Аналитика данных из топиков Kafka с помощью SQL-запросов: обращение к ksqlDB в Docker через CLI-интерфейс и REST API в Postman с SSH-тунелированием сервера потоковой базы данных. Практическое руководство с примерами и иллюстрациями.
CLI-интерфейс ksqldb
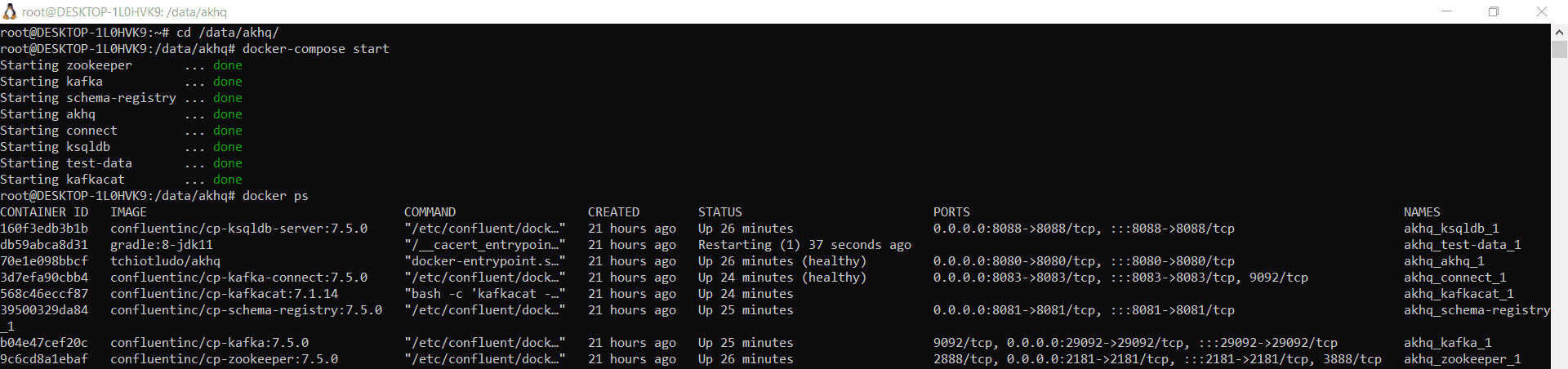
Docker-образ Confluent Kafka включает дополнительные компоненты этой платформы: ksqlDB, Kafka Connect, REST Proxy, Schema Registry). Сегодня я покажу, как работать с ksqlDB – базой данных для потоковой обработки сообщений в топиках Kafka с помощью SQL-запросов. После запуска Docker-контейнеров с Kafka и другими компонентами в WSL на Windows, о чем я писала здесь и здесь, запустим публикацию сообщений в топик и обработаем их через SQL-запросы.
Согласно моему конфигурационному YAML-файлу развертывания докеризированных сервисов, сервер ksqlDB работает на localhost:8088. Для выполнения запросов к ksqlDB потребуется консольный интерфейс ksqlDB или веб-интерфейс. В коммерческую лицензию Confluent Kafka входит Cofluent Command Center, который позволяет работать с ksqlDB. В community-версии, которую я использую, такого GUI нет. AKHQ работает только с самой Kafka и Kafka Connect, не поддерживая ksqlDB. Искать и дополнительно настраивать новый GUI мне не хотелось, поэтому решила обойтись CLI и Postman для обращения к REST API потоковой базы данных.
Для выполнения операций с данными в топиках Kafka через ksqlDB сперва в этой БД нужно создать поток (stream), который будет потреблять данные из нужного топика. После этого можно использовать этот поток для выполнения SQL-запросов. Чтобы запустить CLI-интерфейс ksqlDB, нужно подключиться к серверу в shell- или bash-оболочке. Поскольку я использую Docker в WSL, нужно запустить CLI в работающем Docker-контейнере. Для этого надо выполнить команду
docker exec –it
где
- docker exec указывает Docker на выполнение команды в активном контейнере;
- -i — флаг интерактивного режима, который позволяет поддерживать стандартный ввод (stdin) открытым, чтобы взаимодействовать с процессом в контейнере;
- -t — флаг псевдотерминала, который обеспечивает терминал для сессии, обеспечивая читабельный вывод и позволяя форматировать текст.
