 1189
1189 
Содержание
В рамках продвижения нашего нового курса по графовым алгоритмам на больших данных, сегодня разберем, что такое Pregel, и как API этой платформы реализован в Apache Spark GraphX. Читайте далее, как из RDD вершин и ребер образуется триплет, а также какие механизмы отвечают за отказоустойчивость графовой аналитики больших данных.
Что такое Pregel: краткий ликбез
В прошлый раз мы рассмотрели основы графовой аналитике больших данных, а также разобрались с отличиями библиотек GraphX и GraphFrames в Apache Spark. Одной из основных концепций этих модулей обработки данных в соответствии с графовыми алгоритмами, является Pregel — одна из самых популярных реализаций вершинно-ориентированной обработки графов. Наименование этого подхода можно расшифровать как сокращение от словосочетания «Parallel Graph Google», а также оно происходит от названия реки в Калининграде, бывшем Кёнисберге, откуда пошла самая знаменитая транспортная задача на графах – построение маршрута по 7 мостам.
Ключевыми концепциями Pregel являются следующие [1]:
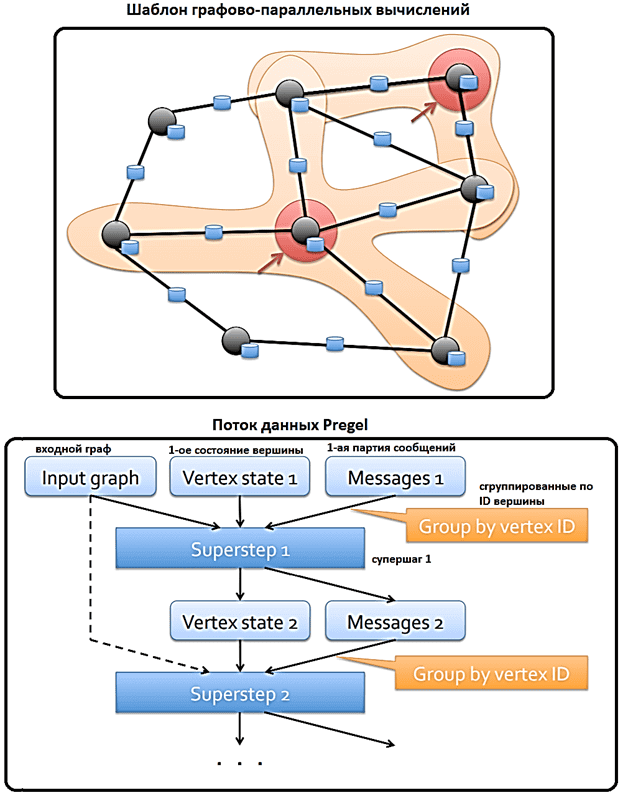
- задачи решаются итеративно, каждая итерация называется супершаг (supertstep);
- итерации останавливаются, когда достигается некоторый порог или максимальное количество итераций;
- на каждой итерации вершины общаются со своими соседями, накапливая сообщения от них;
- вершина графа может находиться в активном или неактивном состоянии. Активная вершина отправляет сообщения. Вершина становится неактивной, если ее значение не изменяется в конкретной итерации.
- В конце каждой итерации вершина применяет к накопленным сообщениям функцию уменьшения, чтобы вычислить новое значение. Если значение изменяется, оно распространяется на соседние вершины на следующем супершаге.
Разумеется, Apache Spark GraphX – это не единственная реализация графовой парадигмы Pregel. К этому же стеку относится Google Pregel, на базе которой основан один из ключевых поисковых алгоритмов – ранжирование веб-страниц (PageRank), а также Apache Giraph, активно применяемый в Facebook для анализа данных этой соцсети. В частности, с Apache Giraph компания всего за 4 минуты обработала около триллиона ребер пользовательских графов, используя всего 200 узлов кластера. Чем именно отличается реализация Pregel API в Apache Spark GraphX, мы рассмотрим далее.
