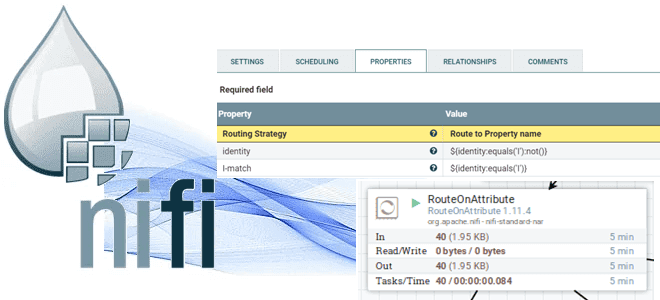
Что такое атрибуты FlowFile, какие процессоры есть в Apache NiFi для работы с ними и как маршрутизировать поток данных на основе пользовательских свойств. Атрибуты FlowFile и процессоры для работы с ними Основной единицей данных, которая перемещается через систему в Apache NiFi является FlowFile. Он представляет собой контейнер для данных и...
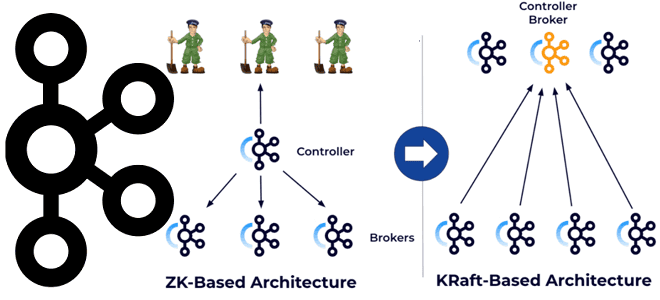
Как перевести кластер Kafka с ZooKeeper на KRaft, чтобы обеспечить управление метаданными с помощью этого протокола консенсуса: последовательность действий и настройки конфигураций. Зачем и как переводить Apache Kafka с Zookeeper на KRaft Напомним, протокол KRaft, который заменяет ZooKeeper для управления метаданными и консенсуса кластера Kafka, был введен еще в версии...

Зачем в Apache Flink 1.20 добавлена новая функция восстановления пакетных заданий после сбоя JobMaster, как она работает и какие параметры надо настроить для повышения ее эффективности. Восстановление пакетных заданий Flink после сбоя JobMaster Как и любой фреймворк стека Big Data, Apache Flink включает множество компонентов, каждый из которых выполняет конкретную...
Что такое Chdb, зачем нужна эта библиотека и как ее использовать в коде Python-приложения для анализа больших данных в ClickHouse без разворачивания полноценного сервера этой колоночной СУБД. Как и зачем работать с ClickHouse без сервера СУБД ClickHouse является мощным инструментом аналитики больших данных, который требует соответствующей инфраструктуры. Однако, иногда нужно...
Что такое волатильные функции, зачем они нужны и чем опасны: разбираем на примере Greenplum и PostgreSQL. К чему приведет некорректное использование атрибутов изменчивости в SQL-запросе или UDF-функции распределенной MPP-СУБД. Что такое волатильность функции и почему это важно для Greenplum Волатильной или изменчивой считается функция, значение которой может изменяться даже в...

Зачем включать ротацию лог-файлов потоковых приложений Apache Spark, какие конфигурации помогут ее настроить и для чего сжимать файлы журналов в длительных заданиях. Чем полезна ротация лог-файлов Spark-приложений и как ее настроить Об общих принципах логирования системных событий в приложениях Apache Spark мы уже рассказывали здесь. В этой статье подробнее разберем...

Что не так с работой Apache AirFlow в многопользовательской среде, зачем предоставлять каждой команде свое развертывание ETL-фреймворка, каковы недостатки этого решения и как организовать мультитенантный кластер. Почему Apache Airflow не предназначен для многопользовательского использования В современной дата-инженерии Apache AirFlow стал наиболее популярным инструментом для пакетных ETL-процессов. Чтобы использовать его наиболее...

Чем объектное хранилище данных отличается от классической файловой системы POSIX, как это влияет на разработку Spark-приложений, почему операция переименования снижает производительность облачных вычислений и что поможет ее избежать. Еще раз об отличиях объектных и файловых хранилищ и как это влияет на приложения Spark Будучи компонентом экосистемы Apache Hadoop, фреймворк Spark...
Что такое хранилище признаков, зачем это нужно в машинном обучении, каковы его главные компоненты и как использовать ClickHouse в качестве Feature Store для ML-задач. Хранилище признаков для машинного обучения: архитектура и принципы работы Feature Store Будучи колоночной базой данных, ClickHouse отлично подходит на роль хранилища фичей (Feature Store) для задач...
Что такое дополнительный выходной поток DataStream в Apache Flink, зачем это нужно, чем механизм SideOutput лучше операторов filter и split, а также как его использовать: примеры на Python. Что такое дополнительный выходной поток DataStream в Apache Flink и зачем это нужно Хотя выходные результаты большинства операторов API DataStream в Apache...