 576
576 
Содержание
Apache Spark предоставляет для разработчика распределенных приложений множество возможностей, позволяя достигать одной целей разными способами. Чтобы проиллюстрировать это, сегодня рассмотрим бенчмаркинговое сравнение 9 методов обработки массивов в Spark 3.1, обращая внимание на их производительность и особенности использования. Также разберем важные для обучения разработчиков Spark темы про отличия преобразований от действий и оптимизацию отложенных вычислений.
Преобразования и действия: под капотом вычислений Apache Spark
Прежде чем измерять производительность методов обработки массивов в Apache Spark, следует вспомнить особенности выполнения преобразований над данными в этой фреймворке. В частности, оптимизатор Spark может упростить план запроса так, что фактическое преобразование, производительность которого планируется оценить, будет пропущено, т.к. оно не требуется для определения окончательного результата [1]. Например, в DataFrame можно вызвать 2 типа операций: преобразования (transformations) и действия (actions). Преобразования являются отложенными (ленивыми, lazy): они не запускают вычисления при их вызове, а просто создают план запроса для последующего выполнения в случае необходимости. При этом сами данные все еще находятся в хранилище и ожидают обработки, которая фактически произойдет после материализации запроса и вызове какого-либо действия. После вызова действия, которое обычно является функцией, запрашивающей вывод, Spark запускает вычисление из нескольких шагов [2]:
- план запроса оптимизируется оптимизатором Spark;
- создается физический план;
- физический план запроса компилируется в RDD DAG (направленный ациклический граф, Directed Acyclic Graph);
- RDD DAG делится на этапы (stages) и задачи (tasks), которые выполняются в Spark-кластере.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
16 марта, 2026
Продолжительность
16 ак.часов
Стоимость обучения
48 000
Поэтому, чтобы убедиться, что все преобразования действительно выполнены, лучше вызвать действие write() и сохранить результат вывода во внешнее хранилище. Но это увеличит время отладки из-за процесса записи. Последний релиз Apache Spark 3.0, о котором мы рассказывали здесь, упрощает подобное тестирование благодаря встроенным источникам данных или noop функциям в пакетном и потоковом режимах. В частности, при назначении нового источника данных в пакетном режиме материализация набора данных выполняется без дополнительных накладных расходов, связанных с действиями и преобразованием значений строк в другие типы. Это полезно при тестировании производительности и кэшировании. В случае потоковой передачи функция no-op позволяет расширить источник данных для поддержки приемника [3]. Таким образом, начиная с версии фреймворка 3.0, можно указать noop как формат записи итогового датафрейма df.format(«noop»), который материализует запрос и выполнит все преобразования, но никуда не запишет результат.
Подход к бенчмаркингу: что будем сравнивать и на каких данных
Бенчмаркинговое сравнение, подробно описанное в источнике [1], проводилось в следующей среде:
- Apache Spark1.1 (выпуск марта 2021 года) на платформе Databricks со средой выполнения 8.0;
- кластер на 3 рабочих узла m5d.2xlarge (всего 24 ядра);
- входной набор данных, в каждой строке которого есть массив слов, хранится в объектном хранилище AWS S3 в файле формата Apache Parquet и имеет 1047 385 835 строк (чуть более одного миллиарда строк);
- сравнивается производительность выполнения запроса на добавление к набору данных нового столбца (массива), значения которого соответствуют длине слов в исходном массиве.
Сравнивалась производительность следующих методов обработки массивов в Apache Spark [1]:
- функции высшего порядка (HOF, Higher-Order Functions) – преобразования столбцов для сложных типов данных, таких как массивы;
- пользовательские функции Python (UDF, User Defined Function), которые позволяют расширить API DataFrame с помощью простого интерфейса и реализовать любое настраиваемое преобразование. Однако Spark не может сразу преобразовать в инструкции JVM Python-код из UDF, который должен выполняться локально. Чтобы передать данные из JVM worker’у Python они преобразуются в байты и передаются по сети, что не очень эффективно и требует довольно большого объема памяти.
- UDF с использованием API библиотеки Pandas, что подходит для обработки массивов, передавая данные из JVM в кластере Spark на рабочий узел Python в in-memory формате Apache Arrow, что более эффективно чем в предыдущем способе. Также Pandas UDF может использовать векторизованное выполнение на стороне Python, что полезно при численных вычислениях векторизованных операций, которые поддерживаются библиотеками NumPy или SciPy.