Особенности реализации Pregel API и примеры использования в Apache Spark GraphX
В отличие от первоначальной спецификации Pregel API и других реализаций, Spark GraphX позволяет передаваемым сообщениям получать доступ к атрибутам как исходных, так и конечных вершин. Также, реализация Pregel в Spark GraphX использует подход сокращения, то не дожидаясь, пока все сообщения будут получены каждой вершиной, чтобы начать вычисление ее нового значения. Вместо этого Spark частично вычисляет их для каждого раздела, в итоге объединяя с окончательным значением.
На высоком уровне оператор Pregel в Spark GraphX представляет собой абстракцию массового синхронного параллельного обмена сообщениями, ограниченную топологией графа. Оператор Pregel выполняет серию супершагов, в которых вершины получают сумму своих входящих сообщений с предыдущего супершага, вычисляют новое значение для свойства вершины, а затем отправляют сообщения соседним вершинам на следующем супершаге. В отличие от классического Pregel, сообщения вычисляются параллельно как функция триплета ребер, а вычисление сообщения имеет доступ как к исходным, так и к целевым атрибутам вершин. Вершины, не получившие сообщения, пропускаются в пределах супершага. Оператор Pregel завершает итерацию и возвращает окончательный граф, когда не осталось сообщений. Это позволяет реализовать дополнительную оптимизацию графовых алгоритмов в Apache Spark [2].
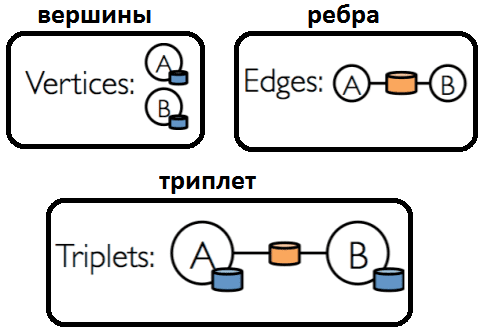
В Apache Spark основным примитивом обхода графа является триплет (triplet) из следующих компонент [3]:
- текущая вершина (source vertex);
- следующая вершина (destination vertex);
- ребро между ними (edge connecting) как путь перехода.
Также для Pregel следует указать расстояние между вершинами – обычно это делается с помощью определенной пользователем функции UDF для каждой вершины, чтобы обработать входящее сообщение и посчитать следующею вершину. Для слияния двух входящих сообщений также применяется UDF, которая должна быть коммутативной и ассоциативной. В случае Spark Scala, который является функциональным языком, эти UDF-функции будут представлены в виде лямбда-выражений [3].
Вычисление Pregel в GraphX применяется к триплету, при этом каждый раз вычисляется новый набор сообщений: var messages = GraphXUtils.mapReduceTriplets(g, sendMsg, mergeMsg).
Ключевыми особенностями реализации Pregel в Apache Spark GraphX и лучшими практиками его применения являются следующие [4]
- для неизменяемого состояния графа, состояний вершин и сообщений на каждой итерации создаются отдельные RDD;
- для выполнения каждого шага используется groupByKey;
- результирующие RDD вершин и сообщений кэшируются;
- для уменьшения связей выполняется оптимизация – совместное разделение входного графа и RDD состояния вершин.
Таким образом, главная вычислительная операция Big Data, MapReduce, в Pregel будет выглядеть следующим образом.