Таким образом, чтобы запустить CLI-интерфейс ksqlDB в Docker, надо выполнить команду
docker exec -it <ksqldb-server-container-id> ksql http://localhost:8088
<ksqldb-server-container-id> — это идентификатор контейнера с ksqlDB-сервером. Посмотреть его значение можно, выполнив команду
docker ps
После выполнения команды
docker exec -it <ksqldb-server-container-id> ksql http://localhost:8088
откроется CLI-интерфейс ksqlDB, где можно создать поток для обращения к данным в топике Kafka.
Поскольку данные у меня в формате JSON публикуются в топик под названием test, DDL-запрос создания потока в ksqlDB будет таким:
CREATE STREAM test_stream (
event_timestamp VARCHAR,
user VARCHAR,
page VARCHAR,
event VARCHAR
) WITH (
KAFKA_TOPIC='test',
VALUE_FORMAT='JSON'
);
После этого можно обращаться к этим данным. Например, посчитаем количество событий разного типа, выполнив запрос с группировкой по полю event:
SELECT event, COUNT(*) AS event_count FROM test_stream GROUP BY event EMIT CHANGES;
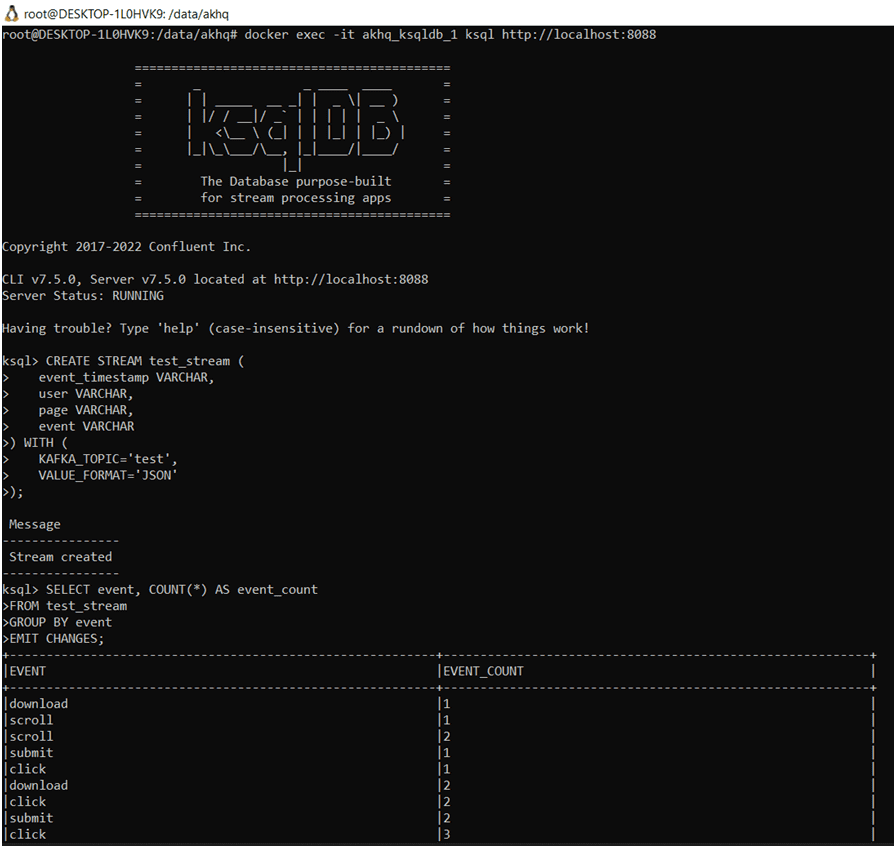 Запуск CLI-интерфейса ksqlDB в WSLВ SELECT-запросе потоковой обработки данных используется оператор EMIT CHANGES, который указывает на постоянное уточнение результатов, поскольку данные меняются постоянно, а не статичны. Это означает, что каждый раз при поступлении новых данных в поток test_stream, результат запроса будет обновляться и выводить изменения.
