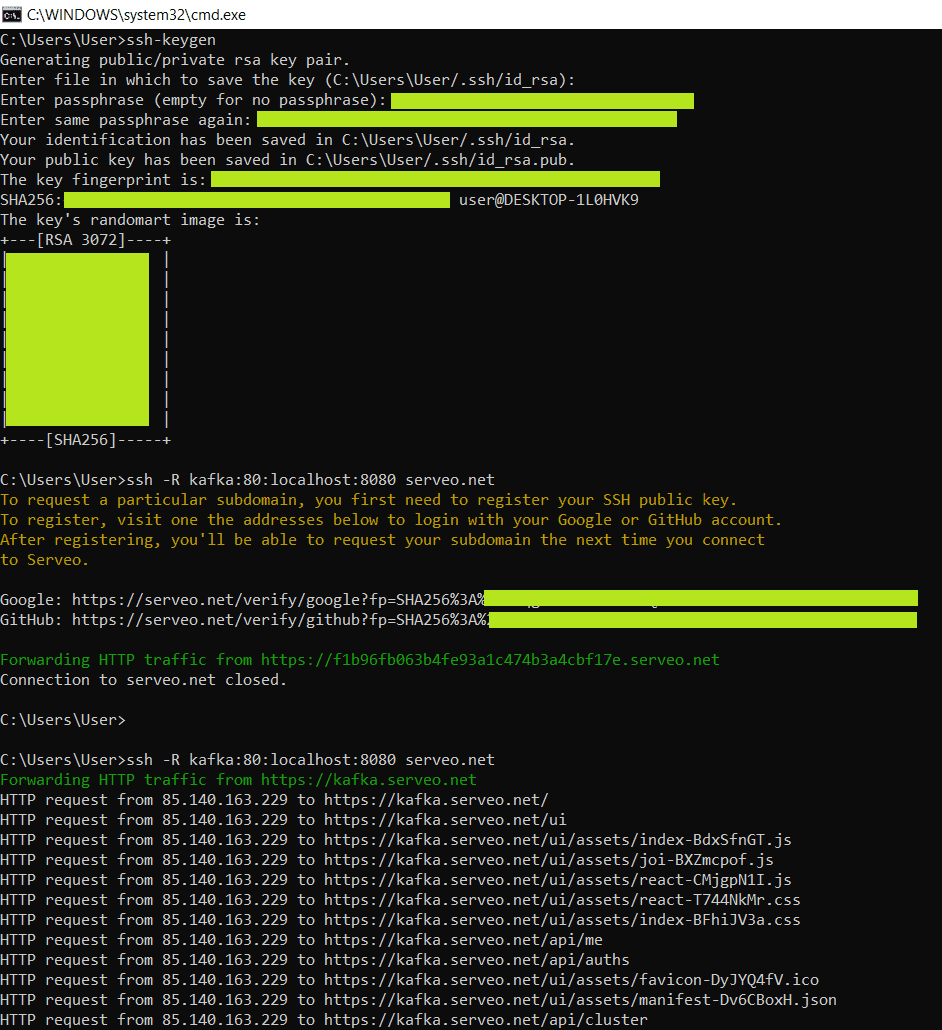
После этого можно с любого внешнего устройства получить доступ к AKHQ, развернутом в Docker-контейнере на моей локальной машине, набрав в браузере URL-адрес kafka.serveo.net. Естественно, все Docker-контейнеры при этом должны быть запущены, а нужные порты – открыты. Еще нужно тунелировать TCP-порт на локальной машине, также с помощью SSH:
ssh -R 39092:localhost:39092 serveo.net
После этого можно с любого внешнего устройства получить доступ к AKHQ, развернутом в Docker-контейнере на моей локальной машине, набрав в браузере URL-адрес kafka.serveo.net. Естественно, все Docker-контейнеры при этом должны быть запущены, а нужные порты – открыты.
