 758
758 
Содержание
24 сентября вышел очередной релиз Apache Spark. Он не содержит новых фичей, но зато в нем есть несколько полезных оптимизаций и исправлений безопасности. Читайте далее о самом главном из них, связанном с утечкой токена делегирования Hadoop.
Зачем нужны токены делегирования Hadoop в Spark и как они работают
В выпуске Apache Spark 3.5.3 исправлена утечка токена делегирования Hadoop, если tokenRenewalInterval не установлен. Эта ошибка имеет высокий приоритет. Она означает, что если tokenRenewalInterval не установлен, HadoopFSDelegationTokenProvider#getTokenRenewalInterval извлечет некоторые токены и обновит их, чтобы получить значение интервала. Эти токены не вызывают отмены, т.е. метода cancel(). В результате этого большое количество существующих токенов на HDFS не очищается своевременно, что создает дополнительную нагрузку на сервер HDFS.
Напомним, для аутентификации в HDFS с поддержкой Kerberos можно выполнить аутентификацию с помощью токена предоставления билета (Ticket Granting Token, TGT) или с помощью принципала и keytab. TGT-аутентификация рекомендуется для кратковременно работающих приложений. Для долговременно работающих приложений лучше подойдет использование принципала и keytab. В этом случае вход Kerberos периодически обновляется с помощью принципала и keytab для генерации делегированных токенов для связи с HDFS.
Токены делегирования (delegation tokens) в Hadoop предоставляют механизм для безопасного делегирования полномочий между различными компонентами распределённой системы. Они позволяют аутентифицированному пользователю временно передавать свои права доступа другому процессу или пользователю. Это особенно полезно для выполнения задач в кластере, где задания могут перемещаться между различными узлами и задачами.
Токен делегирования — это секретный ключ, который используется совместно с HDFS NameNode. Его можно использовать для выдачи себя за пользователя для выполнения задания. Хотя эти токены можно продлевать, новые токены могут быть получены только клиентами, прошедшими аутентификацию на NameNode с использованием учетных данных Kerberos. По умолчанию токены делегирования действительны в течение дня.
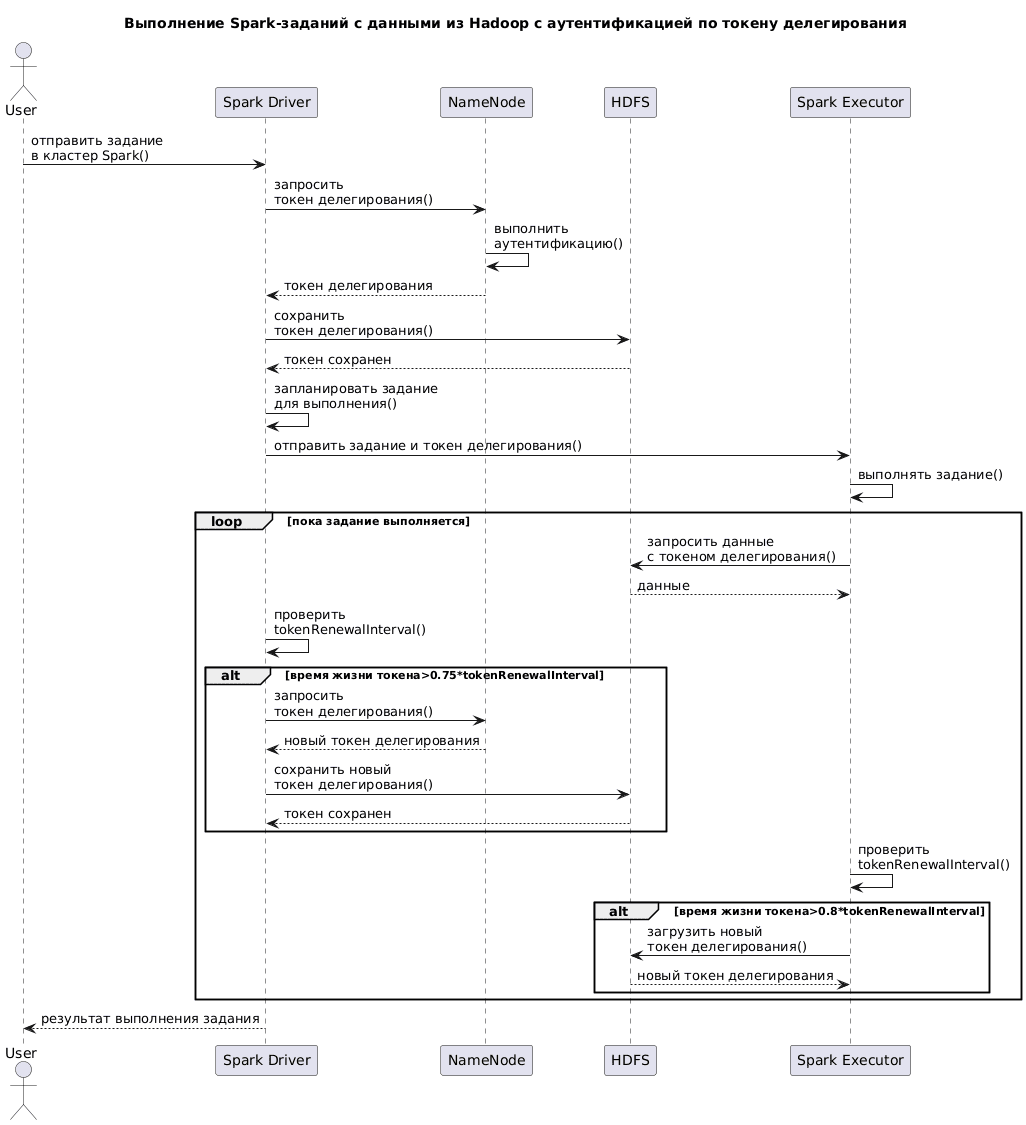
Поскольку Spark-приложения часто взаимодействуют с Hadoop для выполнения вычислений на данных, хранящихся в HDFS, они могут использовать эти токены делегирования. Когда Spark запускает задание в кластере Hadoop, ему необходим доступ к ресурсам HDFS и другим сервисам Hadoop. Spark должен аутентифицироваться и авторизироваться для выполнения этих операций. Для этого используются токены делегирования. При запуске задания Spark получает токены делегирования от Hadoop. Это может быть выполнено с помощью клиента Hadoop, который запрашивает токены у Kerberos или другого механизма аутентификации.