Запуск CLI-интерфейса ksqlDB в WSLВ SELECT-запросе потоковой обработки данных используется оператор EMIT CHANGES, который указывает на постоянное уточнение результатов, поскольку данные меняются постоянно, а не статичны. Это означает, что каждый раз при поступлении новых данных в поток test_stream, результат запроса будет обновляться и выводить изменения.
Помимо CLI-интерфейса, ksqlDB также имеет REST API, в т.ч. для выполнения SQL-запросов. Как это сделать, рассмотрим далее.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
2 июня, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
HTTP-запросы к REST API потоковой базы данных платформы Kafka Confluent
Конечной точкой HTTP API по умолчанию является http://0.0.0.0:8088/. Однако, чтобы обратиться к этому URL-адресу извне, например, из облачной службы Postman – интерфейса тестирования REST API, надо туннелировать порт 8088. Можно, конечно, запустить Postman локально, но он потребляет очень много ресурсов. Поэтому я обычно использую облачную службу. Для тунелирования порта на локальной машине, как и в прошлый раз, буду использовать SSH-сервер Serveo. Он не только формирует URL-адрес для обращения к службе на локальном хосте извне, но и дает возможность сделать его запоминающимся, как собственный поддомен Serveo. Например, для ksqlDB я решила зарегистрировать URL-адрес ksqldb.serveo.net, выполнив команду
ssh -R ksqldb:80:localhost:8088 serveo.net
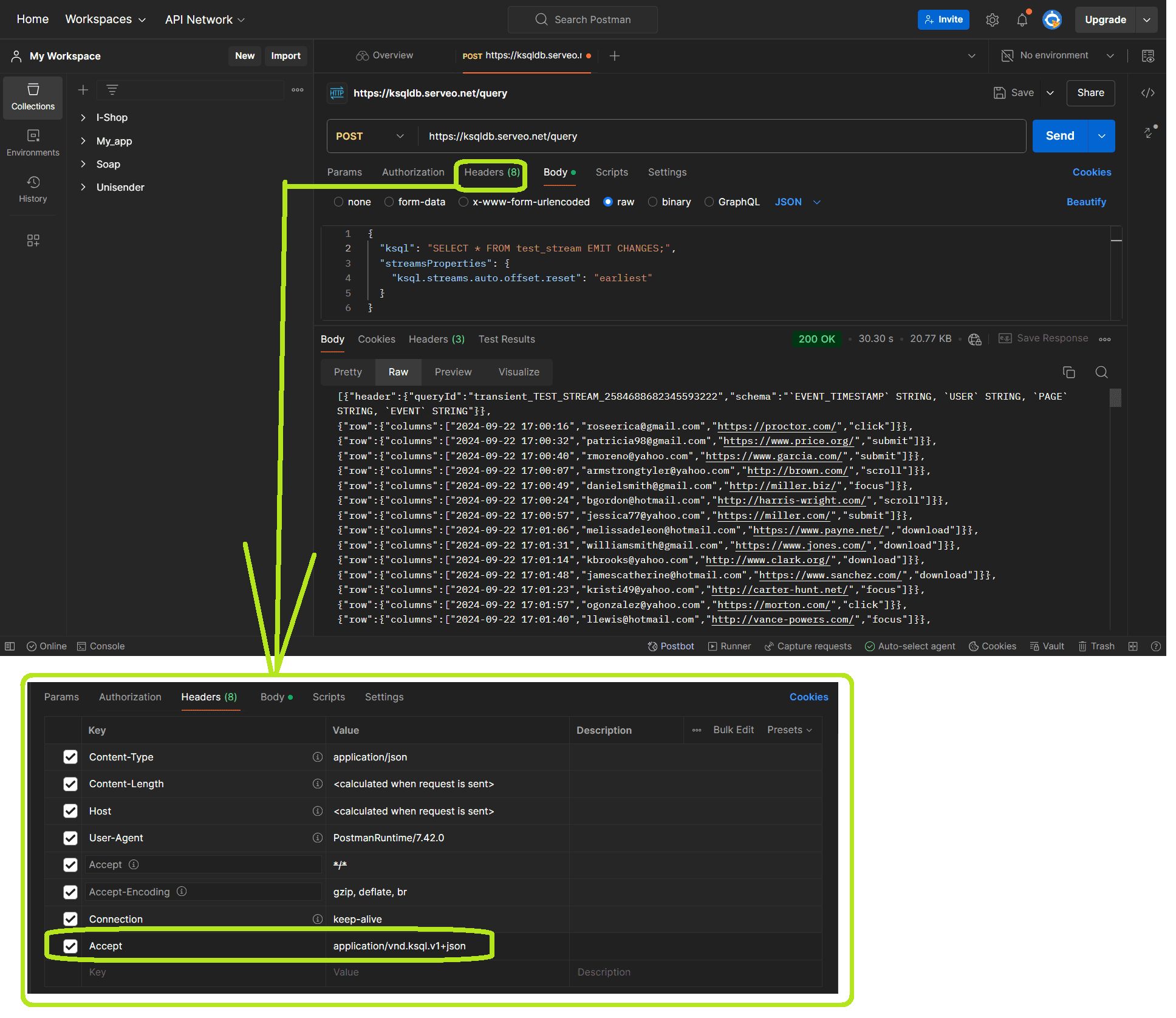
После этого можно обращаться к конечным точкам REST API сервера ksqlDB в облачной службе Postman. Примечательно, что эти конечные точки доступны только при использовании HTTP 2. Сперва посмотрим просто опубликованные сообщения, выполнив обращение к ресурсу /query серверного приложения ksqlDB. Ресурс /query позволяет передавать выходные результаты выполнения SQL-оператора SELECT. Ответ передается до тех пор, пока LIMIT не достигнет указанное в операторе значение или клиент не закроет соединение. Сам SQL-запрос передается как тело HTTP-запроса в виде JSON-объекта в кодировке UTF-8. Кроме тела HTTP-запроса методом POST нужно еще настроить Accept-заголовок, указав тип данных, который сможет принимать клиент от сервера. В данном случае в этом ключе надо