- Scala UDF, чтобы избежать передачи данных в Python, и выполнять преобразования в JVM. Но в этом случае остаются некоторые накладные расходы на преобразование данных из внутреннего формата в объекты Java. Для собственных преобразований Apache Spark использует внутренний формат данных, генерируя эффективный Java-код во время выполнения. С UDF-кодом Spark сперва преобразует данные в объекты Java, а затем выполняет пользовательские функции, после чего снова преобразует данные во внутренний формат.
- вызов Scala UDF из Python, что позволяет разработчику написать Spark-приложение на Python, а в Scala реализовать только UDF, чтобы сохранить выполнение внутри JVM и ускорить пользовательские преобразования. Файл Scala компилируется с использованием sbt в jar-файл, который загружается в кластер и может использоваться внутри приложения PySpark.
- Разнесение массива с помощью функции sql.functions.explode(col), которая возвращает новую строку для каждого элемента в исходном массиве, используя имя столбца по умолчанию col для элементов в массиве [4]. Так можно получить доступ к каждому элементу массива отдельно, но в DataFrame станет строк, чем было сначала. Вычислив длину каждого элемента, можно сгруппировать эти результаты в массивы и снова уменьшить DataFrame до исходного размера. Этот метод имеет 5 особенностей, одно из которых напрямую связано с производительностью, два — с корректностью результатов, одно — с формой окончательного вывода, а одно — с обработкой нулей. Подробнее об этом мы поговорим завтра.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
16 марта, 2026
Продолжительность
32 ак.часов
Стоимость обучения
96 000
- Разнесение массива с бакетированием источников. Напомним, бакетирование (Bucketing)– это метод оптимизации производительности задач в Apache Spark SQL и Hive, который разбивает данные на более управляемые части (сегменты или бакеты), чтобы ускорить последовательные чтения данных для последующих заданий. В один бакет попадают строчки таблицы с одинаковым значением хэш-функции, вычисленным по определенной колонке. Как это устроено, мы рассказывали здесь. Если разделить данные по ключу группировки, можно избежать перемешивания, т.е. сократить накладные расходы на передачу данных по сети.
- RDD API Python — низкоуровневый API, который сегодня считается морально устаревшим. Этот метод не рекомендуется использовать на практике – желательно применять вместо него API DataFrame или SQL. Однако, RDD как базовая структура данных Apache Spark по-прежнему используется внутри этого фреймворка. В частности, план запроса всегда компилируется в RDD DAG во время выполнения, но очень эффективно: сперва оптимизируется план запроса, а затем генерируется высокоэффективный Java-код, который работает с внутренним представлением данных в формате Tungsten. RDD в пользовательском коде не оптимизируются, и данные будут представлены как объекты Java с гораздо большим потреблением памяти по сравнению с Tungsten.
- RDD API Scala — аналогично предыдущему, но сразу в Scala, чтобы избежать трансляции из Python в JVM и обратно.
Результаты выполнения одного и того же запроса на одинаковом наборе данных с использованием вышеописанных методов представлены на диаграмме [1].
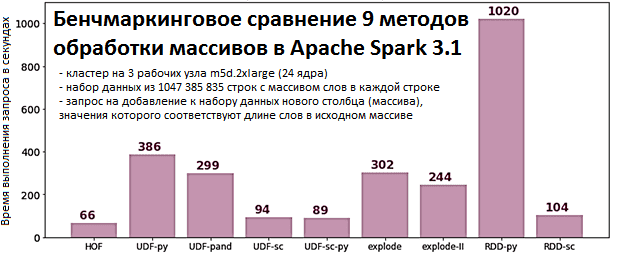
Таким образом, самым быстрым стал HOF-метод (66 секунд), использующий всю мощность встроенных возможностей последней версии фреймворка.
Освойте все эти и другие функции Apache Spark для разработки распределенных приложений и быстрой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
[elementor-template id=»13619″]
Источники
- https://towardsdatascience.com/performance-in-apache-spark-benchmark-9-different-techniques-955d3cc93266
- https://towardsdatascience.com/a-decent-guide-to-dataframes-in-spark-3-0-for-beginners-dcc2903345a5
- https://spark.apache.org/releases/spark-release-3-0-0/
- https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.sql.functions.explode/