Чтобы сделать порт, на котором работает брокер Kafka, доступным извне, надо внести соответствующие изменения в конфигурационный YAML-файл docker-compose.yml, по которому собираются контейнеры. Поскольку Serveo является полноценным SSH-сервером, его можно указать как внешний хост в конфигурации слушателей Kafka. О том, что это такое и почему их необходимо настроить, я рассказывала вчера. На UML-диаграмме развертывания это выглядит так:
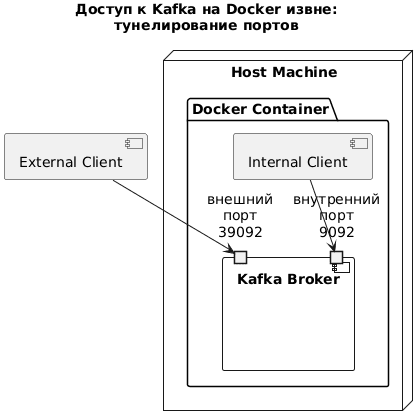
Скрипт PlantUML для этой диаграммы
@startuml
title Доступ к Kafka на Docker извне:\nтунелирование портов
node "Host Machine" {
package "Docker Container" {
component "Kafka Broker" as KB {
portin "внутренний\nпорт\n9092" as 9092
portin "внешний\nпорт\n39092" as 39092
}
[Internal Client] --> 9092
}
}
[External Client] --> 39092
@enduml
Для открытия доступа к порту 9092 извне в файл docker-compose.yml пришлось внести следующие изменения:
- KAFKA_ADVERTISED_LISTENERS: ‘PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092,PLAINTEXT_EXT://serveo.net:39092’
- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: ‘PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT,PLAINTEXT_EXT:PLAINTEXT’
- ports: — 39092:39092
Я добавила внешний порт 39092 в конфигурации KAFKA_ADVERTISED_LISTENERS, а также прописала его сопоставление с локальным (в пределах Docker-контейнера) портом 9092 в конфигурации KAFKA_LISTENER_SECURITY_PROTOCOL_MAP. К сожалению, в конфигурации ports нельзя указать сразу несколько портов. Так можно было бы попеременно работать то с локальной машины, то извне без пересборки контейнеров. Таким образом, YAML-файл docker-compose.yml выглядит так:
version: '3.6'
volumes:
zookeeper-data:
driver: local
zookeeper-log:
driver: local
kafka-data:
driver: local
services:
akhq:
# build:
# context: .
image: tchiotludo/akhq
restart: unless-stopped
environment:
AKHQ_CONFIGURATION: |
akhq:
connections:
docker-kafka-server:
properties:
bootstrap.servers: "kafka:9092"
schema-registry:
url: "http://schema-registry:8085"
connect:
- name: "connect"
url: "http://connect:8083"
ports:
- 8080:8080
links:
- kafka
- schema-registry
zookeeper:
image: confluentinc/cp-zookeeper:7.5.0
restart: unless-stopped
ports:
- 2181:2181
volumes:
- zookeeper-data:/var/lib/zookeeper/data:Z
