 1164
1164 
Содержание
Сегодня поговорим про обработку геопространственных данных с Apache Spark и рассмотрим, что такое Apache Sedona, как этот фреймворк связан с GeoSpark, какие форматы и структуры данных он поддерживает. Читайте далее про пространственные RDD, Spatial SQL-запросы и построение конвейеров обработки геоданных в облачных сервисах Amazon.
Как обработать геопространственные данные в Apache Spark: 3 способа
Ежедневно миллионы людей и компаний создают множество новых геопространственных данных – объектов, событий или явлений на поверхности Земли: карты погоды, социально-экономические данные, геотеги в соцсетях, GPS-данные от мобильных телефонов, частного и общественного транспорта. Сюда же относятся сигналы от устройств интернета вещей (IoT, Internet of Things), таких как датчики на перекрестках дорог для мониторинга параметров окружающей среды, дорожного движения и качества воздуха. Все эти и другие приложения геопространственной аналитики больших данных необходимо быстро обрабатывать с помощью современных технологий Big Data.
Геоданные – это не просто числовые значения координат, существует множество различных форматов представления геопространственных данных — WKB, GeoJSON, ESRI, а также следующие [1]:
- WKT (Well-Known Text) – широко используемый текстовый формат, в котором данные хранятся в удобочитаемом файле значений, разделенных табуляцией;
- Shapefile пространственной базы данных, который состоит из нескольких файлов – индексного и файла непространственных атрибутов;
- наконец, геопространственные данные обычно имеют разные формы (точки, многоугольники и траектории).
К примеру, геопространственные данные в виде строки можно представить таким образом [2]:
- GeoJSON: { “geometry”: { “type”: “Polygon”, “coordinates”: [ [ [100.0, 0.0], [101.0, 0.0],[101.0, 1.0],[100.0, 1.0],[100.0, 0.0]] ]} }
- WKT: POLYGON ((100.0 0.0, 101.0 0.0, 101.0 1.0, 100.0 1.0, 100.0 0.0)).
Но такое представление данных не очень удобно для обработки, в частности, для реализации пространственных операторов. Поэтому выделяют специальный геометрический тип данных, доступный не во всех системах, который позволяет использовать пространственные операторы: ограничение, пересечение и пр.
Apache Spark – отличный вычислительный фреймворк для пакетной и потоковой аналитики больших данных, но он не имеет встроенного типа геометрии и по умолчанию не позволяет обрабатывать геопространственные данные. Однако, есть несколько способов обойти это ограничение [2]:
- самостоятельно написать нужные классы для обработки геоданных, что будет долго и неэффективно;
- обернуть существующую базовую библиотеку, которая предоставляет необходимые функциональные возможности, например, GeoMesa через Java-библиотеку Spark JTS. Этот модуль предоставляет набор определяемых пользователем функций (UDF, User Defined Functions) и определяемых пользователем типов (UDT, User Defined Type) для выполнения SQL-запросов в Spark к геопространственным данным [3].
- Не изобретать велосипед, а воспользоваться готовым решением для быстрой обработки геопространственных данных в Apache Spark – GeoSpark, который сегодня называется Apache Sedona и находится в инкубаторе проектов Apache Software Foundation с июля 2020 года. Что именно представляет собой это решение, мы рассмотрим далее.
Что Apache Sedona (GeoSpark) и как это работает
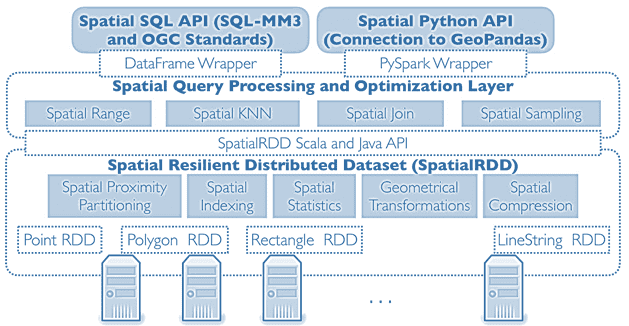
Apache Sedona (ранее GeoSpark) – это распределенный вычислительный фреймворк для масштабной обработки геопространственных данных, основанный на Apache Spark. Он дополняет базовую структуру данных Apache Spark RDD для размещения геопространственных данных в кластере. SpatialRDD состоит из разделов данных, распределенных по кластеру Spark и может быть создан с помощью преобразования RDD или загружен из файла, который хранится в постоянном хранилище. SpatialRDD предоставляет ряд API для чтения разнородных пространственных объектов из различных форматов данных.
