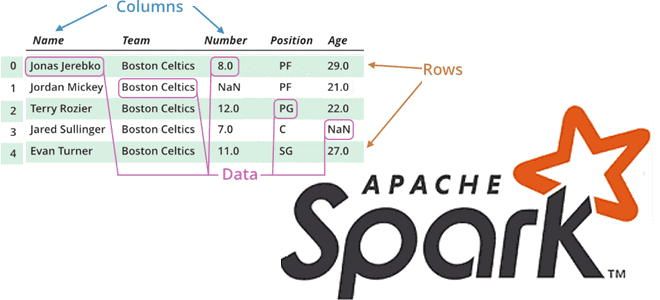
Продолжая разговор про вычислительные операции над датафреймами в Apache Spark, сегодня рассмотрим, какие преобразования (transformations) и действия (actions) чаще всего используются при разработке распределенных приложений и аналитике больших данных. Читайте далее, про виды столбцовых преобразования и отличия действия collect() от take(). Преобразования в Apache Spark: виды и особенности реализации Напомним,...
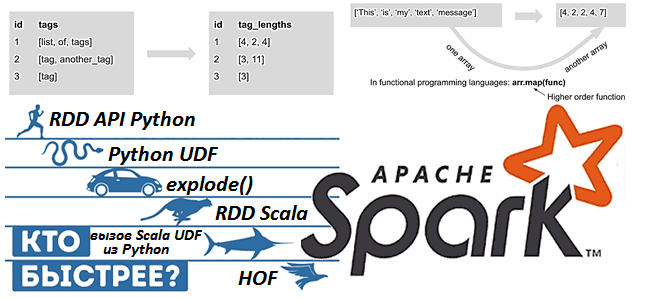
Apache Spark предоставляет для разработчика распределенных приложений множество возможностей, позволяя достигать одной целей разными способами. Чтобы проиллюстрировать это, сегодня рассмотрим бенчмаркинговое сравнение 9 методов обработки массивов в Spark 3.1, обращая внимание на их производительность и особенности использования. Также разберем важные для обучения разработчиков Spark темы про отличия преобразований от действий...

Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...

Apache Spark + AirFlow – известная каждому дата-инженеру комбинация технологий Big Data для запуска сложных конвейеров обработки данных. Но совместное использование этих фреймворков ограничено недостатками AirFlow, часть из которых можно обойти с помощью Apache Livy. Однако эксплуатация AirFlow менее удобна, чем Dagster. Поэтому сегодня рассмотрим, как этот альтернативный оркестратор данных...
Чтобы сделать обучение разработчиков Apache Spark, дата-аналитиков и инженеров Big Data еще более наглядным, сегодня рассмотрим проблему JOIN-соединений при неравномерном распределении данных по узлам кластера и способы ее решения. Читайте далее, как избавиться от перекосов и ускорить выполнение SQL-запросов в Spark-приложениях. Перекосы данных в Apache Spark: что это и чем...

Продолжая добавлять в наши практические курсы по Apache Kafka и Spark еще больше интересных примеров, сегодня рассмотрим, как с помощью этих технологий Big Data анализировать метаданные сетевых потоков в реальном времени. В этой статье мы приготовили для вас кейс по потоковой аналитики больших данных о сетевом трафике с помощью Apache...
Сегодня поговорим про обработку геопространственных данных с Apache Spark и рассмотрим, что такое Apache Sedona, как этот фреймворк связан с GeoSpark, какие форматы и структуры данных он поддерживает. Читайте далее про пространственные RDD, Spatial SQL-запросы и построение конвейеров обработки геоданных в облачных сервисах Amazon. Как обработать геопространственные данные в...

Сегодня рассмотрим инструмент, который облегчает практическое использование Apache Spark, позволяя дата-аналитику и разработчику распределенных приложений быстро писать и выполнять SQL-запросы в рамках удобного веб-редактора. Читайте далее, что такое Hue, как он связан со Spark SQL и Hive, а также причем здесь Livy. Что Hue и при чем здесь Apache Livy...
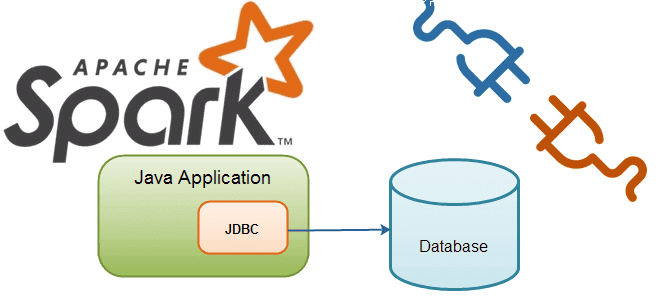
В этой статье рассмотрим особенности подключения Apache Spark к внешним СУБД как к источникам данных для аналитики Big Data средствами SQL-модуля этого фреймворка. Читайте далее о том, что такое JDBC-драйвер, чем источник данных JDBC отличается от сервера Spark SQL JDBC, при чем здесь RPC-фреймворк и язык описания интерфейсов Thrift, а...

Сегодня рассмотрим Apache Spark с точки зрения Data Science специалиста: поговорим про сходства и отличия библиотек машинного обучения в этом фреймворке. Также ответим на вопрос «Spark ML vs MLLib», разберем, зачем Data Scientist’у и аналитику больших данных нужны курсы по Apache Spark, а в заключение отметим наиболее важные улучшения библиотеки...