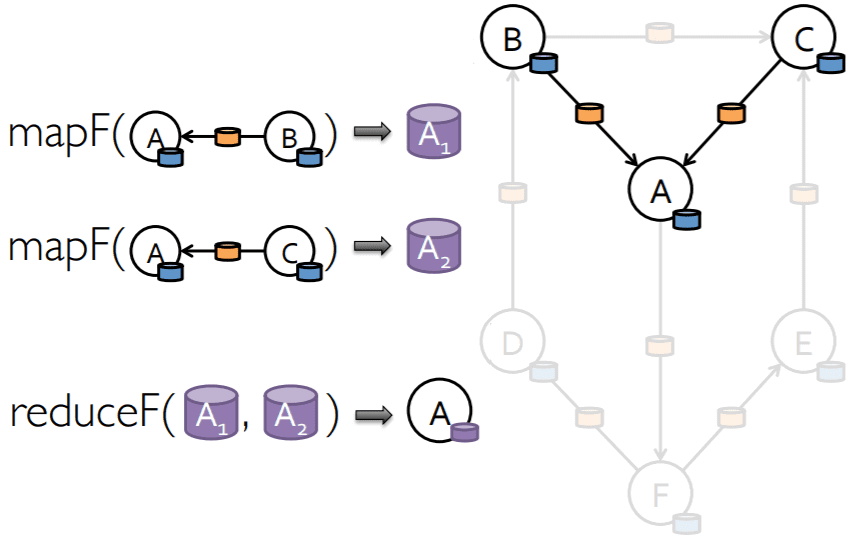
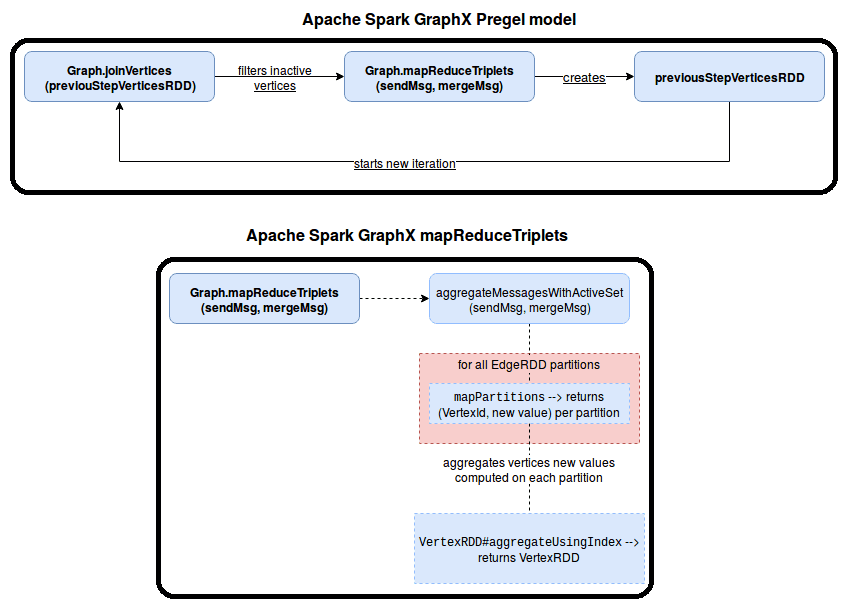
Рассмотрим пример выполнения программы Spark GraphX на основе Pregel, поток которой можно представить так [1]:
- итерация состоит из двух основных шагов – на первом вызывается метод joinVertices [U: ClassTag] (table: RDD [(VertexId, U)]) (mapFunc: (VertexId, VD, U) => VD), который выполняет шаг Map для каждой пары вершин, присутствующей в обоих RDD. Если вершина отсутствует в объединенном RDD, она сохраняет свое старое значение. Это необходимо, чтобы вычислить новое значение вершины с сообщениями, агрегированными в предыдущей итерации.
- Обмен сообщениями сложнее, чем вычисление новых значений в вершинах. Он делегирует вычисление aggregateMessagesWithActiveSet [A: ClassTag] (sendMsg: EdgeContext [VD, ED, A] => Unit, mergeMsg: (A, A) => A, tripletFields: TripletFields, activeSetOpt: Option [(VertexRDD [_]] , EdgeDirection)]).
- Параметр sendMsg: EdgeContext [VD, ED, A] => Unit определяет метод отправки сообщения соседним вершинам, объединяя функцию sendMsg с функцией, принимающей экземпляр EdgeContext в качестве параметра. Этот объект контекста имеет информацию о вычисленных триплетах: идентификатор источника и цели, а также атрибуты обеих вершин. Обернутая функция генерирует пару (VertexId, Message), а оболочка определяет логику связи и отправляет сообщение либо в исходную, либо в целевую вершину.
