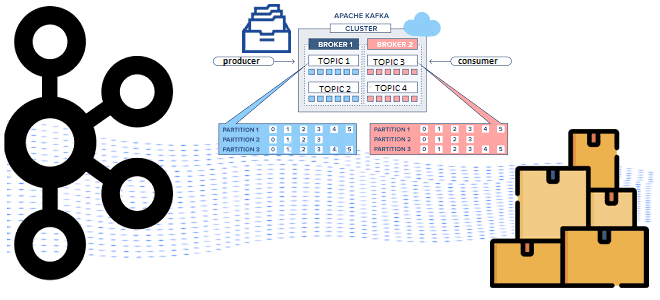
Какие конфигурации настроить на продюсере для эффективной публикации сообщений в Apache Kafka: упаковка записей в пакеты, взаимодействие с брокерами и метрики мониторинга этих процессов. Пакетирование сообщений при их публикации в Kafka и мониторинг этого процесса Хотя Apache Kafka поддерживает потоковую парадигму обработки информации, она активно использует пакетные технологии. В частности,...
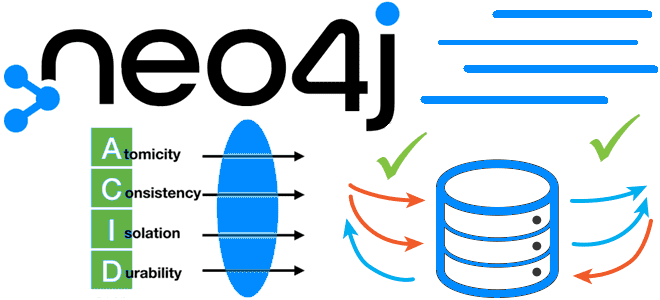
Как сделать крупное обновление, вставку или удаление данных в Neo4j без OOM-ошибки и APOC-процедур при выполнении транзакции с параллельным выполнением подзапросов: функция CICT, ее возможности, ограничения и отличия от конструкции CALL IN TRANSACTIONS. Подзапросы в транзакциях Neo4j: CIT-запросы Cypher vs процедуры APOC Параллельная обработка данных быстрее последовательной. Поэтому многие фреймворки...

Как решать задачи машинного обучения в Greenplum с агентом gpMLBot и расширением PostgresML: возможности, ограничения и примеры. Что такое gpMLBot: Greenplum Automated Machine Learning Agent Чтобы использовать Greenplum как хранилище данных в задачах машинного обучения, в этой БД поддерживаются соответствующие механизмы. Одним из них является библиотека Apache MADlib, о которой...
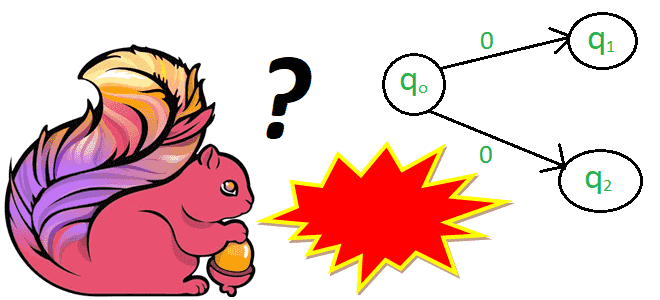
Что такое проблема недетерминированного поведения, почему она так важна в потоковой обработке данных и как Apache Flink борется с ней: недетерминированные и динамические функции, а также changelog stateful-операторов. Недетерминированные функции в Apache Flink В потоковой обработке данных, на которую ориентирован Apache Flink, все завязано на отметку времени события (timestamp). Однако,...
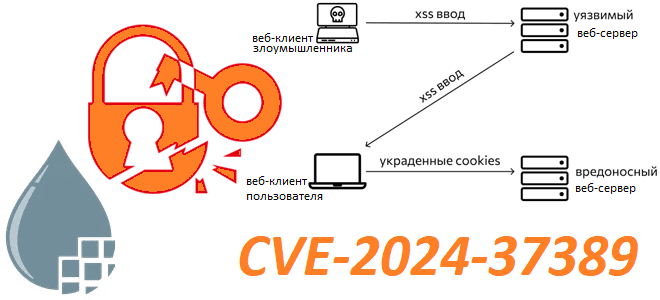
Как уязвимость CVE-2024-37389 может привести к выполнению произвольного кода в Apache NiFi: контекст параметров и межсайтовый скриптинг в веб-приложении для визуального проектирования конвейера обработки данных. Параметры свойств и их контекст в Apache NiFi 8 июля 2024 года в мажорном релизе Apache NiFi обнаружена уязвимость средней степени серьезности, связанная с неправильной...