Полученные токены включаются в конфигурацию Spark-задания и передаются на все узлы, где будут выполняться задачи Spark. Это позволяет каждому узлу аутентифицироваться в HDFS и других сервисах от имени первоначального пользователя, обеспечивая безопасный доступ к данным и ресурсам. Как уже было отмечено, токены делегирования имеют ограниченный срок действия. Если задание Spark выполняется долго, дольше дня, нужно обновлять токены. Это делается автоматически: драйвер Spark по умолчанию обновляет токен делегирования один раз в день до завершения задания или максимум в течение семи дней. Драйвер Spark получает новый токен делегирования от NameNode с помощью keytab и записывает его в HDFS. Затем он запускает поток для проверки интервала обновления токена делегирования.
Если время жизни токена достигает 75% интервала исходного токена, драйвер восстанавливает новый токен делегирования и перезаписывает его в HDFS. Исполнитель также запускает поток для проверки интервала токена делегирования. Если токен достигает 80% интервала исходного токена, исполнитель загружает и обновляет последний токен делегирования nextSuffix из HDFS.
Зачем отменять устаревшие токенов делегирования
Интервал обновления для токена делегирования контролируется параметром dfs.namenode.delegation.token.renew-interval в XML-файле конфигурации Hadoop hdfs-site.xml. По умолчанию он установлен на 86400000 миллисекунд, что равняется одному дню. Этот параметр можно менять по мере необходимости.
Потенциальные последствия от отсутствия отмены устаревших токенов делегирования, что было исправлено в Apache Spark 3.5.3, опасна следующим:
- утечка ресурсов — неотмененные токены продолжают существовать и занимают ресурсы, что может привести к исчерпанию возможностей HDFS по управлению токенами;
- повышенная нагрузка на сервер HDFS, что снижает производительность и увеличивает время отклика;
- небезопасно – много активных токенов это риск, т.к. они могут быть использованы злоумышленниками для доступа к данным.
Поэтому в Apache Spark 3.5.3 были внесены изменения, чтобы гарантировать, что все полученные токены делегирования корректно отменяются после использования. Теперь, если tokenRenewalInterval не указан, система корректно обрабатывает извлечение и обновление токенов, гарантируя, что все временные токены отменяются после получения информации об интервале обновления. Это предотвращает накопление неиспользуемых токенов и снижает нагрузку на сервер HDFS.
Узнайте больше про использование Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