- zookeeper-log:/var/lib/zookeeper/log:Z
environment:
ZOOKEEPER_CLIENT_PORT: '2181'
ZOOKEEPER_ADMIN_ENABLE_SERVER: 'false'
kafka:
image: confluentinc/cp-kafka:7.5.0
restart: unless-stopped
volumes:
- kafka-data:/var/lib/kafka/data:Z
environment:
KAFKA_BROKER_ID: '0'
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_NUM_PARTITIONS: '12'
KAFKA_COMPRESSION_TYPE: 'gzip'
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: '1'
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: '1'
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: '1'
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092,PLAINTEXT_EXT://serveo.net:39092'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 'PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT,PLAINTEXT_EXT:PLAINTEXT'
KAFKA_CONFLUENT_SUPPORT_METRICS_ENABLE: 'false'
KAFKA_JMX_PORT: '9091'
KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'true'
KAFKA_AUTHORIZER_CLASS_NAME: 'kafka.security.authorizer.AclAuthorizer'
KAFKA_ALLOW_EVERYONE_IF_NO_ACL_FOUND: 'true'
ports:
- 39092:39092
links:
- zookeeper
schema-registry:
image: confluentinc/cp-schema-registry:7.5.0
restart: unless-stopped
depends_on:
- kafka
ports:
- 8081:8081
environment:
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'PLAINTEXT://kafka:9092'
SCHEMA_REGISTRY_HOST_NAME: 'schema-registry'
SCHEMA_REGISTRY_LISTENERS: 'http://0.0.0.0:8085'
SCHEMA_REGISTRY_LOG4J_ROOT_LOGLEVEL: 'INFO'
connect:
image: confluentinc/cp-kafka-connect:7.5.0
restart: unless-stopped
depends_on:
- kafka
- schema-registry
ports:
- 8083:8083
environment:
CONNECT_BOOTSTRAP_SERVERS: 'kafka:9092'
CONNECT_REST_PORT: '8083'
CONNECT_REST_LISTENERS: 'http://0.0.0.0:8083'
CONNECT_REST_ADVERTISED_HOST_NAME: 'connect'
CONNECT_CONFIG_STORAGE_TOPIC: '__connect-config'
CONNECT_OFFSET_STORAGE_TOPIC: '__connect-offsets'
CONNECT_STATUS_STORAGE_TOPIC: '__connect-status'
CONNECT_GROUP_ID: 'kafka-connect'
CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE: 'true'
CONNECT_KEY_CONVERTER: 'io.confluent.connect.avro.AvroConverter'
CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry:8085'
CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE: 'true'
CONNECT_VALUE_CONVERTER: 'io.confluent.connect.avro.AvroConverter'
CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry:8085'
CONNECT_INTERNAL_KEY_CONVERTER: 'org.apache.kafka.connect.json.JsonConverter'
CONNECT_INTERNAL_VALUE_CONVERTER: 'org.apache.kafka.connect.json.JsonConverter'
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: '1'
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: '1'
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: '1'
CONNECT_PLUGIN_PATH: ' /usr/share/java/'
ksqldb:
image: confluentinc/cp-ksqldb-server:7.5.0
restart: unless-stopped
depends_on:
- kafka
- connect
- schema-registry
ports:
- 8088:8088
environment:
KSQL_BOOTSTRAP_SERVERS: 'kafka:9092'
KSQL_LISTENERS: 'http://0.0.0.0:8088'
KSQL_KSQL_SERVICE_ID: 'ksql'
KSQL_KSQL_SCHEMA_REGISTRY_URL: 'http://schema-registry:8085'
KSQL_KSQL_CONNECT_URL: 'http://connect:8083'
KSQL_KSQL_SINK_PARTITIONS: '1'
KSQL_KSQL_LOGGING_PROCESSING_TOPIC_REPLICATION_FACTOR: '1'
test-data:
image: gradle:8-jdk11
command: "gradle --no-daemon testInjectData -x installFrontend -x assembleFrontend"
restart: unless-stopped
working_dir: /app
volumes:
- ./:/app:z
links:
- kafka
- schema-registry
kafkacat:
image: confluentinc/cp-kafkacat:7.1.14
restart: unless-stopped
depends_on:
- kafka
command:
- bash
- -c
- |
kafkacat -P -b kafka:9092 -t json << EOF
{"_id":"5c4b2b45ab234c86955f0802","index":0,"guid":"d3637b06-9940-4958-9f82-639001c14c34"}
{"_id":"5c4b2b459ffa9bb0c0c249e1","index":1,"guid":"08612fb5-40a7-45e5-9ff2-beb89a1b2835"}
{"_id":"5c4b2b4545d7cbc7bf8b6e3e","index":2,"guid":"4880280a-cf8b-4884-881e-7b64ebf2afd0"}
{"_id":"5c4b2b45dab381e6b3024c6d","index":3,"guid":"36d04c26-0dae-4a8e-a66e-bde9b3b6a745"}
{"_id":"5c4b2b45d1103ce30dfe1947","index":4,"guid":"14d53f2c-def3-406f-9dfb-c29963fdc37e"}
{"_id":"5c4b2b45d6d3b5c51d3dacb7","index":5,"guid":"a20cfc3a-934a-4b93-9a03-008ec651b5a4"}
EOF
kafkacat -P -b kafka:9092 -t csv << EOF
1,Sauncho,Attfield,sattfield0@netlog.com,Male,221.119.13.246
2,Luci,Harp,lharp1@wufoo.com,Female,161.14.184.150
3,Hanna,McQuillan,hmcquillan2@mozilla.com,Female,214.67.74.80
4,Melba,Lecky,mlecky3@uiuc.edu,Female,158.112.18.189
5,Mordecai,Hurdiss,mhurdiss4@rambler.ru,Male,175.123.45.143
EOF
kafkacat -b kafka:9092 -o beginning -G json-consumer json
links:
- kafka
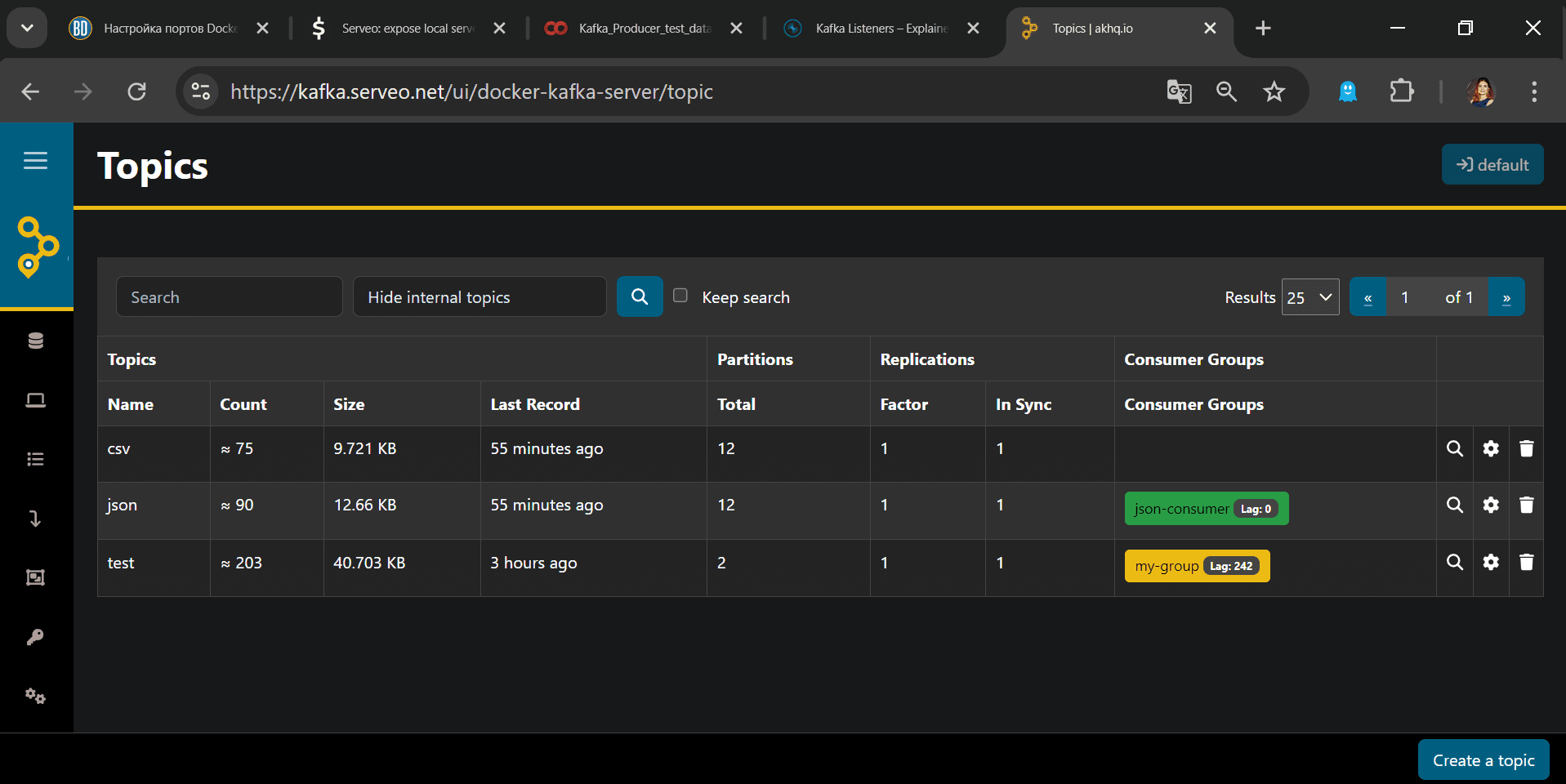