Также GeoSpark позволяет пользователям обращаться к геоданным через готовые API пространственных SQL-запросов и RDD API. RDD API предоставляет набор интерфейсов на разных языках программирования (Scala, Java, Python и R). Интерфейсы Spatial SQL реализует стандарт SQL/MM Part 3, который широко используется во многих существующих пространственных базах данных, таких как PostGIS на базе СУБД PostgreSQL.
Sedona (GeoSpark) может считывать данные формата WKT, WKB, GeoJSON, Shapefile и NetCDF/HDF из различных внешних систем хранения, таких как локальный диск, Amazon S3 и распределенная файловая система Hadoop HDFS. Фреймворк преобразует их в пространственные RDD, которые могут содержать семь типов пространственных данных: Point, Multi-Point, Polygon, Multi-Polygon, Line String, Multi-Line String, GeometryCollection и Circle. Более того, пространственные объекты разных форм могут существовать в одном Spatial RDD, благодаря обобщению интерфейсов геометрических вычислений в Sedona.
Примечательно, что пространственные объекты в SpatialRDD не относятся к определенному типу геометрии, что позволяет смешивать их. Например, файл WKT может включать три типа пространственных объектов, таких как LineString, Polygon и MultiPolygon. Система может загружать данные во многих форматах с помощью набора файловых считывателей, например, WktReader и GeoJsonReader.
Поскольку Apache Sedona основана на Spark, этот фреймворк также позволяет работать с геоданными через SQL-запросы в API Spatial SQL GeoSpark, который включает 3 категории функций пространственного SQL [1]:
- конструкторы, например, создать столбец геометрического типа;
- предикаты, которые обычно используются в условиях WHERE, HAVING и прочих выражения, чтобы оценить, истинно или ложно пространственное условие;
- геометрические функции, которые выполняют геометрические операции с заданными входными данными, создавая геометрические формы или числовые значения, такие как площадь или периметр.
Наконец, благодаря тому, что Sedona базируется на Apache Spark, использовать этот фреймворк можно в облачном кластере Amazon EMR, предварительно настроив необходимые зависимости и установив последнюю версию PySpark. Таким образом, можно построить собственный Big Data конвейер аналитики геоданных, считывая их из локальных источников и/или объектного хранилища AWS S3 [4]. Как именно это сделать, мы рассмотрим завтра.
В заключение отметим, что Apache Sedona имеет удобное и особенно полезное для Data Science приложений расширение – GeoSparkViz. Это масштабная система геопространственной визуализации в оперативной памяти, которая обеспечивает встроенную поддержку общего картографического дизайна, расширяя GeoSpark для обработки крупномасштабных пространственных данных. Он может визуализировать пространственные RDD и SQL-запросы, генерируя изображения сверхвысокого разрешения [5].
Узнайте больше про практическое использование Apache Spark для разработки распределенных приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники
- https://towardsdatascience.com/geospark-stands-out-for-processing-geospatial-data-at-scale-548077270ec0
- https://medium.com/version-1/an-introduction-geospatial-processing-with-spark-d78dffd0ff1e
- https://www.geomesa.org/documentation/stable/user/spark/spark_jts/
- https://medium.com/@nilabjachowdhury/geospatial-data-pipeline-aws-emr-s3-postgis-rds-6a9204e808ab
- https://github.com/lzugis/GeoSpark