- Параметр mergeMsg: (A, A) => A – является шагом Reduce, отвечающиv за прием сообщений, сгенерированных для одной и той же вершины на уровне раздела, и вычисление одного значения. Это значительно снижает накладные расходы на связь, если данный раздел содержит много ребер одной конкретной вершины.
- Параметр tripletFields: TripletFields определяет поля для включения в EdgeContext, передаваемый в функцию-оболочку sendMsg.
- Параметр activeSetOpt: Option [(VertexRDD [_], EdgeDirection)]) фильтрует неактивные вершины, вместе с MessagesWithActiveSet вызывая метод org.apache.spark.graphx.impl.ReplicatedVertexView с withActiveSet, который отключает вершины, не определенные в RDD activeSetOpt.
Отказоустойчивость: контрольные точки и автовосстановление задач
В заключение отметим отказоустойчивость модуля GraphX, основанной на механизме контрольных точек Apache Spark. В случае сбоя при распределенной обработке данных Apache Spark может повторно вычислить отказавший раздел, а также сохранить моментальный снимок вычислений в качестве контрольной точки. Поддерживая RDD-представления вершин и ребер графа, GraphX хранит их в оптимизированных структурах данных, которые обеспечивают дополнительную функциональность, а сами вершины и ребра возвращаются как VertexRDD и EdgeRDD соответственно [2].
Чтобы уменьшить размер данных для хранения, RDD не содержит ссылок на своих родителей. Метод checkpoint() запускает операцию создания контрольной точки для графа и должен вызываться перед любой операцией, примененной к графу. Создание контрольной точки является блокирующей операцией: Apache Spark ничего не делает с графом, пока операция сохранения не завершится. Поэтому контрольная точка влияет на общее время выполнения Spark-программы. Поскольку граф представлен двумя RDD (для вершин и ребер), метод checkpoint() вызывает создание контрольных точек для обоих распределенных коллекций данных.
Контрольная точка в GraphX также имеет специальную реализацию для итеративных алгоритмов Pregel, под названием PeriodicGraphCheckpointer. Когда клиент вызывает метод обновления графа update(graph), элемент PeriodicGraphCheckpointer сначала помещает вершины и ребра в кэш. Если количество кэшированных графов больше 3, он удаляет лишние кэши. Позже экземпляр PeriodicGraphCheckpointer создает контрольную точку только тогда, когда количество последовательных вызовов обновления равно параметру checkpointInterval, определенному в его конструкторе. В этом случае метод checkpoint()проверяет самые последние данные и удаляют более старые. Таким образом, PeriodicGraphCheckpointer решает проблему длинных RDD, созданных после нескольких итераций. Уменьшая их размер до 0, это помогает избежать переполнения стека StackOverflowError.
Однако, GraphX обеспечивает отказоустойчивость не только с помощью механизма контрольных точек. Есть также автоматическое восстановление задач, которое выполняется дольше. Метод checkpoint() сохраняется граф до его материализации, поэтому позволяет быстрее восстанавливаться после сбоев. Во время автоматического восстановления движок повторно вычислит данные, необходимые для задачи, включая некорректно обработанный раздел. Причем, несмотря на то, что граф состоит из двух RDD (вершин и ребер), перерасчет выполняется не для всех сразу. Можно выбрать раздел для повторного вычисления, создав исключение и проанализировав полученную трассировку стека. Таким образом, Apache Spark знает, как вычисляются данные отказавшей задачи, и может перезапустить все вычисления, чтобы повторить попытку ее выполнения. Это поможет, если ошибка вызвана внешним фактором, например, временной недоступностью стороннего сервиса, предоставляющего исходные данные для графа [5].
Больше примеров использования Apache Spark для разработки распределенных приложений и графовой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://www.waitingforcode.com/graphx/iterative-algorithms-pregel-apache-spark-graphx/read
- https://spark.apache.org/docs/latest/graphx-programming-guide/
- https://habr.com/ru/post/415939/
- https://stanford.edu/~rezab/classes/cme323/S16/notes/Lecture16/Pregel_GraphX.pdf
- https://www.waitingforcode.com/graphx/graphX-fault-tolerance/read