Чтобы проверить, что все порты успешно туннелированы, далее рассмотрим публикацию сообщений в Kafka с помощью внешнего сервиса.
Доступ к Kafka на Docker-контейнере извне
В качестве примера внешнего сервиса возьмем запуск Python-скрипта в интерактивной среде Google Colab. Предположим, надо проимитировать поток событий пользовательского поведения на веб-сайтах (click, scroll, submit, download, focus). В бесконечном цикле каждые 3 секунды создаются и отправляются случайные события в Kafka: пользователь, веб-страница и событие.
#импорт модулей
import json
import random
from datetime import datetime
import time
from time import sleep
from kafka import KafkaProducer
import logging
from faker import Faker
from faker.providers.person.ru_RU import Provider
kafka_url="serveo.net:39092"
# объявление продюсера Kafka
producer = KafkaProducer(
bootstrap_servers=[kafka_url],
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
batch_size=16384, # увеличиваем размер батча
linger_ms=5000, # увеличиваем время ожидания перед отправкой батча
retries=5 # увеличиваем количество попыток
)
topic = 'test'
# Создание объекта Faker
fake = Faker()
# списки веб-страниц
k = 100 # количество веб-страниц
pages = [fake.url() for _ in range(k)]
# списки пользователей
u = 1000 # количество пользователей
users = [fake.ascii_free_email() for _ in range(u)]
# списки событий
events = ['click', 'scroll', 'submit', 'download', 'focus']
# бесконечный цикл публикации данных
while True:
try:
# подготовка данных для публикации в JSON-формате
now = datetime.now()
event_timestamp = now.strftime("%Y-%m-%d %H:%M:%S")
user = random.choice(users)
page = random.choice(pages)
event = random.choice(events)
# Создаем полезную нагрузку в JSON
data = {"event_timestamp": event_timestamp, "user": user, "page": page, "event": event}
#print(data)
# публикуем данные в Kafka
future = producer.send(topic, value=data)
record_metadata = future.get(timeout=60)
print(f' [x] Sent {record_metadata}')
print(f' [x] Payload {data}')
except Exception as e:
print(f'Error: {e}')
# повтор через 3 секунды
time.sleep(3)
Скрипт успешно выполняет публикацию данных: события отправляются в Kafka.
Просмотреть содержимое отправленных сообщений можно в веб-интерфейсе Kafka.