указать значение application/vnd.ksql.v1+json. Это означает, что клиент ожидает получить ответ от сервера в формате JSON, который соответствует 1-ой версии API ksqlDB.
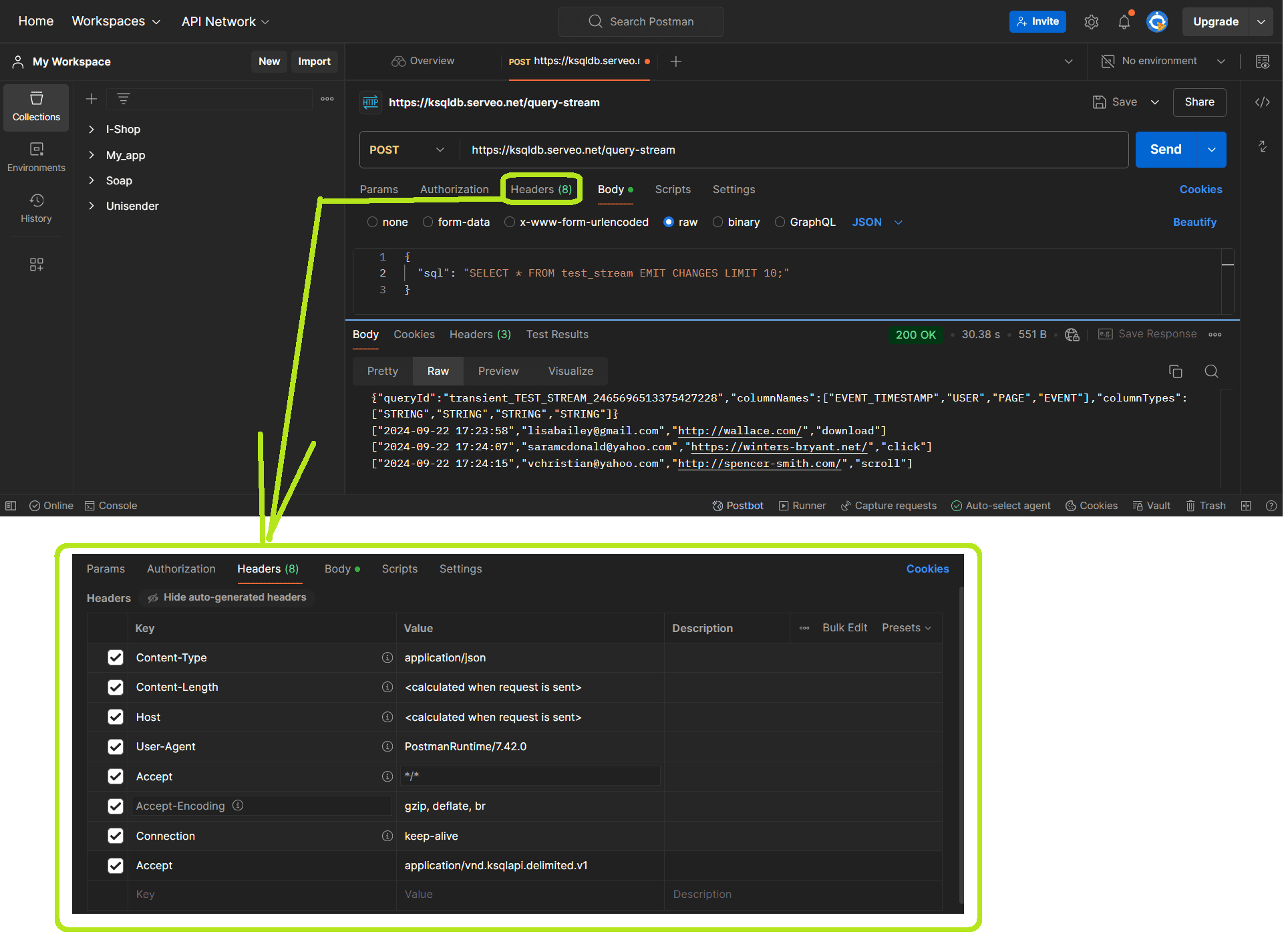
Помимо ресурса /query в ksqlDB есть ресурс /query-stream. Эта конечная точка чаще используется для выполнения потоковых запросов, которые возвращают данные в режиме реального времени, когда важно получать непрерывный поток данных по мере их появления. Хотя /query тоже позволяет получить постоянно обновляемые результаты с помощью EMIT CHANGES, обычно этот ресурс используют для фиксированного опроса таблицы.
Запрос к /query-stream выдает ответы с двумя возможными типами контента: application/json и application/vnd.ksqlapi.delimited.v1 (по умолчанию). Если задать заголовок HTTP-запроса Accept равным application/vnd.ksqlapi.delimited.v1, то результаты будут возвращаться как объект JSON, за которым следует ноль или более массивов, разделенных символами новой строки. Такой вывод легко анализируется и не требуют потокового анализатора JSON на клиенте, если надо вывести промежуточные результаты.
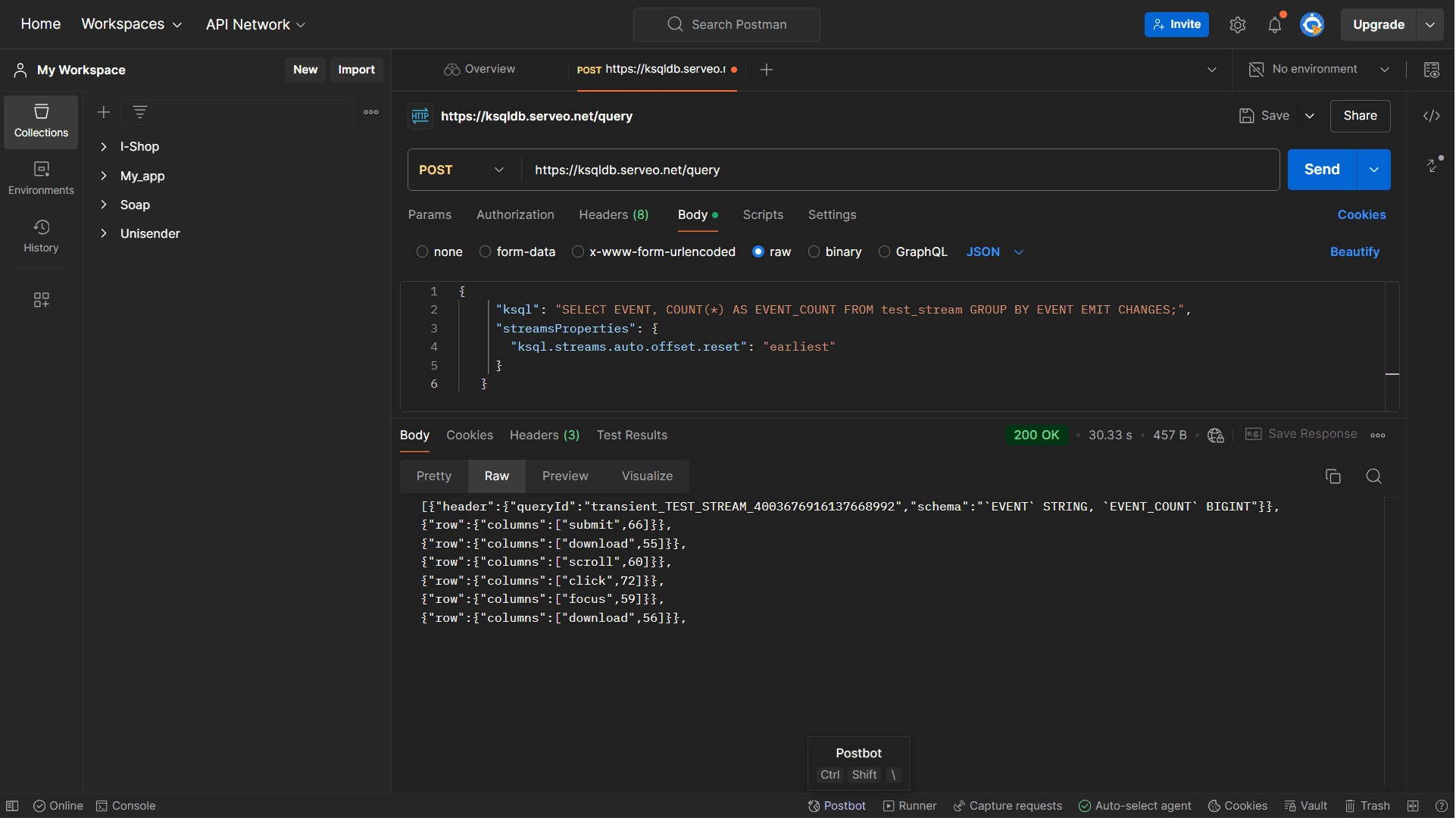
Наконец, посчитаем количество событий разных типов, отправив POST-запрос к ресурсу /query с телом
{
"ksql": "SELECT EVENT, COUNT(*) AS EVENT_COUNT FROM test_stream GROUP BY EVENT EMIT CHANGES;",
"streamsProperties": {
"ksql.streams.auto.offset.reset": "earliest"
}
}
Параметр streamsProperties с настройкой «ksql.streams.auto.offset.reset»: «earliest» указывает, что ksqlDB должна начать считывание данных с самого начала потока, т.е. с первого доступного сообщения.
Если отправить этот же запрос к ресурсу /query-stream, вывод будет более лаконичным и удобным для последующей обработки, о которой я расскажу в другой раз.
Научитесь администрированию и эксплуатации Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
Источники