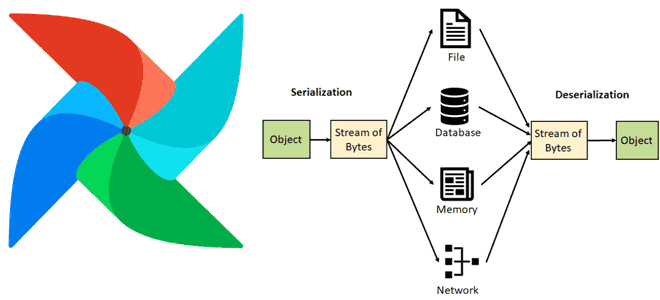
Как Apache AirFlow сериализует и десериализует данные, зачем с версии 2 включена обязательная сериализация DAG в JSON, почему для пользовательской сериализации рекомендуются словари или примитивы и что поможет сократить нагрузку на базу данных метаданных через настройку параметров сериализации в конфигурационном файле фреймворка. Сериализация данных в Apache AirFlow Чтобы сохранить данные...
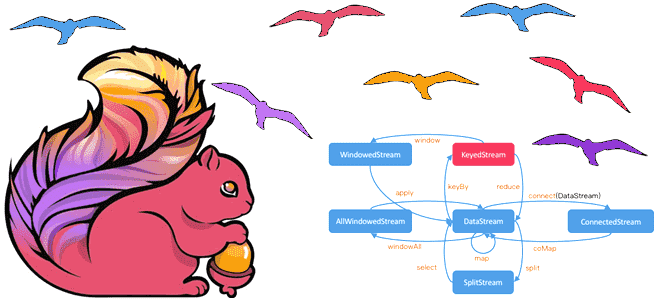
Чем DataSet API отличается от DataStream, зачем переходить с наборов на потоки данных в Apache Flink и как это сделать: эквивалентные и неподдерживаемые методы преобразования данных. Разница между DataStream и DataSet API Исторически в Apache Flink было 3 высокоуровневых API: DataStream/DataSet, Table и SQL. О возможностях и ограничениях каждого из...
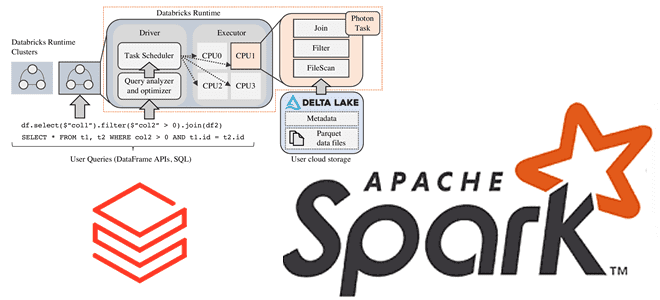
Зачем Databricks выпустила новый движок выполнения запросов Spark SQL для ML-приложений, как он работает и где его настроить: возможности и ограничения Photon Engine. Преимущества Photon Engine для ML-нагрузок Spark-приложений Чтобы сделать Apache Apark еще быстрее, разработчики Databricks выпустили новый движок выполнения запросов - Photon Engine. Это высокопроизводительный механизм запросов, который...
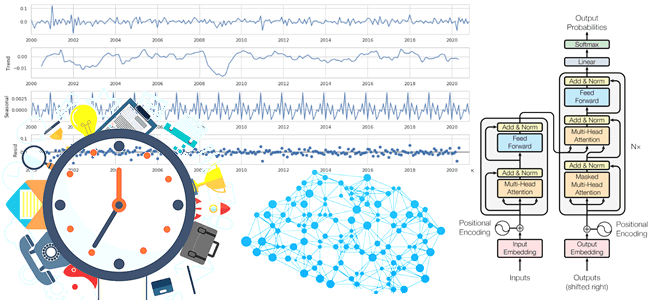
Почему генеративный ИИ хорошо подходит для прогнозирования временных рядов, как архитектура трансформеров учитывает влияние внешних переменных и сезонных факторов на измерения, и какие нейросетевые модели можно попробовать для этих задач. Проблемы прогнозирования временных рядов и их нейросетевые решения Прогнозирование временных рядов всегда было востребованной задачей в различных отраслях бизнеса. Временной...

24 августа вышел новый релиз Apache AirFlow. Знакомимся с новинками версии 2.10: гибкая настройка исполнителей для всей среды, конкретного DAG и отдельных задач, а также динамическое планирование набора данных и улучшения GUI. Гибкая настройка исполнителей Одной из самых главных новинок Apache AirFlow 2.10 стала конфигурация гибридного исполнения, позволяющая использовать несколько...