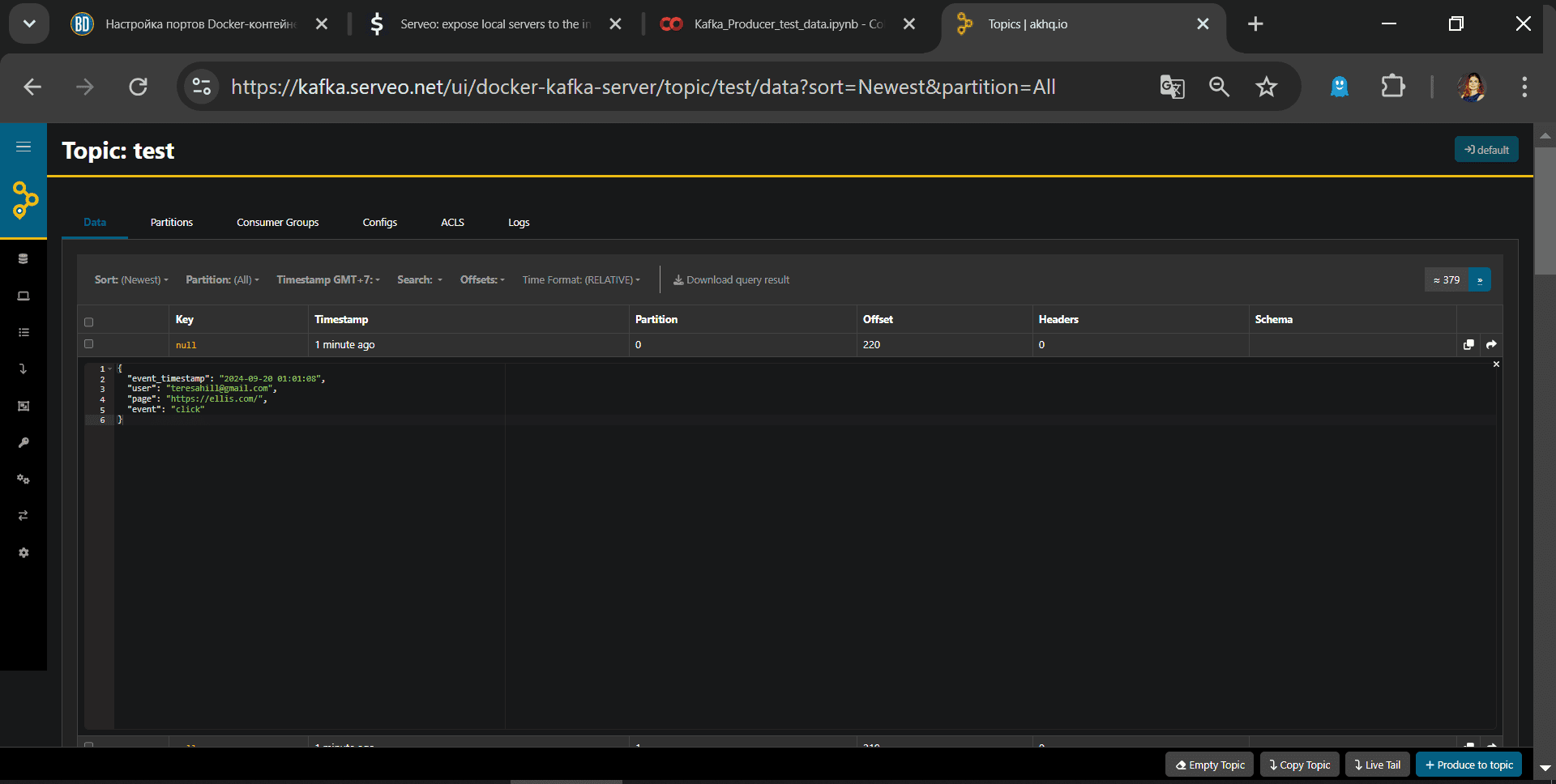
Таким образом, тунелирование успешно работает. Завтра я продолжу работу с созданным стендом и покажу аналитические запросы к данным в топике с помощью ksqlDB.
Научитесь администрированию и эксплуатации Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
Источники: